在牛市让基金申赎预测"开挂"?一文读懂多源融合与注意力增强LSTM实践
团队背景
王俊松,来自重庆,目前于云南财大攻读硕士学位,主攻计算机视觉与机器学习。
黄浚珂,来自重庆,目前于南京大学就读,研究方向为金融工程与人工智能。
这次大赛,两位初高中同窗好友并肩作战,队名"晨曦"正是他们中学时期的小组名的延续,最终也不负期待斩获佳绩。与好兄弟并肩作战、思维碰撞的日子,已成为双方人生中重要的锚点,将一直激励他们不断前行。
在此,他们表示要特别感谢徐兴贵导师,在系统性解决项目能力上的培养;感恩父母对求学道路上的鼎力支持;也感谢赛方的专业与体贴,很高兴能和好兄弟一起参加这次比赛,祝蚂蚁集团和AFAC大赛越来越好
在上海市科学技术委员会、中国计算机学会(CCF)指导下,由蚂蚁集团、北京大学、复旦大学、香港大学等20余家金融科技企业与学术机构联合发起的AFAC2025金融智能创新大赛此前已圆满落幕。本次大赛不仅成为了技术的竞技场,更成为了一个生态丰富的"热带雨林",汇聚了背景各异的逐梦者。
大赛组委会也特地邀请了各赛题的优秀团队分享他们的解题思路和技术方案,希望给到更多逐梦者们一些启发,也欢迎大家来进行技术上的交流学习。
在金融市场波动加剧的当下,基金申购赎回行为的精准预测成为资管机构控制风险、优化产品管理的核心需求。AFAC2025金融智能创新大赛挑战组赛题一聚焦"基金产品长周期申购和赎回预测",要求基于20支基金历史数据,构建模型实现长周期申赎金额预测。我们团队以"多源特征融合+注意力增强LSTM"为核心思路,最终在初赛中取得第五名的成绩。技术探索永无止境,在此分享我们的方案细节,希望能与行业同仁共同交流进步。
赛题背景
基金申赎行为受多重因素交织影响——既与基金自身净值、规模相关,也受投资者情绪、市场指数、资金流动性(如发薪日)、节假日等外部因素驱动。赛题要求参赛者基于20支基金的历史数据(含申赎金额、净值等基础信息),构建模型预测未来长周期内的申购、赎回金额,核心目标是提升预测精度,同时保证模型在震荡市场中的稳定性与通用性。
数据案例解析
下面通过一个简化样本,帮助大家理解赛题核心任务与数据逻辑:
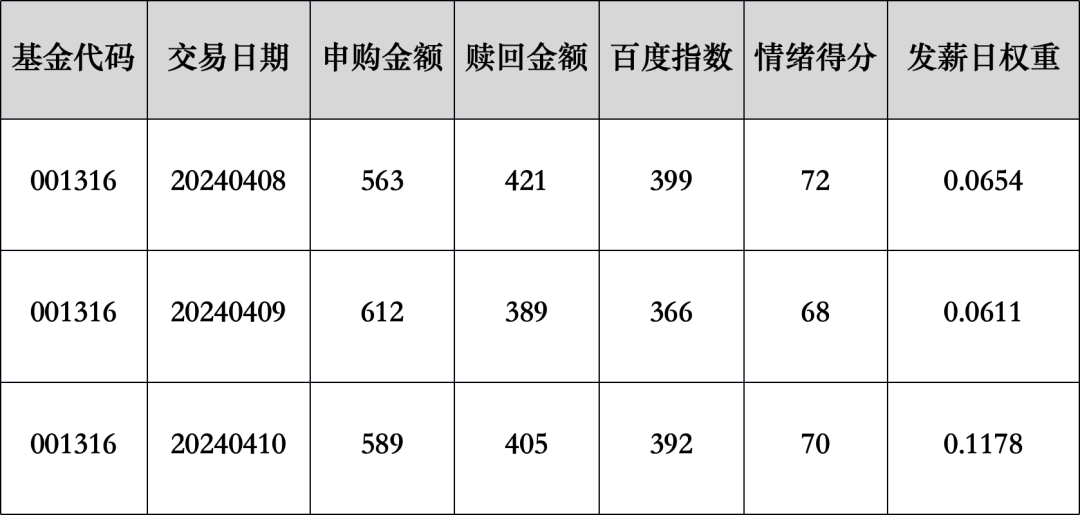
任务目标
基于上述多维度历史数据(含自主构建的情绪、发薪日等特征),预测该基金未来7天(如20240411-20240417)的每日申购、赎回金额。
评价指标
赛题采用加权平均绝对百分比误差(WMAPE)作为核心评价指标,兼顾申购、赎回两个预测目标,具体计算逻辑如下:
单只基金预测误差:
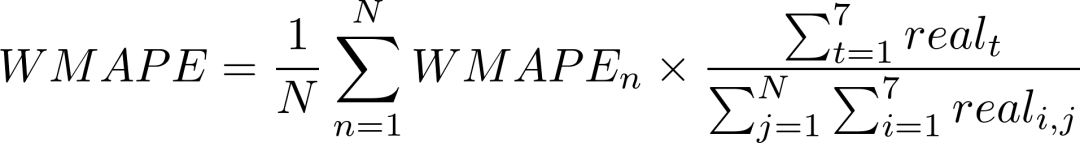
所有基金整体预测误差:
最终得分:
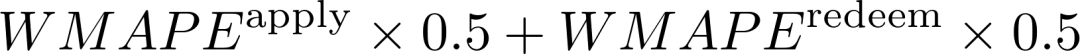
赛题核心难点
通过对数据与任务的分析,我们总结出三个关键挑战:
- 特征维度复杂:申赎行为受"基金自身-市场环境-投资者行为-资金流动性"多维度影响,单一特征难以覆盖全貌,需高效融合异构数据;
- 时序依赖显著:长周期预测需兼顾短期波动(如单日情绪突变)与长期趋势(如月度发薪资金流入),传统时序模型(如ARIMA)对非线性依赖建模能力不足;
- 场景差异明显:申购多受行情乐观、新发基金热度驱动,赎回则与市场恐慌、资金周转需求相关,混合建模易导致特征混淆,降低预测精度。
算法实现
1. 整体框架
针对赛题难点,我们设计了"数据采集与预处理→特征工程→模型构建→训练优化→推理部署"的端到端方案框架。核心思路是:以多源特征挖掘为基础,用注意力增强LSTM捕捉时序依赖,通过场景化建模与集成策略提升预测稳定性。
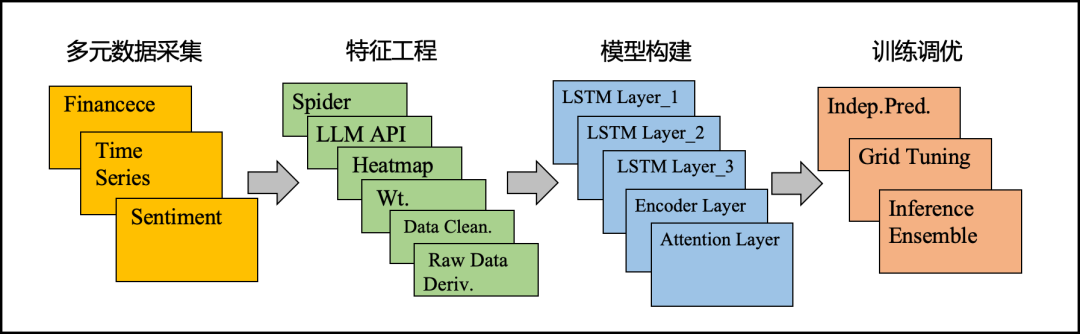
2. 特征工程
特征是预测精度的基石。我们摒弃传统盲目试错模式,通过大模型构造特征以及热力图快速验证,将特征迭代周期从天级压缩至小时级,核心设计包括四类关键特征:
(1)发薪日特征:量化资金可用性周期
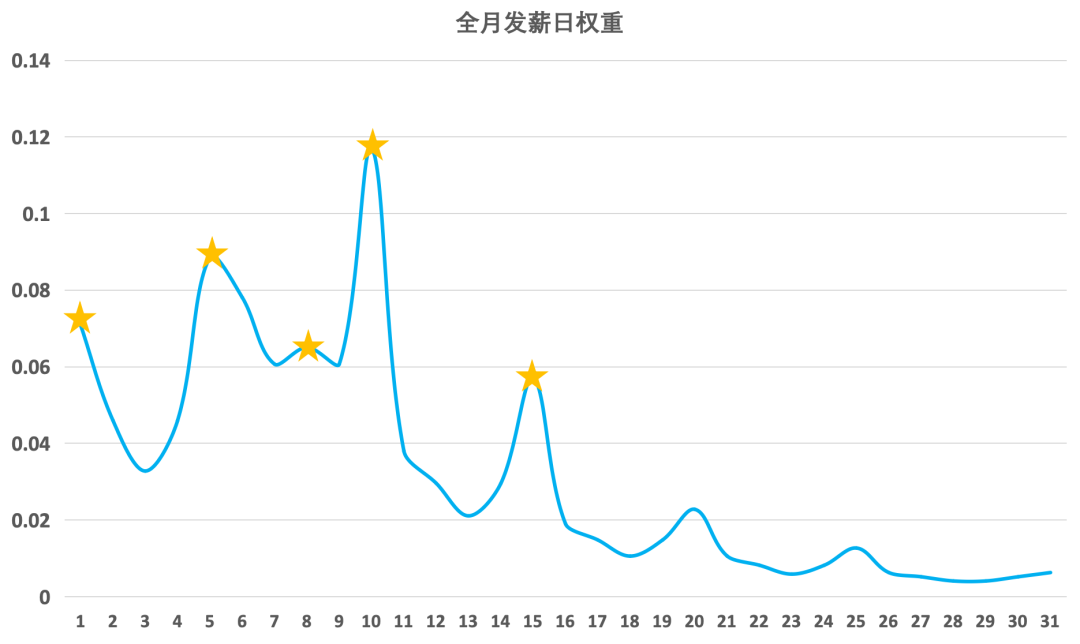
思路:中国投资者多在发薪后(1-5日、15日)增加申购,可将"发薪日"这一抽象概念转化为可量化特征。
实现:采用"多阶段权重分配法",通过大模型生成每日发薪概率:
- 基础权重:按每5日区间赋值(如6-10日为核心发薪期,权重30%);
- 凹型调整:强化区间边缘日期(如1-5日中,1日、5日权重提升20%);
- 人群强化:互联网大厂(5/8/10/15日发薪)权重+50%,国企(1/20/25日发薪)权重+30%(这类人群发薪后入市比例更高);
- 动态归一:每月权重总和=1,消除月份天数差异。
作用:我们构造的发薪日特征将抽象概念转化为可量化、可解释的日度数据,填补了资金可用性板块的空白,让模型能精准识别发薪后可能出现的申购高峰。
示例:5月份发薪日权重图
(2)投资者情绪特征:用户评论数据量化
思路:用户评论直接反映情绪(如"加仓"vs"割肉"),需将文本转化为数值特征。
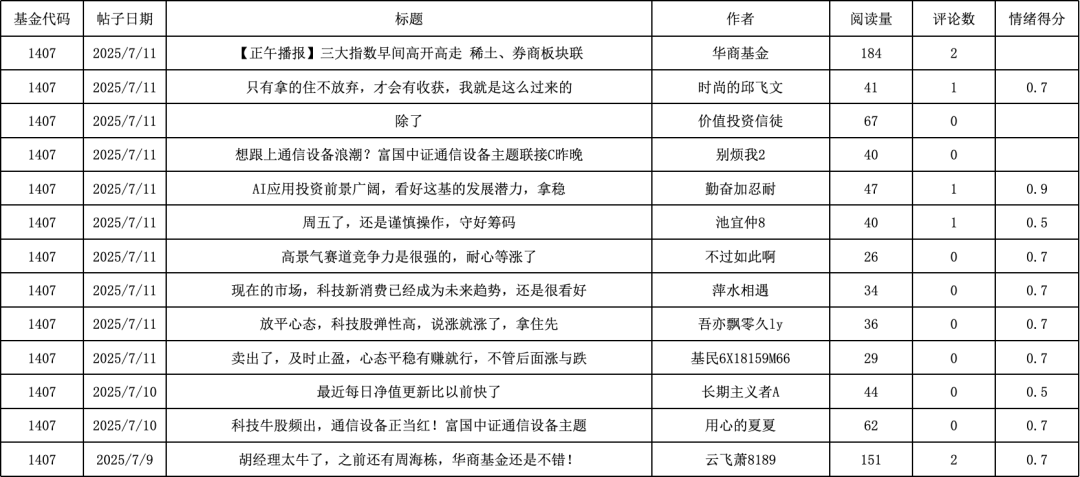
实现:爬取天天基金网评论,通过大模型API完成情绪量化:
- 单帖权重计算:避免高阅读量无效帖(如广告)干扰,公式如下:

其中,通过调整α与β平衡阅读量与互动率的影响。
- 情绪分类:大模型输出离散标签(0.1=极消极、0.3=消极、0.5=中立、0.7=积极、0.9=极积极);

示例图:大模型打分汇总结果案例
(3)星期/节假日特征:精准捕捉周期规律
星期特征:摒弃"周一=1、周日=7"的简单编码,计算过去一年每周各日申赎金额占比(如周三申购占比17.94%),直接量化"周三交易高峰";
节假日特征:通过大模型精准识别法定节假日与调休,生成"0=节假日、1=交易日"标志位,避免休市导致的申赎数据异常。
3. 模型设计
针对长时序建模以及抗干扰需求,我们最终选择LSTM+多头注意力混合架构。
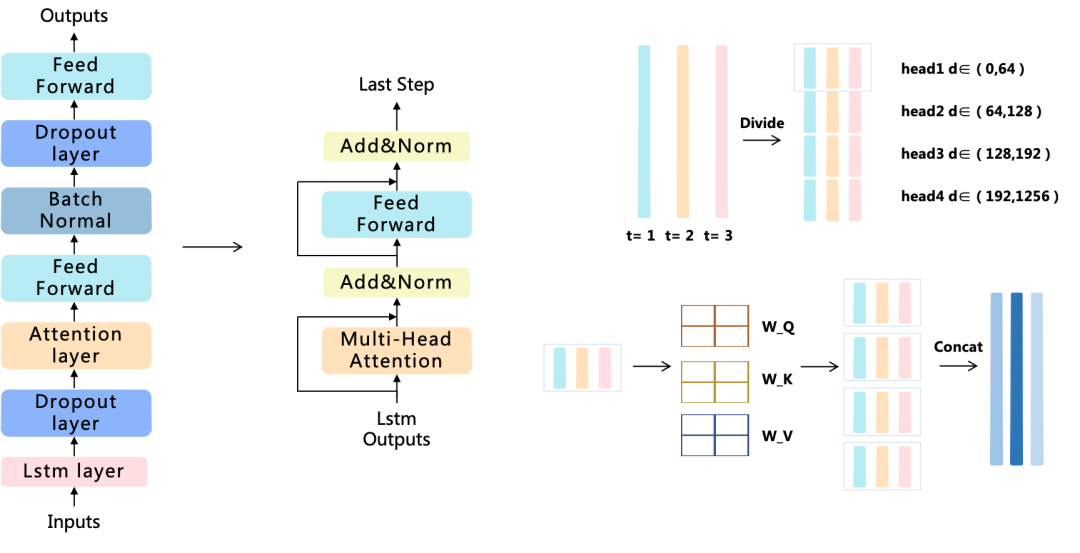
数据在经过LSTM网络层处理之后,在嵌入维度上会进行多头划分,通过多子空间的并行学习,来独立捕捉特征纬度的隐含语义信息。
在不同时间步之间会计算注意力系数,目的是融合时序信息,同时加强关键滞后期的影响权重。
搭配合理的残差连接与层归一化,解决深层训练不稳定的问题。最终我们的模型架构既能保留时序记忆,又能聚焦核心特征。
4. 训练优化
(1)网格搜索调优超参数
通过遍历多种参数组合,筛选最优配置同时设置早停机制(连续30轮验证损失无改善则终止训练),避免模型过拟合,保障泛化能力
示例代码:
'folder_path': "最终数据/20250704",
'forecast_days': 7,
'feature_columns': ['申购金额', '赎回金额', '申赎1曝光', '申赎2曝光', '申赎3曝光', '节假日'],
'target_column': '申购金额',
'batch_size': 64,
'val_samples': 88,
'learning_rate': 0.001,
'weight_decay': 1e-5,
'num_epochs': 300,
'early_stopping_patience': 30,
'print_interval': 10,
'bidirectional': False,
}
param_grid = {
'lookback_days': [5, 7, 10, 15],
'dropout_rate': [0.1, 0.15, 0.2, 0.25, 0.3],
'activation': ['prelu'],
'hidden_size': [160, 192, 256, 288, 320]
}
(2)多模型集成:贝叶斯加权抗波动
单一模型在震荡市场中易出现偶发偏差,我们采用模型贝叶斯加权策略,筛选验证集WMAPE最低的3个单模型(记为M1、M2、M3);
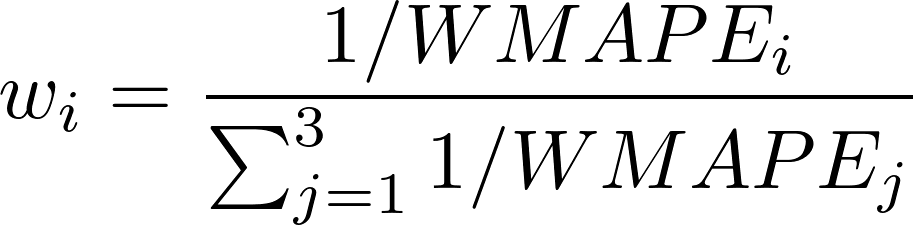
最终预测值:

落地设想
本方案可快速落地资管机构核心多业务场景:
- 在基金管理中,嵌入申赎预测模块辅助流动性规划,提前调配资金应对赎回高峰;
- 适配ETF、股票等产品,替换行业关键词与量价特征即可生成交易预测,支撑投研决策;
- 对银行而言,将申赎金额替换为存款流失率,结合情绪与节假日特征可预警挤兑风险。
落地时可开发可视化看板,集成特征热力图与误差分析,配合全流程自动化的快速更新能力,为机构提供实时、可解释的决策支持,助力风险管控与产品优化。