赛题背景: 本次赛题来自OPPO手机搜索排序优化的一个子场景,并做了相应的简化,题目内容主要为一个实时搜索场景下query-title的ctr预估问题。比赛的初衷是希望通过这次比赛,能将自己学习的理论知识付诸于实践,提升自己的工程代码能力。
使用模型: 我们尝试使用了Lgb和nn两种模型,但是最终由于模型数量限制,线上提交只使用了两个lgb模型的组合方式。
下面是完整的PPT答辩内容:



对于转化率特征的计算,为了防止信息泄露,在计算单个样本时需要排除样本自身,一般采用交叉提取,例如,将数据集分成五份,每一份的转化率在其它四份上提取。

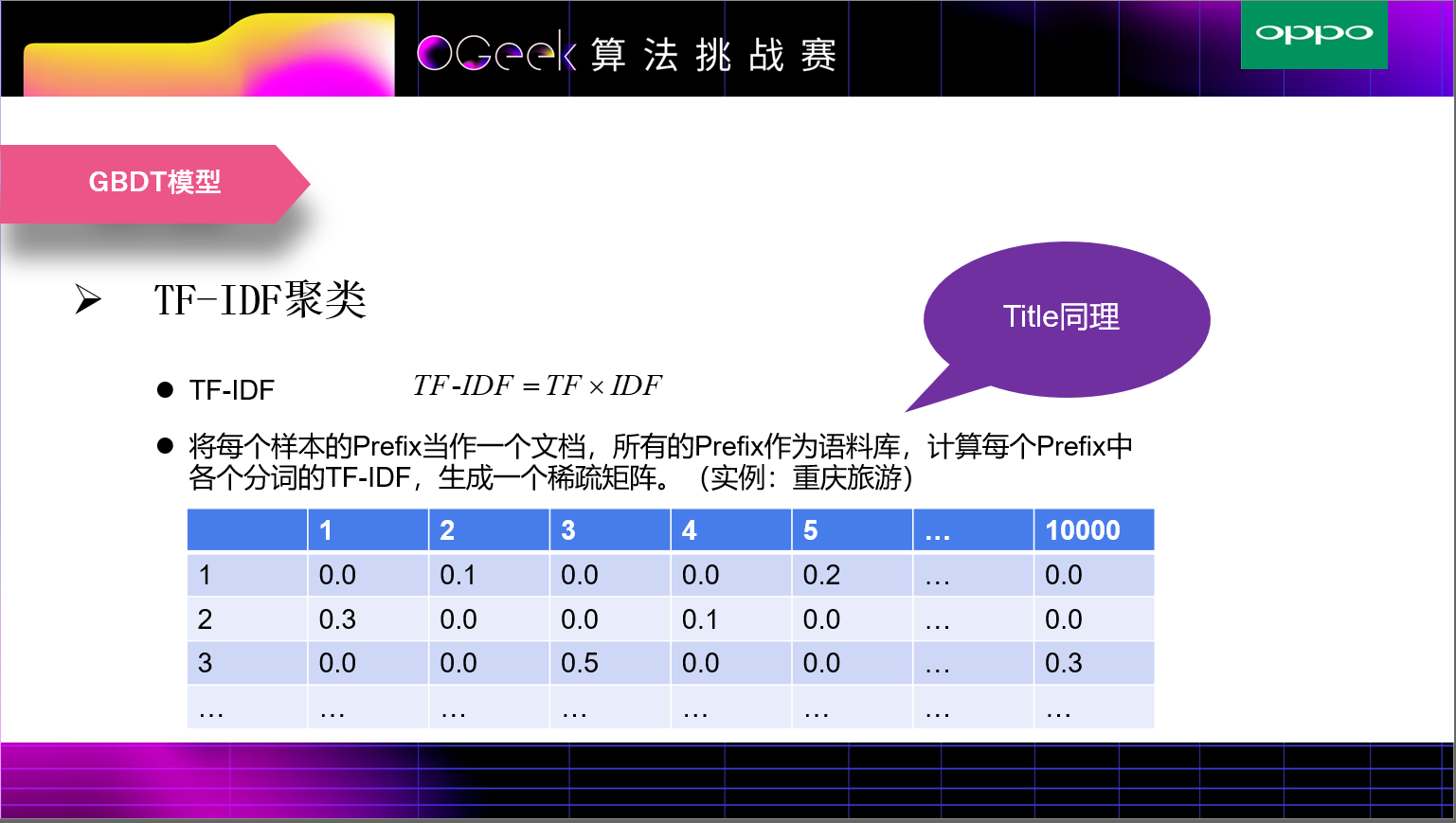
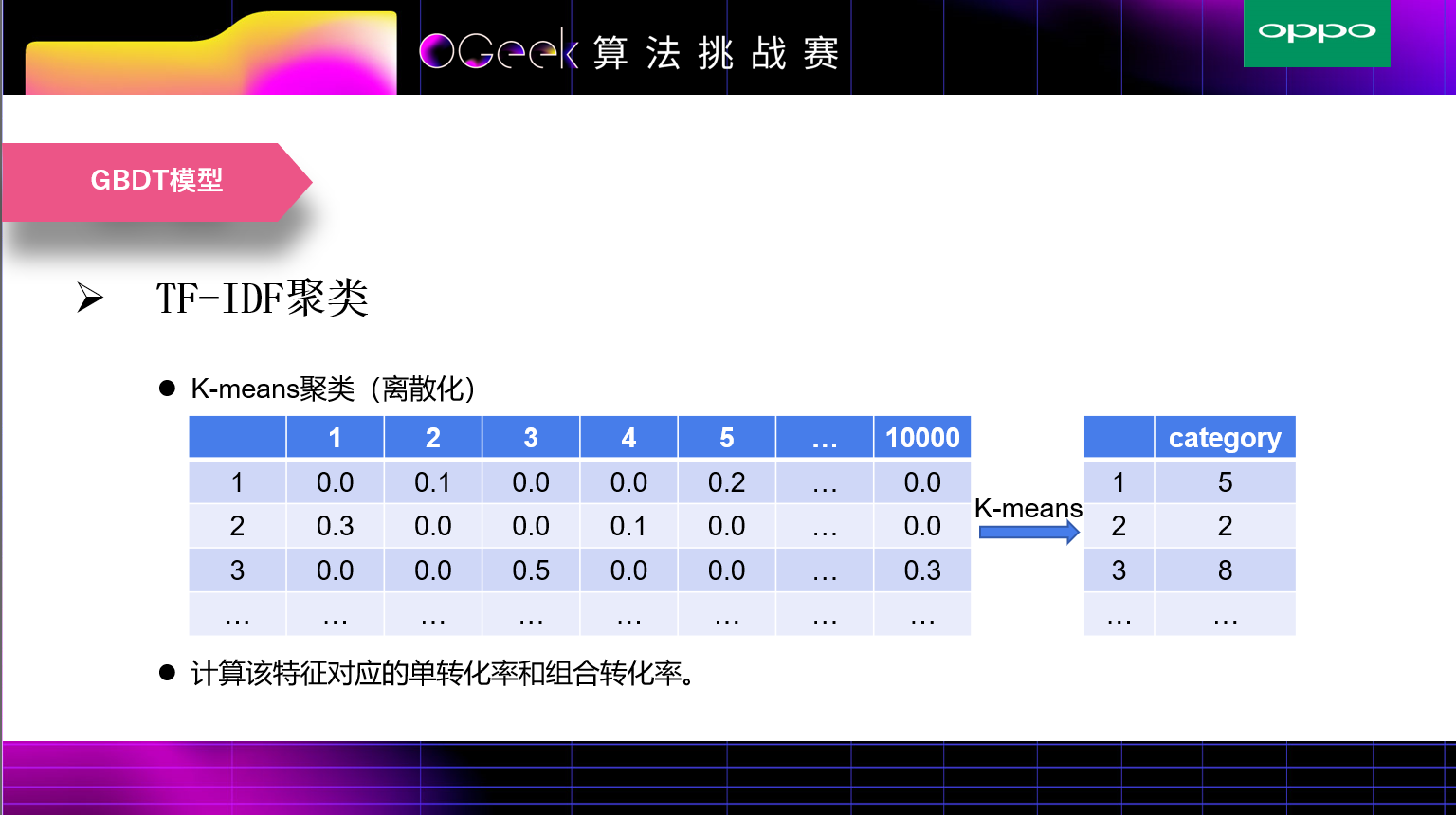
TFIDF的主要思想是:如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。为了区分每个样本的prefix,我们计算prefix中每个词的tfidf,对于每一个prefix,形成一个稀疏向量,对于整个训练集则生成一个稀疏矩阵。由于维度过高,无法直接在模型中使用,我们采用聚类的方式将稀疏矩阵进行聚类划分,然后将其类簇作为一个模型的特征。此外,我们该类簇特征的单转化率和组合转化率等等。

query_prediction是系统预测的用户完整查询词,其中最多包含10个预测词,每个预测词都有一个对应的统计概率,这里面包含着很重要的特征信息。对于每一个预测,计算它的sentence embedding,然后再将这写句向量的方差作为模型的一个特征。如果这个方差越小,则表示query_prediction表示的含义比较集中,用户的搜索相对来说很具体,那么系统给出的文章就很有可能是用户想要的内容,用户点击的概率也就越大。所以这是一个很重要的特征。

模型中还用到了其它的一些特征,比如一些相乘的交叉特征,最大的查询概率,prefix和title的长度差等等。
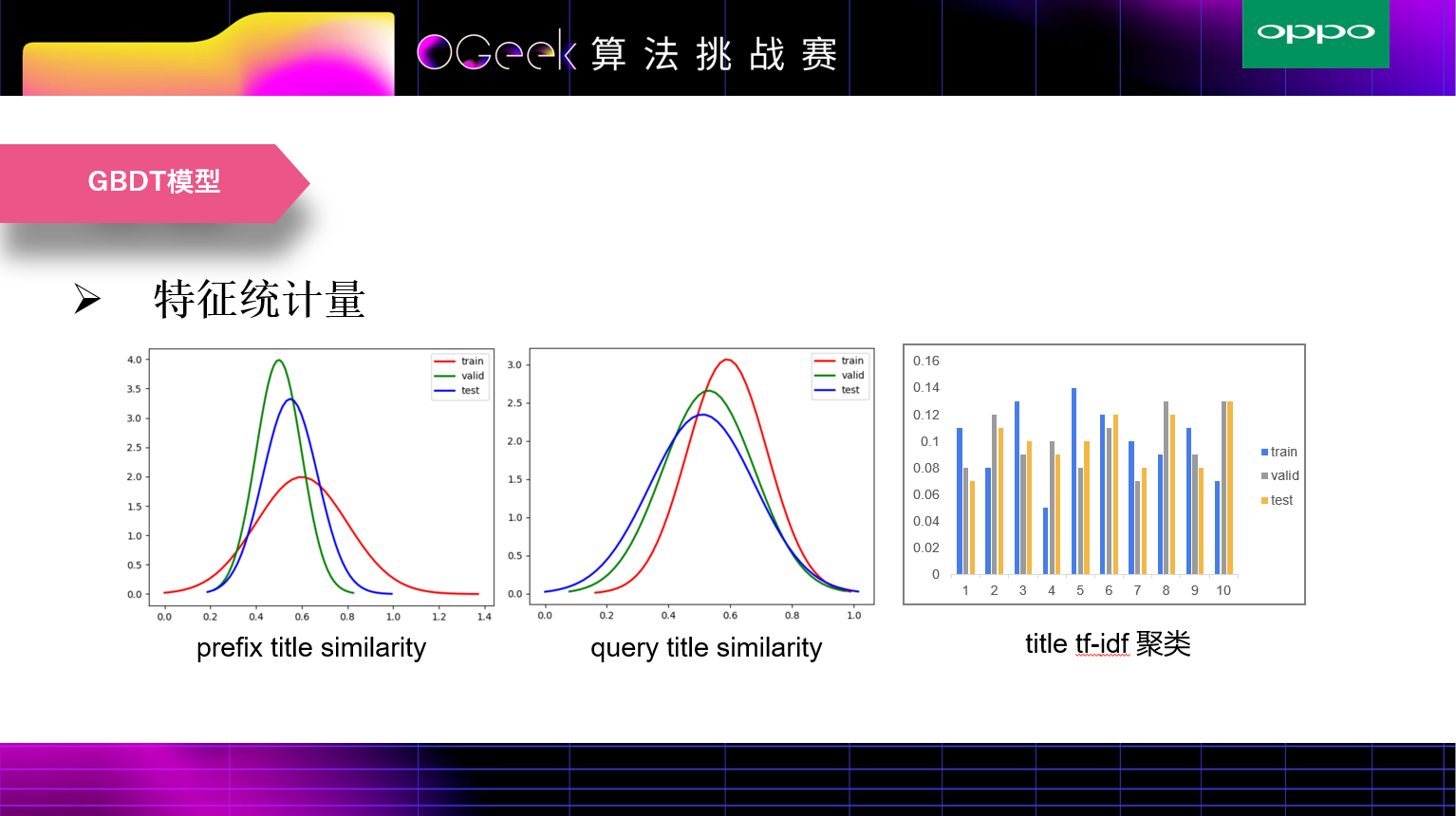
我们对其中的一些特征做了统计分析,发现验证集和测试集上这些特征的分布比较接近,也就是说验证集和测试集的分布比较一致。
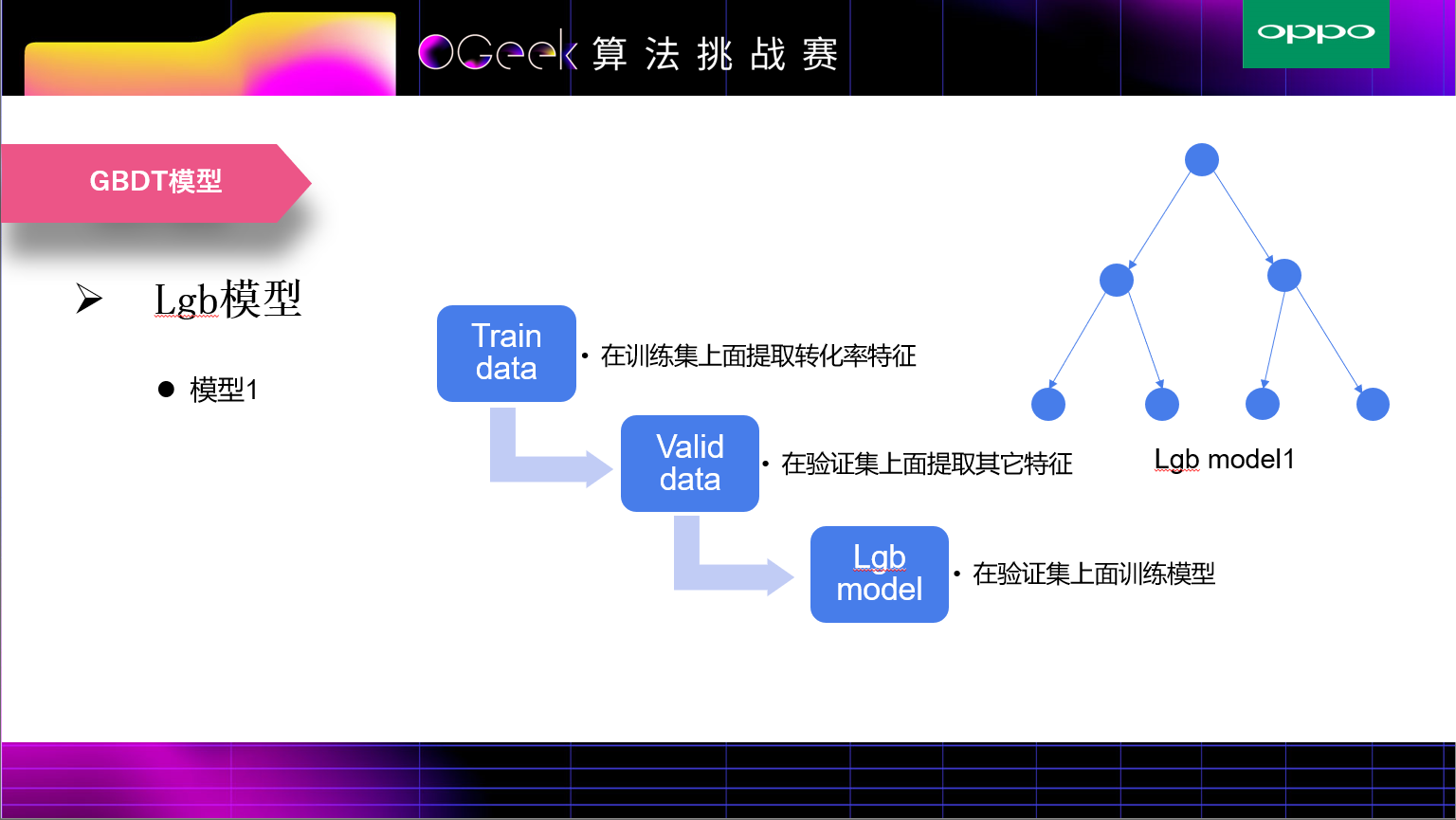
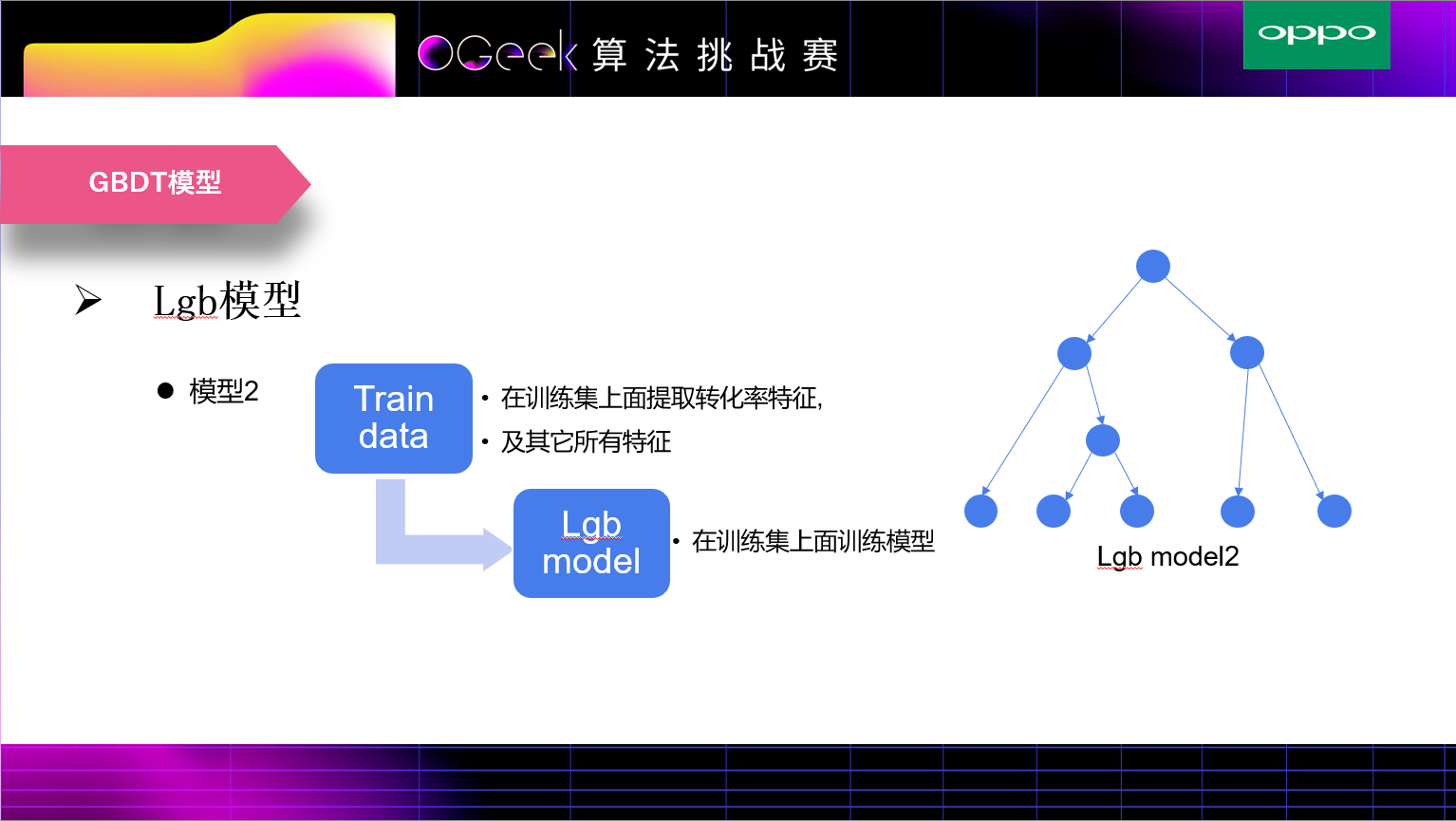
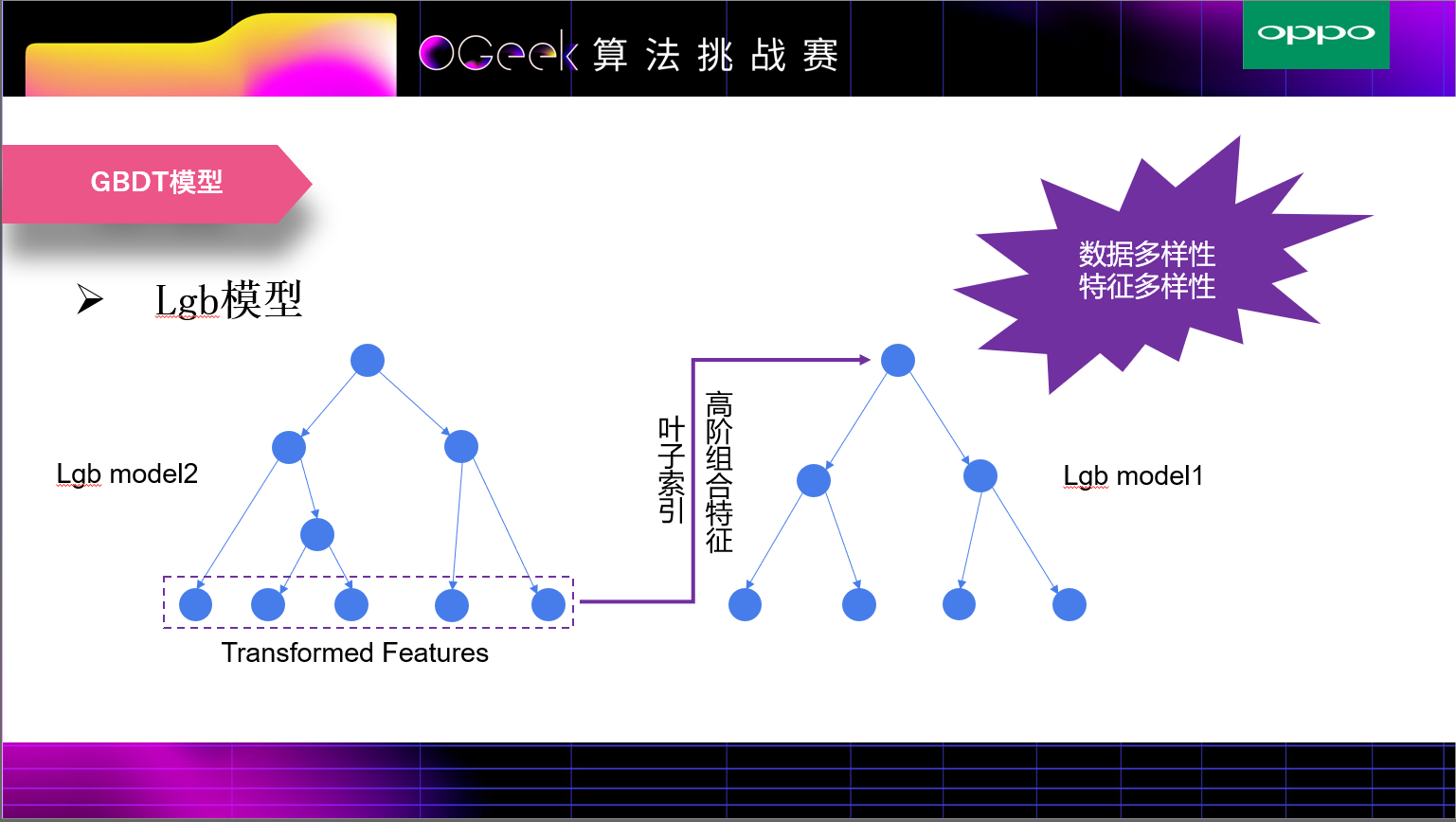
为了利用验证集和测试集分布比较一致这个特点,我们首先在训练集上训练了一个lgb模型,将验证集在这个模型上的输出(每棵树的叶子索引)作为一些高阶交叉特征作为验证集新的特征,然后使用这些特征和原始特征在验证集上训练第二个lgb模型,这个模型充分利用了数据分布一致和特征多样性的特点。测试集则在第二个lgb模型上进行预测。

尽管使用了预训练的词向量,GBDT对语义信息的捕获能力还是较弱。赛题数据量相对较大,为了借助语义信息充分挖掘隐藏特征,可以使用深度模型。
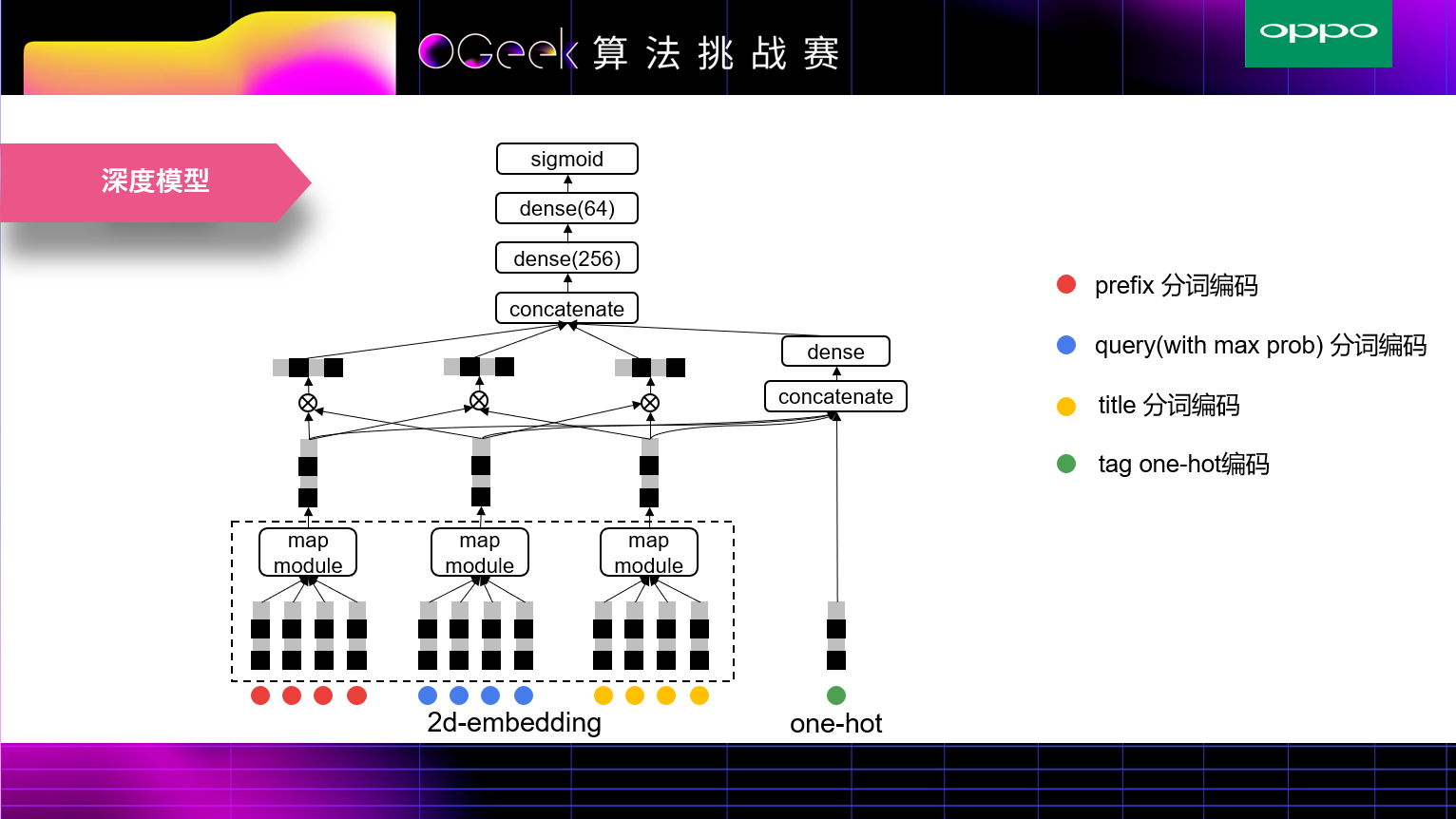
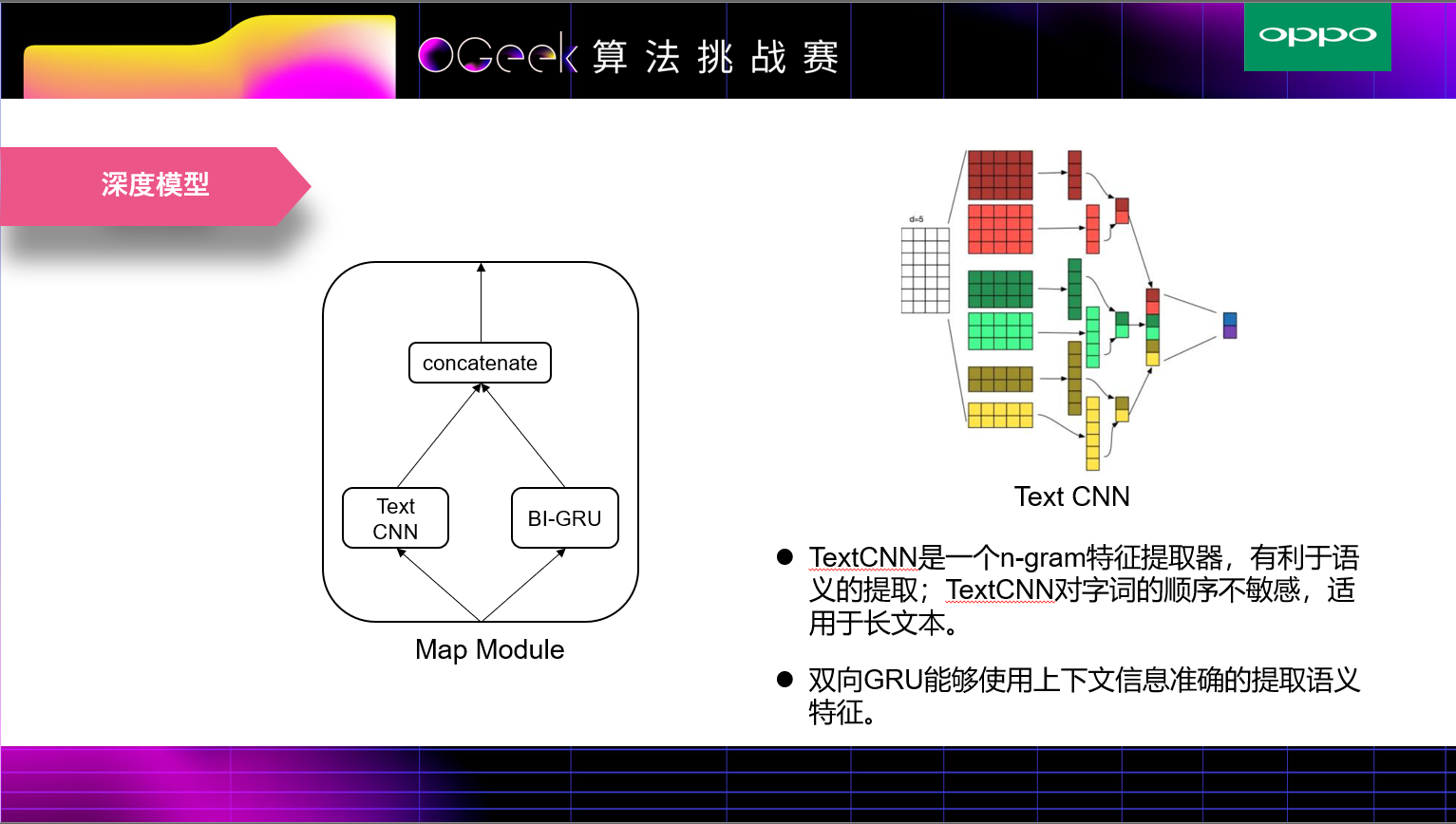
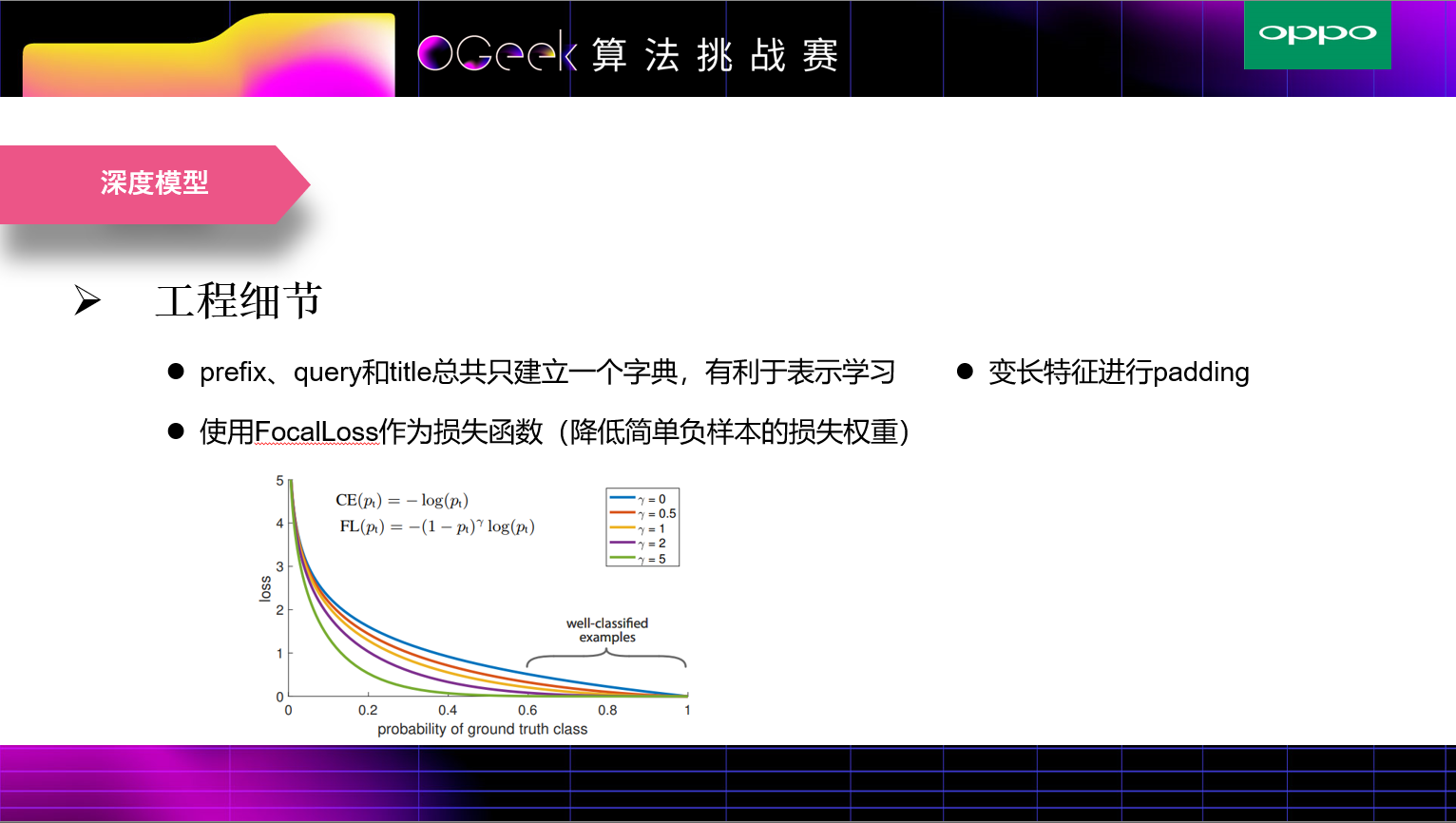
我们采用的nn模型比较简单,在映射模型中使用TextCNN和Bi-GRU来将分词编码进行映射,然后将输出做一些相乘交叉和concat操作。由于正负样本比例不是很均衡,我们使用focalloss作为损失函数。


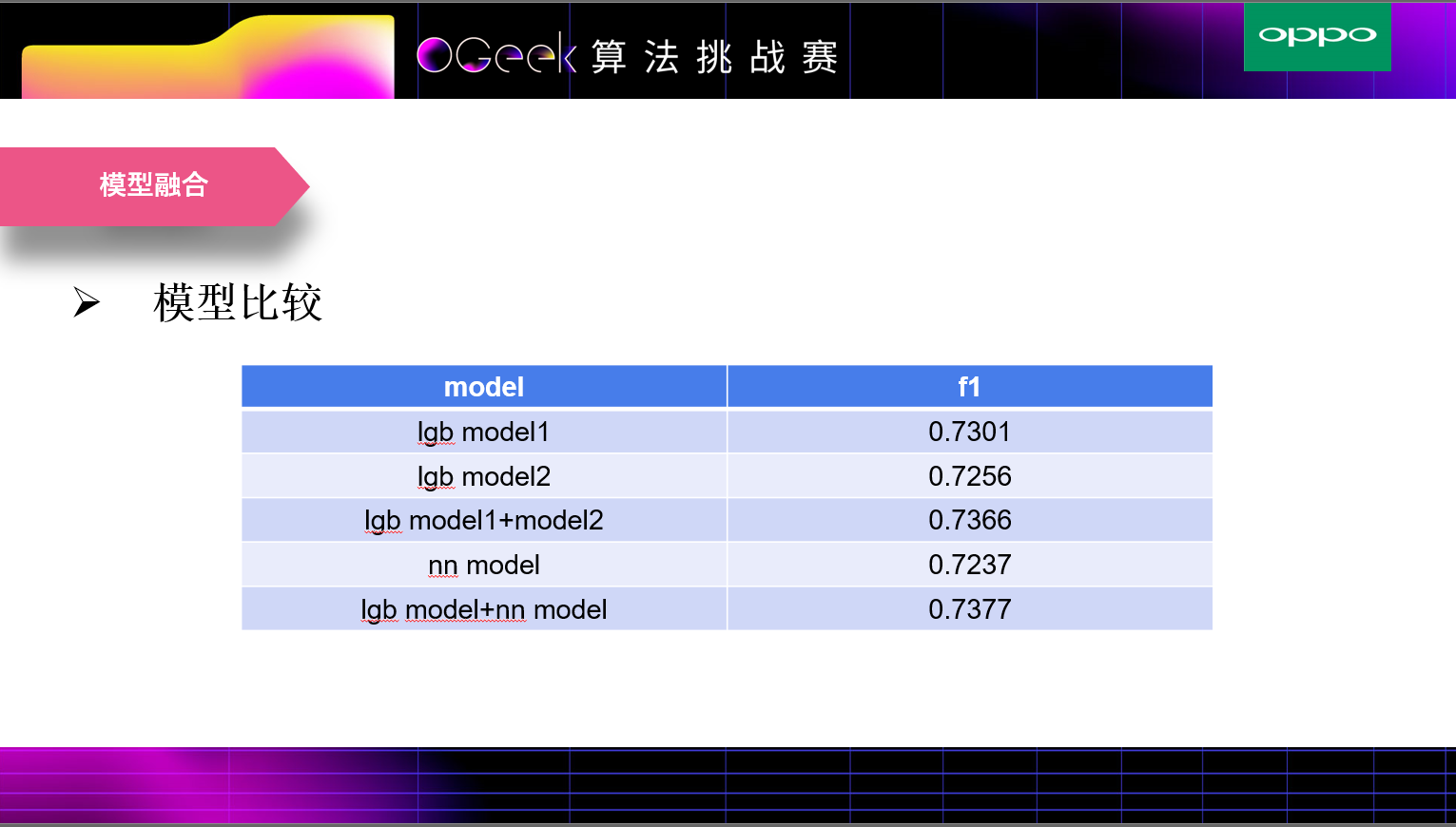

将nn模型和lgb模型结合,在A榜数据集上能有一个千分点的提升,但是由于模型数量的限制,我们在B榜上只用了lgb模型。
