1 赛题背景分析与理解
该赛题是面向大规模电商平台设计的,任务要求在很短时间内从千万级的商品库C中为用户挑选出最可能感兴趣的k个商品。其中,k<
数据集包括用户行为文件、用户信息文件与商品信息文件。用户信息包含用户ID、性别、年龄与购买力,商品信息包含商品ID、类目ID、店铺ID与品牌ID(若有商品价格,有望提高推荐效果),用户行为涉及16天(由某个周五开始)的用户对商品的行为日志。
比赛要求预测一组给定用户在第17天感兴趣的商品列表。需要注意的是,初赛与复赛的方案评价方式有较大差别:
(1)初赛提供了待预测用户的信息、第1~16天的行为日志及感兴趣的商品信息,参赛选手可以仅适用待预测用户的信息设计方案,将预测结果提交到线上进行评测,评价指标为Recall@50与Novel-Recall@50的加权均值(经我们分析可能为Recall@50 * 0.15+ Novel-Recall@50 * 0.85)。其中,Novel-Recall@50要求推荐的商品不能与历史感兴趣商品属同一类别,因而难度很大。
(2)复赛将待预测的用户信息等文件置于线上,不允许打印相关信息等内容,而且对运行时间及资源又添加了限制。利用线上用户行为日志等信息建模效果尚可,但复杂度可能会超出要求,因而很多信息及模型需要在线下统计、训练。此外,评价指标变为了Recall@50,并要求推荐的商品不能与历史感兴趣商品相同。该指标比初赛简单些,因为可以推荐同类商品,这在真实业务及该数据集中都较常见。
2 团队成员介绍
“在理性的基础上,一切判断都是统计学。” ———— 著名统计学家C. R. Rao
薛传雨(天池ID:小雨姑娘),青岛大学计算机科学与技术专业大四本科生,曾在三个数据挖掘比赛取得Top 3成绩,正寻找国内数据挖掘实习与国外攻读博士的机会。
张卓然(天池ID:人畜无害小白兔),春秋航空算法工程师,曾在多个天池大赛取得Top 10成绩。
吴舜尧(天池ID:BruceQD),青岛大学计算机科学技术学院讲师、硕士生导师,曾参加或指导学生参加三个数据挖掘比赛取得Top 2成绩。
3 核心思路
初赛方案仅基于规则做了Match阶段,里面有些技巧,感兴趣的同学可以关注https://github.com/ChuanyuXue/CIKM-2019-AnalytiCup,之后会在上面发布代码。下面重点阐述复赛方案。图1给出了推荐系统的经典流程,先从千万级商品库中为指定用户召回几百或几千个候选商品,再建模为候选商品排序,选出少量商品作为最终的推荐列表。
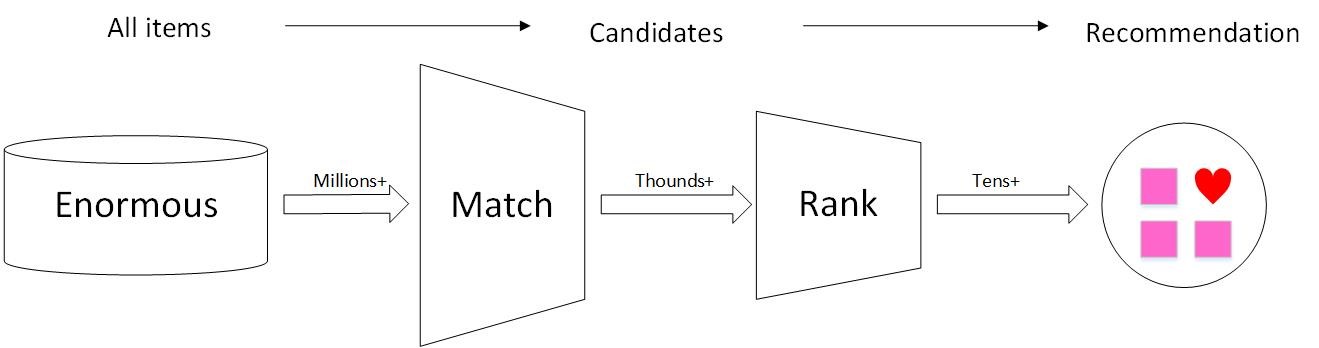
图1 推荐系统经典流程
3.1 EDA(数据分析与探索)
数据分析与探索对方案设计有重要的指导作用。下面介绍几个关键的分析。在做EDA时,我们将数据集切分为了两部分,第1~14天日志被视为“历史”行为,第15天日志视为“未来”行为,从而可以分析对“未来”行为有重要影响的“历史”行为特点。
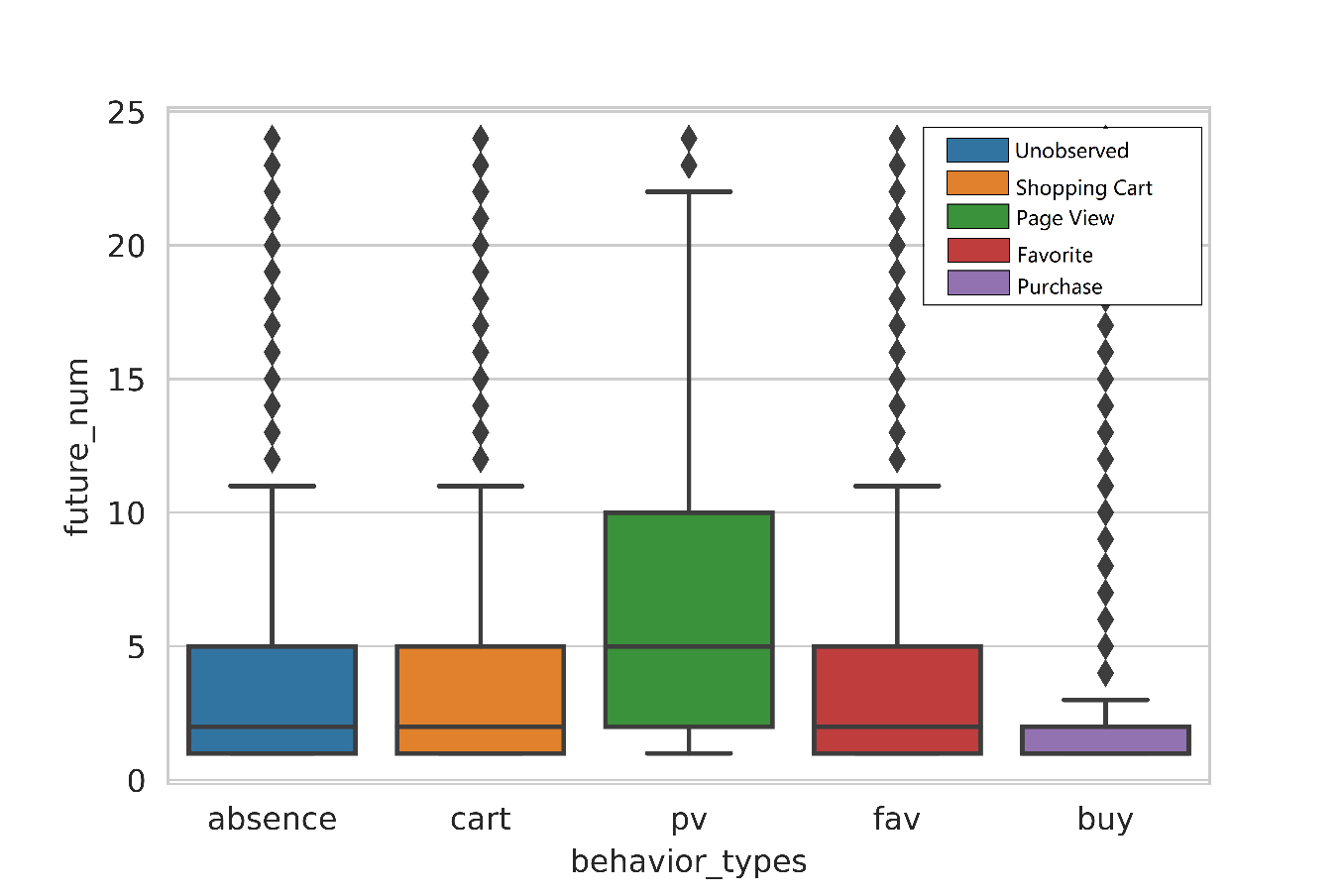
图2 用户对“历史”感兴趣同类商品的“未来”行为统计分析。
用户行为共有4种类型:'pv'(浏览)、'fav'(喜欢)、'cart'(加入购物车)和'buy'(购买)。按照感兴趣程度,可将这4种类型的权重依次设为1、2、3、4(论坛发布的初赛baseline即是这样设置,效果尚可)。图2先获取了用户“历史”感兴趣的商品类别,然后统计了“未来”对历史感兴趣的同类别商品的行为。图2表明“未来”感兴趣的商品(出现在第15天日志中的商品)几乎不会是以往购买过的同类商品。因而,我们在复赛方案中将'buy'的权重设为1。实际上,4种行为的权重仍可调优,但我们限于时间和精力未做。
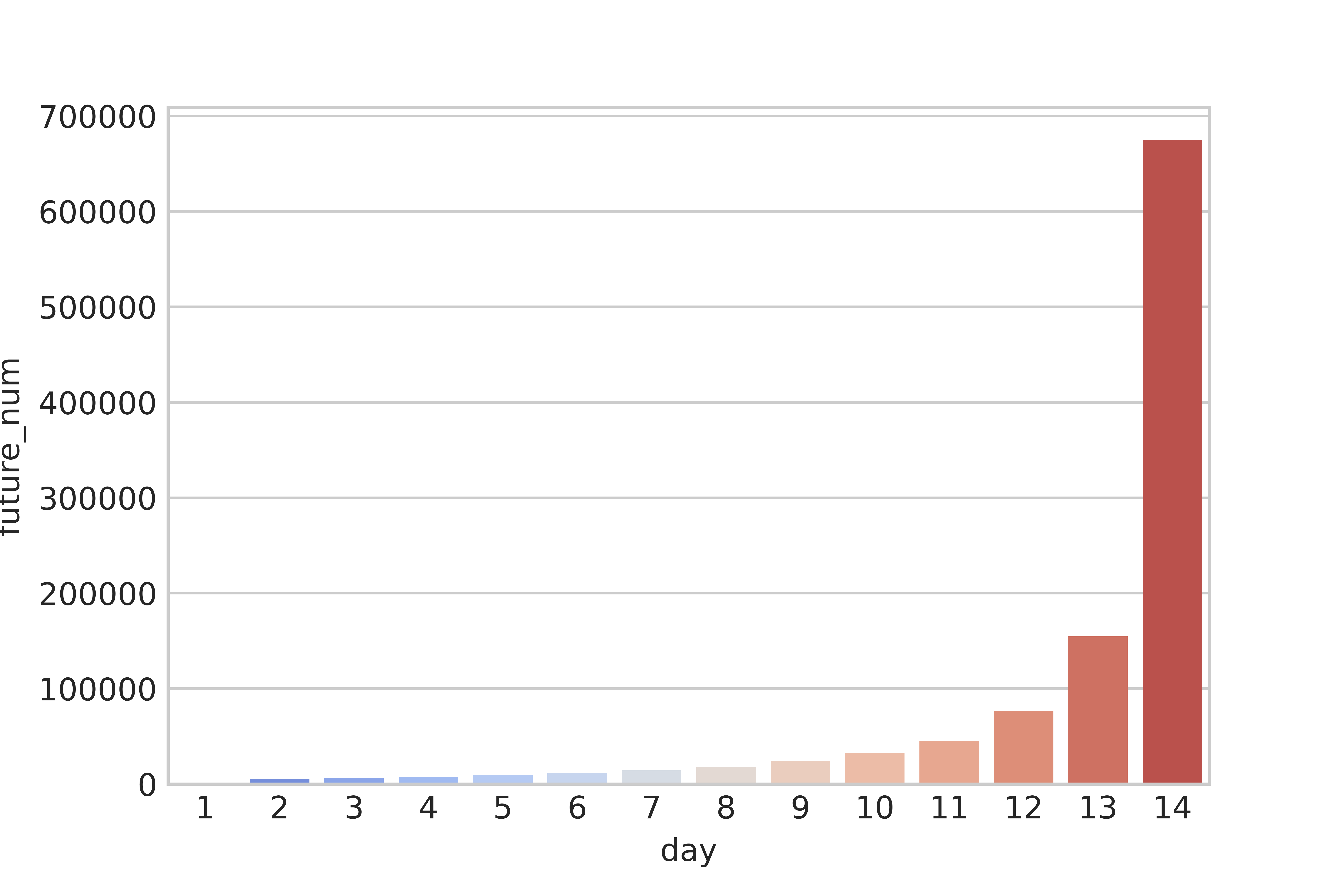
图3 “未来”感兴趣商品在第1~14天被感兴趣的次数
如图3所示,“未来”感兴趣商品在第14天被感兴趣的次数组多,距第14天越远次数越少。因而,我们考虑时间因素对行为重要性的影响,按下式调整行为权重:
其中,s_{pv}、s_{fav}、s_{cart}、s_{buy}是四种行为的权重,T_{u,i}代表距最大时间戳D_{max}的远近,R_{u,i}是虑时间因素后评估用户u对商品i的感兴趣程度。
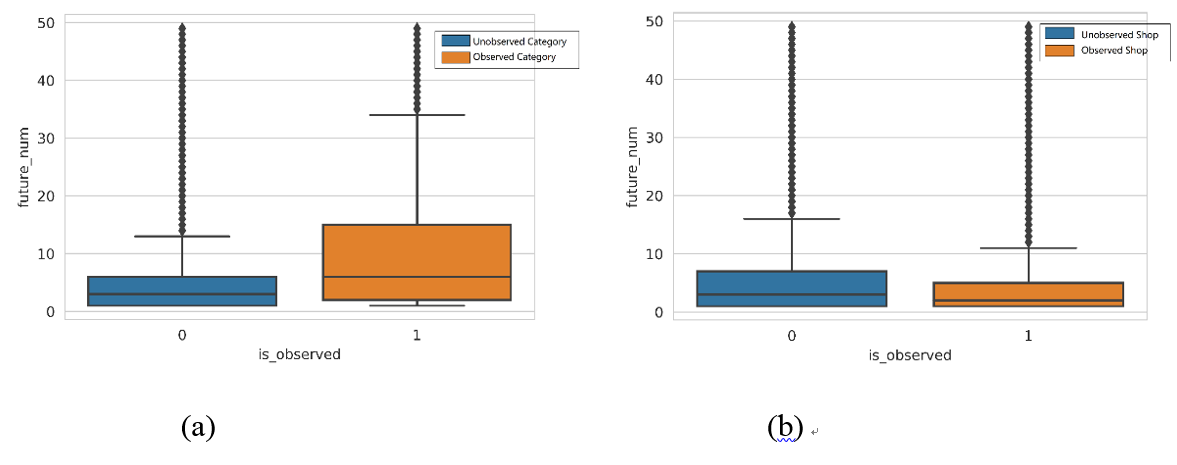
图4 用户是否仍会对“历史”感兴趣的商品类别及店铺感兴趣。
图4没有区分行为的种类,统一分析了用户在“未来”是否仍会对“历史”感兴趣的商品类别及店铺感兴趣。如图4-(a)所示,用户在“未来”仍会对“历史”感兴趣的商品类别有较高兴趣;图4-(b)则表明,用户在“未来”对历史感兴趣的店铺有较低的兴趣。进而,我们针对类别/店铺提取了一些特征,详见对排序阶段的介绍。
3.2 召回阶段
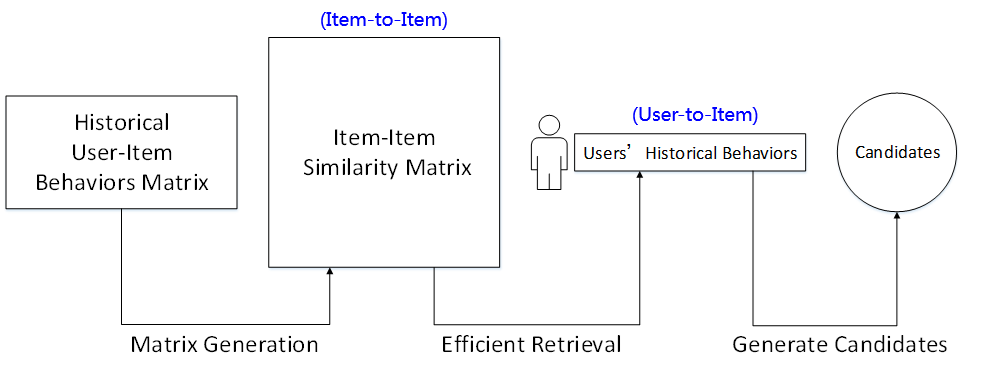
图5 基于Item CF的召回流程
召回的策略有很多,即使是基于规则的策略效果也可以。在复赛后期,我们花费了很大精力实现了一种Item CF算法,效果也有明显提升。图5给出了基于Item CF做召回的流程,先利用庞大的历史日志统计item-item相似性矩阵,再结合目标用户的历史行为做推荐。实现的难点在于对约8000万历史日志做统计的复杂度太高,需要做优化代码、做并行化处理。
如图6所示,我们将用户分为了若干组,并行处理每组内item-item共现频率的统计,最终将与每个商品最相似性的500个商品存在字典中。实际上,对复赛训练集统计后,发现字典中键值数仅有40多万。为了提高效率,我们使用了Cpython实现统计共现频率的代码。整个流程较复杂,感兴趣的同学可以看答辩后开源的代码。
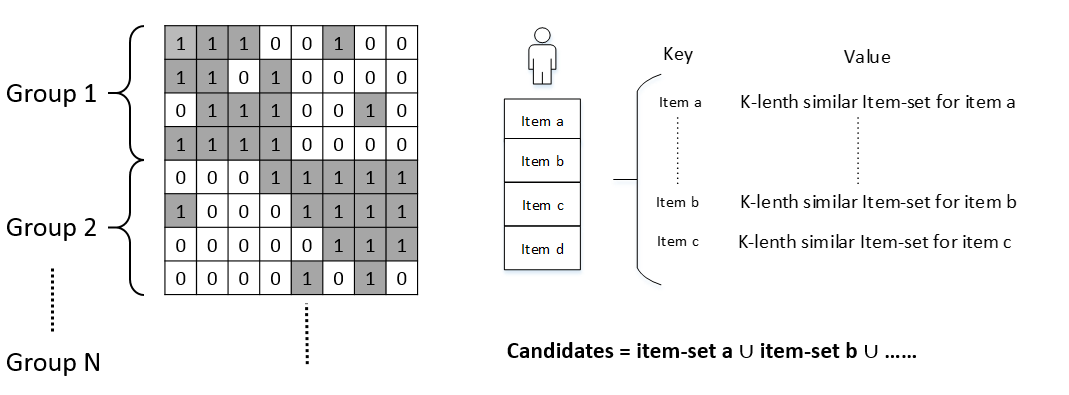
图6 并行统计item-item相似性,并转存为字典
Item CF相似性指标关乎召回的效果。我们在实现时借鉴了2015年腾讯SIGMOD论文 [1]。在9月初,我们按照关联规则中置信度计算Item CF相似性:
其中,U_i代表对商品i感兴趣的用户集合。显然,Sim(i,j)\neq Sim(j,i)。基于该指标做召回,线上效果为0.045。
在此基础上,我们又考虑了用户活跃度(感兴趣的商品数)对相似性的影响,改进了上述指标:
其中,U是全体用户集合,U_i是对商品i感兴趣的用户集合;w_u代表用户u对相似性的贡献度,w_u=\frac{1}{log(I_u)+1};当i\in{I_u}且j\in{I_u}时\delta(i,j)=1,否则\delta(i,j)=0,I_u代表用户u感兴趣的商品集合。当w\to1时,Sim^w(i,j)等价于Sim(i,j)。基于改进指标做召回,并做了些额外处理,线上效果为0.053。
3.3 排序阶段
召回阶段获得少量(300或500)候选商品后,可以构建排序模型获得最终的推荐列表。我们将排序任务转化为二类判别问题。在建模前,需要切分数据集。如图7所示,我们利用第1-15天数据做召回、生成特征,利用第16天的数据生成标签,从而生成线上训练集;利用1-16天数据做召回、生成特征,生成线上测试集,加载训练后的模型及相关文件完成预测。
需要特别注意的是,训练集中的正样本和负样本都是从召回列表中生成的,而不是将每个用户感兴趣的商品都拿出来做正样本。这是因为,很多用户感兴趣的商品对应的特征取值都无法统计,使得这些正样本失去了统计意义,对训练模型有负面影响。另一个赛道的亚军也是这样做的,他的解释也很好,“希望建模样本与召回样本同分布”。本赛道很多同学都未能建模做Ranking,应该是没能发现采样的技巧。
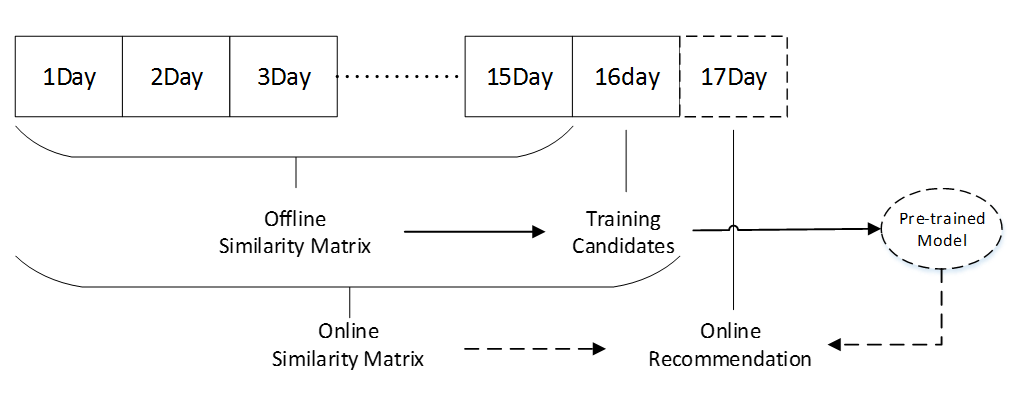
图7 排序阶段划分数据
图8为提取的特征列表,只有64个。其中,Item CF的相似性特征是强特征。最终使用了Catboost和Lightgbm建模。Catboost对过拟合的处理较好,使用了全部特征(线上效果为0.0616);Lightgbm使用全部特征效果不佳,故做了特征选择,最终只使用了36个特征。

图8 特征列表(共64个)
为了减少特征的数量,在比赛中使用了多种特征选择方法。虽然xgboost、lightgbm、catboost可以做特征重要性分析,但很多同学可能注意到把选出的重要特征给梯度提升树模型建模并无明显提升。我们做特征选择的思路是“劣汰优胜”,先基于独立性检验剔除关联弱的特征,再从剩余特征中选择重要性高的特征。两变量独立是指两变量既不存在线性相关性,也不存在非线性关联。我们采用Mean Variance Test[2,3]做“劣汰”,这是首都师范大学崔恒建教授2015年发表于统计领域顶刊JASA的工作,2018年进行了拓展,可用于做独立性检验及特征选择。该方法可检验一个离散型变量与一个连续型变量间是否独立,对变量的分布无假定(Distribution free),并且计算简单(只是计数)。这里仅列出其部分理论(图9),感兴趣的同学可以交流,该方法已被Chuanyu做成了工具包,已开源在他的github。此外,团队成员在IJCAI 2018和资金流入流出预测课程视频(天池AI课程,之后可能上线)中都使用Mean Variance Index做过特征选择,效果都不错。

图9 Mean Variance Test简介
最后,团队进行了简单的模型融合。为了提高稳健性,依次采用了调和平均值、几何平均值和算数平均值(图10),线上效果为0.0622。

图10 模型融合
3.4 其他尝试
我们还有一些基于规则的策略及其他方案没有介绍。例如,基于同类商品的规则做召回、基于同店铺的规则做召回、基于word2vector的思路做召回(借助faiss)、基于MinHash LSH做Item CF、取最近100条用户行为做统计等等。感兴趣的同学可以交流。
4 比赛总结和感想
QDU由青岛大学本科生薛传雨(小雨姑娘)、春秋航空算法工程师张卓然(人畜无害小白兔)、青岛大学讲师吴舜尧(BruceQD)组成,我们都曾在一些数据挖掘比赛取得过Top 1、Top 2、Top3或Top10的成绩。本攻略与总结由吴舜尧撰写。
参加CIKM挑战赛的原因有二:(1)希望验证自身技术和研究价值;(2)参加会议,与专家交流,帮助薛传雨申请博士。受限于复赛任务要求,我们没能在比赛中使用开发的推荐系统框架(一种基于组间效应的增量推荐系统框架[4])。运气好的是,我们可以去答辩,并有机会去workshop分享了。现在如果在比赛中拿不到Top,很难作为简历的亮点,拿不到好的offer。12年我做KDD CUP时,只是100名经过三轮面试就拿到了百度的offer(也可能是因为我还有SIGIR和JCDL的poster);17年我带的研究生找工作时,前100或前50的排名已经拿不到offer,幸好之后拿到了两个比赛的Top1和Top2,才拿到了offer;今年感觉更难了,普通公司都要面试2~3轮,好公司要面试5~6轮。
想法比套路重要得多。大家在做比赛时,应该把精力放在数据分析与探索,从而提取有用的规则,利用规则进行初步想法的验证;进而,基于规则生成特征,再考虑建模、模型融合。另一方面,建议大家学好统计,读读统计学领域的论文,有助于加深对机器学习的理解。此外,在比赛后几天,要休息好、能沉住气,不能过于急躁。最后,仅仅提高技术是不足够的,学好英语、提高表达能力也很关键。
最后,附上大四本科生薛传雨个人主页的链接(https://chuanyu2019.club/ )和二维码。

参考文献
[1] Y. Huang et al. Tencentrec: Real-time stream recommendation in practice. Proceedings of the 2015 ACM SIGMOD International Conference on Management of Data. 2015: 227-238.
[2] H. Cui et al. Model-free feature screening for ultrahigh dimensional discriminant analysis. Journal of the American Statistical Association. 2015, 110(510): 630-641.
[3] H. Cui et al. A Distribution-Free Test of Independence and Its Application to Variable Selection. arXiv preprint arXiv:1801.10559, 2018.
[4] C. Xue et al. An Incremental Group-Specific Framework Based on Community Detection for Cold Start Recommendation. IEEE Access. 2019, 7: 112363-112374.