方案介绍
赛题分析与方案概述
本次比赛解读一下就是在黑盒场景中,我们需要在评测标准的约束下对线上多个模型进行无目标攻击。基于上述对比赛的解读,我们重点阅读分析了几篇黑盒场景下无目标攻击的论文[1-6],最后确定基于词的重要性分数生成文本对抗样本对模型进行攻击的方案,这也是当前黑盒对抗样本攻击的主流方法。
词的重要性分数构造方式如下:
其中,I_{w_{i}}表示词语w_{i}对句子X的重要性分数,一句经过分词后由n个词组成的句子X可以表示为X=\{w_{0},w_{1},...,w_{n}\},X_{\backslash w_{i}}表示将词w_{i}删除后的句子,F为分类模型,Y为预测结果,F(X)=Y,F_{Y}(X)代表句子X在F模型中预测标签为Y分数。
本次比赛的分类标签只有两种:辱骂和非辱骂。我们用Y代表辱骂标签,\bar{Y}代表非辱骂标签。为了直观比较,我们统一将预测结果为非辱骂标签\bar{Y}的文本通过公式F_{Y}=1-F_{\bar{Y}}计算出其辱骂标签的预测分数,并将辱骂标签分数作为我们的模型分,模型分越高表示该文本的辱骂性质越强,模型分越低表示该文本的辱骂性质越弱。
基于此,我们前期制定的基本方案如下:
- 收集语料,并使用参考模型计算每个词的I_{w_{i}}。
- 删除,替换I_{w}较高的词,选择低I_{w}的词作为噪声添加,以降低模型分。
语料收集与词语分析
我们从Github中找到1500+条脏话语料,其中包含着大量不能通过字面意思快速识别的文本。我们用参考模型筛选出一批并做去重大约剩400条左右,这个数据量用于训练模型显然是远远不够的,训练出来的模型还可能会误导我们的思路,但由于辱骂场景下的语料的敏感性,实在是难以收集,我们决定不花力气在收集语料上,放弃训练模型的念头,打算好好利用这400条数据以及参考模型。
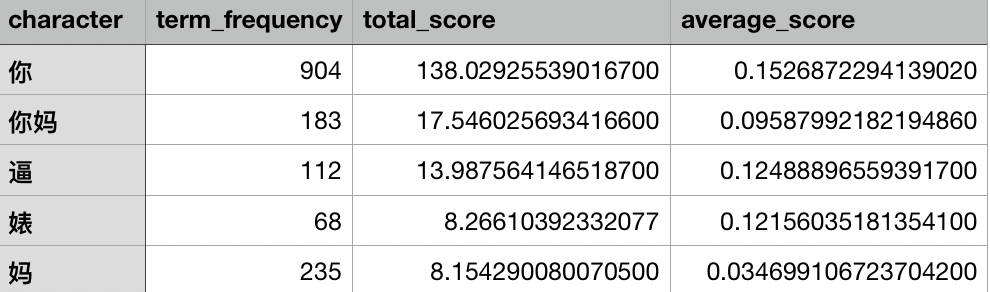
我们用参考模型对收集到的语料以上述重要性计算方法算出了每个词的重要性,并统计了每个词的词频、平均分、总分,以作为我们之后策略制定的参考。值得一提的是,"你"这个字,无论是词频还是均分都大大超过了其他的词。(划重点,等等要考。)
攻击策略探索
改
我们一开始做的是对关键词的修改。因为有人工审核的一步所以要保证可读性,我们选取总分top50的词加Wikipedia中Mandarin Chinese profanity词条中的词汇人工选取备选词,根据形、音、意三个方面选取备选词。
形近:你与鉨 音近:你与尼 意近:你与汝
考虑到评测标准中的Jaccard_word与Jaccard_char这两项,我们并没有选择拼音或者英语作为替换词,又考虑到人工审核的影响,我们选词策略是:尽量选取形近或者可一眼识别出的音近字,避免生僻字以及意近字。
为了验证我们的想法,首先我们对词频最高的"你"进行了替换,大概获得了49分。随着替换词表的不断扩大,分数的增长也渐渐减缓,到100分左右就进入了瓶颈期,这时候我们看着排行榜上那些300+分的大神们,觉得这词表再怎么优化提升可能也填不满这200分的差距,就决定将精力转移到其他增长点中。
删
通过对收集语料的分数观察,我们发现其实很多符号,如”,“、“。”的辱骂分也挺高,所以我们对符号进行了删除,在替换策略的基础上加了9分左右。
接着我们对人称代词进行了探索。我们认为,“cnm”和“cn”(请大家自行想象原文)虽然删去了关键词“妈”,但保留了辱骂性质。利用这一操作能在替换的基础上再加20分,但是由于这一策略过于不可控,可能会有未预期的情况,这也是删除这个策略的通病,所以我们稍加探索之后决定谨慎使用该策略。
增
在试完改与删策略之后,我们重新对常见的文本分类模型进行了研究,以期望能找到点新思路。
首先是研究了fastText,fastText的核心思想是词向量以及其n-gram构成的向量相加取平均值进行预测,很容易联想到:如果增加一些I_{w}较低,甚至为负分的词,可以有效降低F_{Y}(X)。用参考模型做实验也印证了我们的想法,更进一步的发现是,在添加的噪声足够长的情况下,对抗样本的模型分会根据添加噪声的I_{w}的不同被拉高或降低到某一平均值附近,这也符合fastText的原理。
由下图可以看出,在添加长噪声“9”后,无论原始的模型分是多少,最后的模型分都趋近于0。
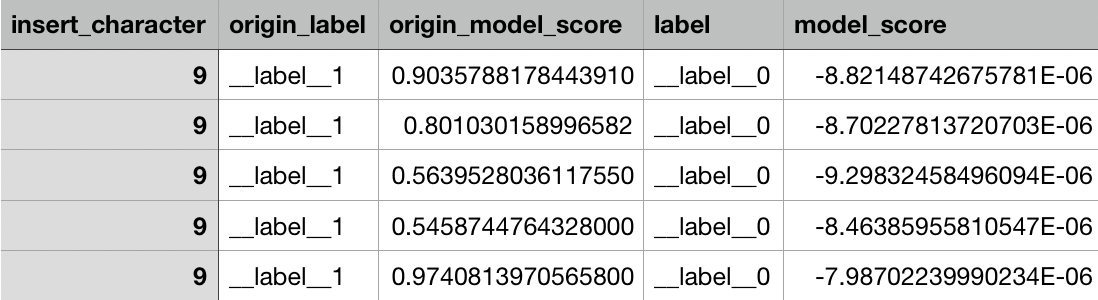
那么问题来了:这结论迁移到其他模型中成立吗?我们分析后认为是成立的,即使是有遗忘门的GRU和LSTM等RNN-based的神经网络,或者是textCNN和RCNN等CNN-based的神经网络,只要噪声足够长,一定会对预测结果有影响。
然后,考虑到Jaccard_word, Jaccard_char以及embedding_cosine三者的影响,我们选取了大小写字母加数字的组合方式作为我们的噪声备选列表,随机选取其一并在原文本末尾添加等长的噪声。这一步加上之前的替换策略一共得了300+分。
值得一提的是,添加长噪声的方法基本放弃了Levenshtein这项,但却在Jaccard_word, Jaccrd_char, embedding_cosine这三项几乎都有较好的表现。
然而每个噪声词的I_{w}也是不一样的,62个字符组成的备选列表还是太大,之后的工作就是不断缩小备选列表,锁定I_{w}最小的几个字符作为我们的噪声备选词。通过不断地实验我们最终锁定了几个数字,其中“2”的表现最好。由于挖掘机制的存在我们小心翼翼的调整“2”在噪声备选词列表的比例,结果发现:挖掘策略对数字没有设防。。。
在不断地对长度进行调优之后,我们最后得出,大量添加“2”这个字符(添加长度为原文本长度的六倍左右),可以拿到530分左右。
除此之外,我们还尝试了在句子中每个词间添加噪声,不过可读性,Jaccard_word,embedding_cosine这三项都不太理想,故没有继续探索。
less is more
接下来就是对上述策略的组合了,考虑到人工审核的影响和评测分数的影响,我们选择了组合增与改的策略,简单组合后得到了605分左右。
接着我们想到,在添加噪声的策略已经获得了较好的表现的情况下,原始辱骂样本的模型分也被大大降低了,那么其实不需要那么大的替换词表也能取得很好的效果,还可以大幅增加每条的Jaccard_char, Jaccard_word的分数。所以我们在增加噪声的前提下,将原来的替换词表进一步的缩减,缩减到只剩替换“你”字时,整体效果最好,能拿670分。
最后几分就是根据文本长度调整噪声长度了,就不加以赘述了。
赛后总结
本次比赛其实传统信安的渗透思维还是有很大帮助的,诸如填充异形字符与超长文本等都是常见的黑盒测试的手段。再结合模型原理,想到上述方法其实也并不难。虽然因为提交次数有限没有办法Fuzzing,但是在大方向正确的情况下,不断通过提出假设-设计实验-得到反馈这一循环,最终能取得不错的成果。
参考链接
[1] Generating Black-Box Adversarial Examples for Text Classifiers Using a Deep Reinforced Model. Prashanth Vijayaraghavan, Deb Roy. ECMLPKDD 2019.
[2] Black-box Generation of Adversarial Text Sequences to Evade Deep Learning Classifiers. Ji Gao, Jack Lanchantin, Mary Lou Soffa, Yanjun Qi. IEEE SPW 2018.
[3] TEXTBUGGER: Generating Adversarial Text Against Real-world Applications. Jinfeng Li, Shouling Ji, Tianyu Du, Bo Li, Ting Wang. NDSS 2019.
[4] Generating Natural Language Adversarial Examples through Probability Weighted Word Saliency. Shuhuai Ren, Yihe Deng, Kun He, Wanxiang Che. ACL 2019.
[5] Is BERT Really Robust? A Strong Baseline for Natural Language Attack on Text Classification and Entailment. Di Jin, Zhijing Jin, Joey Tianyi Zhou, Peter Szolovits. AAAI-20.
[6] Generating Natural Language Adversarial Examples. Moustafa Alzantot, Yash Sharma, Ahmed Elgohary, Bo-Jhang Ho, Mani Srivastava, Kai-Wei Chang. EMNLP 2018.