#16 解决方案
大家好。比赛结束后我一直很忙,所以没能早点发布我的解决方案,但我还是想和大家分享我的做法。希望这还不算太晚!
我的方案是不同架构(Resnet34、Resnet50、EfficientNet-b4 和 EfficientNet-b5)、不同预处理方法(Circle+GaussianBlur 和 CircleToSquare+GaussianBlur)以及不同输入尺寸(224、380 和 456)的集成。所有模型通过加权平均进行融合(我手动调整了权重,这比使用 hyperopt 选择权重的效果更好)。我在一些模型中使用了 TTA(测试时增强),这稍微提高了分数(在使用 fastai 时,需要设置 scale=1.0 才能让 TTA 发挥良好作用)。
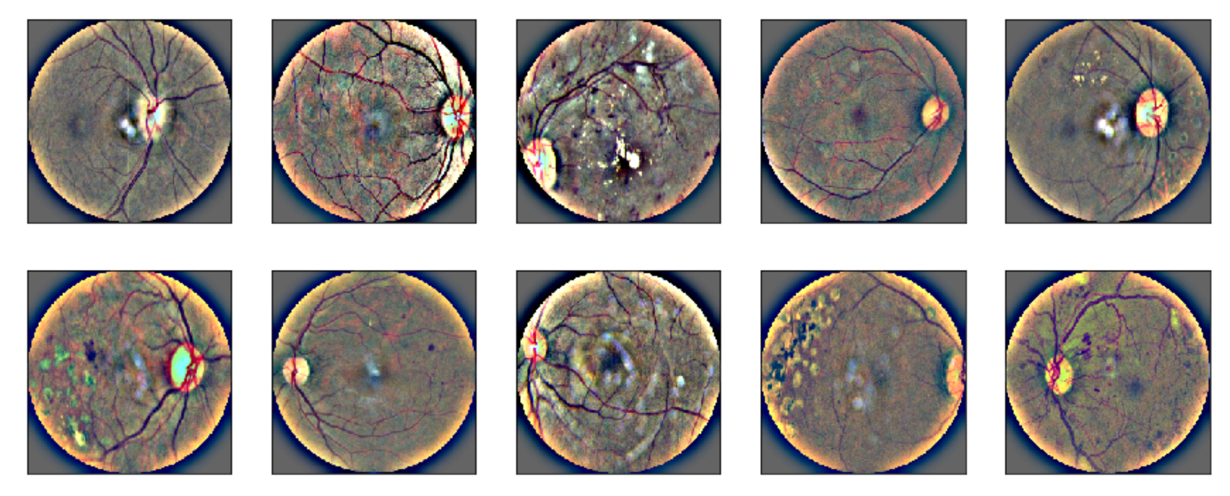
我解决方案的关键部分是预处理。起初我尝试同时减去中值模糊图像和高斯模糊图像,但我最终只保留了后者,因为我发现 CV(交叉验证)和 LB(排行榜)分数之间有更好的相关性。其目的是去除所有可能帮助算法识别不同类型图像的信息,以便更好地泛化。然而,减去高斯模糊图像似乎不足以去除所有原始图片信息,因为在眼睛边缘的颜色对于不同类型的图像仍然有些不同:
所以我的想法是在减去高斯模糊图像之前去除黑色部分。为此,我发现了 squircle 库,它有 3 种方法可以实现这一点。这是预处理后图像的样子:
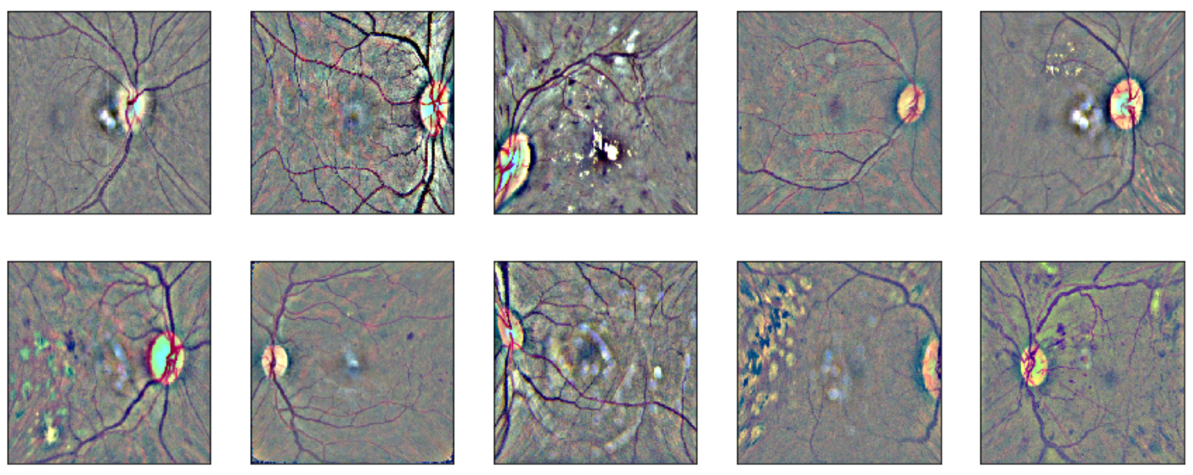
我最好的单一模型是基于这种 CircleToSquare+GaussianBlur 预处理的 EfficientNet-b5,输入尺寸为 380,并使用了以下增强参数:get_transforms(max_rotate=0, flip_vert=True, max_warp=0.0, max_zoom=0, max_lighting=0.35)。它在公共 LB 上得分为 0.814,在私人 LB 上得分为 0.927。
我也使用了伪标签,这对我有一点帮助,但帮助不大,因为我应用它的方式(使用阈值为 0.9 的分类模型)。我想如果我像顶尖团队描述的那样使用所有测试数据进行伪标签标注,我的模型表现会更好。至少我学到了新东西 ;)
好了,恭喜所有获胜者,感谢所有在讨论区分享观点以及分享优秀内核的人。特别感谢 @ratthachat 提供的许多预处理想法,以及 @hmendonca 分享的展示如何在 fastai 中应用 EfficientNet 的内核。
祝一切顺利!