赛题背景
研究表明,GPT-4对快速变化事实的准确性通常低于35%。LLM可能产生幻觉性回应,影响可信度。检索增强生成(RAG)通过整合外部知识源提供有根据的答案,但仍面临选择最相关信息、减少延迟、综合复杂信息等挑战。Meta Comprehensive RAG Challenge(CRAG)提供了一个严格的基准,推动RAG系统创新。

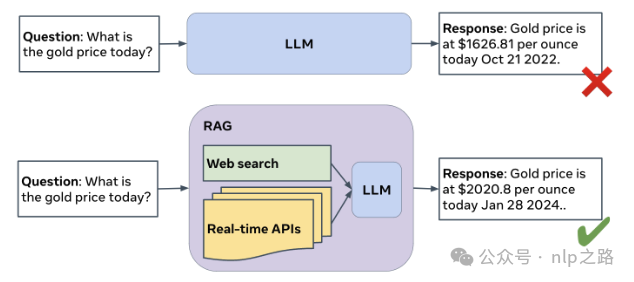
任务目标
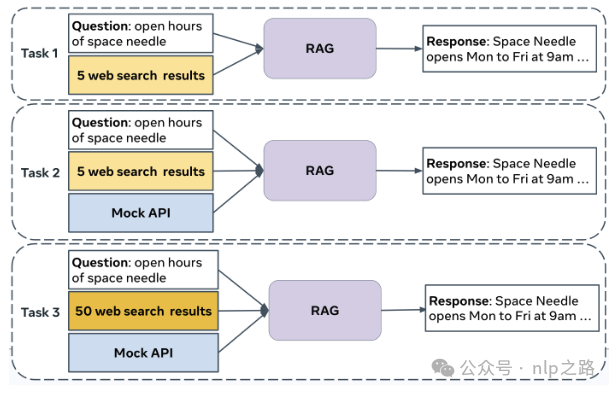
挑战包含三个递进任务:
- 任务1:基于Web的检索摘要 – 每个问题提供5个网页,系统需识别并概括相关信息生成准确答案。
- 任务2:知识图和Web增强 – 引入模拟API访问知识图谱中的结构化数据,整合多源信息。
- 任务3:端到端RAG – 提供50个网页和模拟API,从更大数据集中选择最重要数据,模拟真实场景。
评价指标
响应被评定为:完美(1分)、可接受(0.5分)、缺失(0分)、不正确(-1分)。总体得分为宏平均,按领域和实体受欢迎程度加权。
赛题分析
CRAG基准涵盖五个领域、八种问题类型,要求30秒内完成推理。三个任务逐步增加复杂性,第二、三任务涉及非结构化和结构化多源数据融合,冠军方案在三个任务中均获得第一。
冠军方案:北大 db3 团队
任务一:Web检索摘要
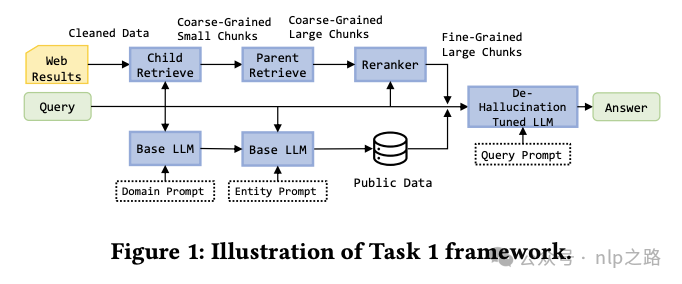
数据预处理
- 使用 BeautifulSoup 提取HTML文本,LangChain CharacterTextSplitter 分块,ParentDocumentRetriever 管理父子块(parent_chunk_size=700, child_chunk_size=200)。
- 检索器:bge-base-en-v1.5;重排序:bge-reranker-v2-m3;召回数50,根据父块大小调整喂给LLM的chunk数。
公共数据增强
针对电影、金融、音乐领域预处理公开数据(奥斯卡、MovieLens、市盈率、格莱美等),将结构化数据转为自然语言,通过实体匹配增强上下文。使用LLM定位问题领域并提取实体。



LLM推理模块
基础模型:Llama-3-8B-instruct。使用基础prompt控制答案长度和上下文,通过提示设计减少幻觉。


监督微调(SFT)
训练数据构建:无效问题标记为“invalid question”;正确回答用ground truth;错误回答经GPT-4判断后,若能推断出正确答案则用ground truth,否则标记“我不知道”。使用LoRA微调基础模型2-3轮,并利用vLLM加速推理。



任务二和任务三:知识图谱与Web增强
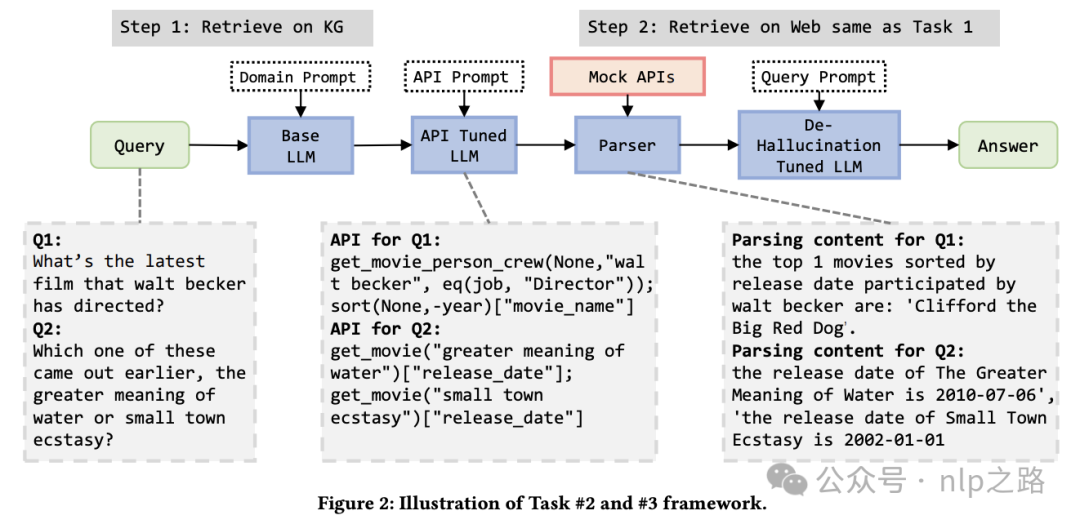
知识图谱检索模块
核心思想:使用LLM生成一系列API调用,提取查询所需信息。为简化生成难度,设计了一套规范化API,避免复杂SQL生成。例如电影领域API:

通过模板选择和实体名称提取,LLM更易生成。支持条件比较(cmp)、排序(sort)、聚合(AVG)等,可扩展多跳查询。


微调与融合
使用GPT-4生成ground truth API,人工校正后LoRA微调Llama3。任务中优先使用模拟API结果,若返回“我不知道”则回退到网页检索流程。任务3中先用reranker筛选前5个相关网页,再按任务一处理。
总结与启示
冠军方案强调实用性和专家经验:精心设计的API、提示工程、高质量SFT数据、公开数据增强,没有过度“炫技”。这为LLM在真实业务场景落地提供了优秀范例——通过合理融合检索、结构化知识、微调,填补“最后一公里”的可靠性差距。