第二名方案,CPMP 视角
当 Giba 和我加入团队时,@sggpls、@tony321 和 @krivoship 已经稳居前 10 名,而且距离比赛结束只剩下不到 10 天。在这种情况下很难增加价值,所以我决定专注于为他们正在融合的模型增加多样性。为此,我创建了自己的数据集,并借鉴了他们的一些数据。让我描述一下我采取的步骤。
数据清洗
数据与恶意软件数据集有点相似,带有时间戳的观察值,以及许多在测试集中存在但在训练集中不存在的特征值。我通过查看训练集与测试集的分布来筛选所有特征,包括原始特征和特征的频率编码。这是 card1 的一个例子。
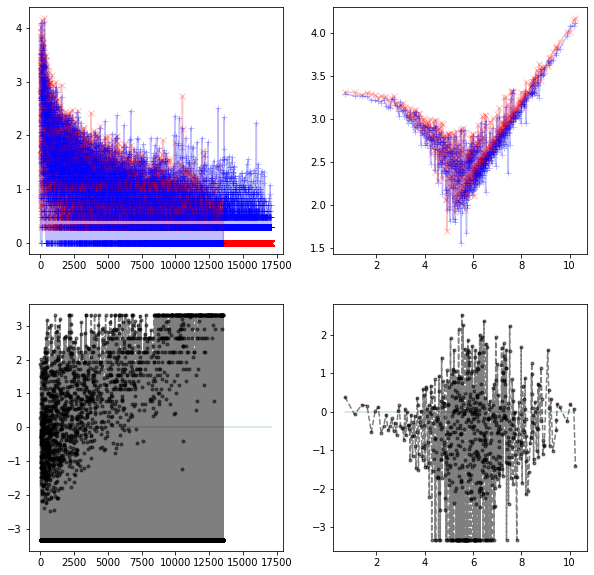
左列使用的是原始数据,右列是其特征编码。红色代表训练集,蓝色代表测试集。左侧行的 x 轴是 card1。左上角的 y 轴是频率。左上角显示了训练集(红色)和测试集(蓝色)中每个 card1 值的频率。左下角的 y 轴是经过对数转换的目标均值。0 是训练集的平均值。右列也是一样的,只是 card1 被替换为其频率的对数。
我们看到很多 card1 的值只出现在测试集中。如果我们直接使用它,会导致 Private LB 大幅下降。我们还看到 card1 的频率编码在训练集和测试集之间看起来更加平衡。对于这个特征,我丢弃了原始特征,保留了频率编码。
由于时间限制,我没有像在恶意软件比赛中那样合并数值。事后看来,我不确定这是否会有很大帮助。
交叉验证
时间序列的交叉验证总是很棘手。这是我最终采用的方法。我试图模拟训练集和测试集之间存在显著时间间隔这一事实,以及测试集可能距离训练集有几个月的时间。
我运行了这些折,使用从 0 开始的月份。| 表示训练/验证集的分割:
0 | 2 3 4 5 6
0 1 | 3 4 5 6
0 1 2 | 4 5 6
0 1 2 3 | 5 6这使得我为给定的模型类型训练了 4 个模型。然后我计算这些模型在相应验证数据上的 AUC 分数的平均值。我的队友也重用了这个方案或其变体来验证他们的模型。优点是我们有测试长期预测的折。
我使用这个 CV 来评估特征、评估 HPO(超参数优化)以及进行特征选择。对于提交,我尝试了两种方法。一种是根据 CV 运行推断树的数量。我只是对树的数量的对数进行了线性回归,并预测了完整训练集的值。我还尝试使用未打乱的 8 折 CV,并对测试集的所有折模型预测结果取平均。两种方法给出的 LB 分数相似。我可能应该同时使用这两种方法并融合结果,但我没有……
特征工程
我首先计算所有特征的频率编码,然后使用带有上述交叉验证的 LightGBM,通过置换重要性来选择特征,并做了一些修改:只有当置换某个特征没有改善 4 个模型中任何一个的预测时,我才保留该特征。这移除了一些特征。我重复了这个过程,使用置换重要性移除特征,直到特征列表不再缩小。通过这个方法,我在 Public LB 上得到了 0.942 分。
下一个层次是寻找用户 ID,这也是我组队的时候。我希望我的新队友们已经解决了用户 ID 的难题。他们确实解决了。他们实际上有许多不同的 uid。我选择了其中两个,定义如下:
data['uid1']` = (data.day - data.D1).astype(str) +'_' + \
data.P_emaildomain.astype(str)
data['uid2'] = (data.card1.astype(str) +'_' + \
data.addr1.astype(str) +'_' + \