简单做一下今年dcic这个题的分享,本来还算不是太野鸡的比赛在增加规则可以引入外部数据后,赛题就完全变味了。电网搞这种事是出于啥考虑咱也不多猜测。首先感谢一下青岛天洋气象科技的队友,在外部数据上帮了大忙。
外部数据引入
由于本题允许外部数据的使用,因此我们下载了ERA5再分析数据及ECMWF历史预报数据两种数据作为题目数据的补充。
ERA5再分析数据
ERA5是ECMWF(欧洲中期天气预报中心)对1950年1月至今全球气候的第五代大气再分析数据集。ERA5由ECMWF的哥白尼气候变化服务(C3S)生产。ERA5提供了大量大气、陆地和海洋气候变量的每小时估计值。这些数据覆盖了30公里网格上的地球,并使用137个从地表到80公里高度的高度来解析大气,包括在降低空间和时间分辨率时所有变量的不确定性信息。ERA5将模型数据与来自世界各地的观测数据结合起来,形成一个全球完整的、一致的数据集,取代了其前身ERA-Interim再分析。
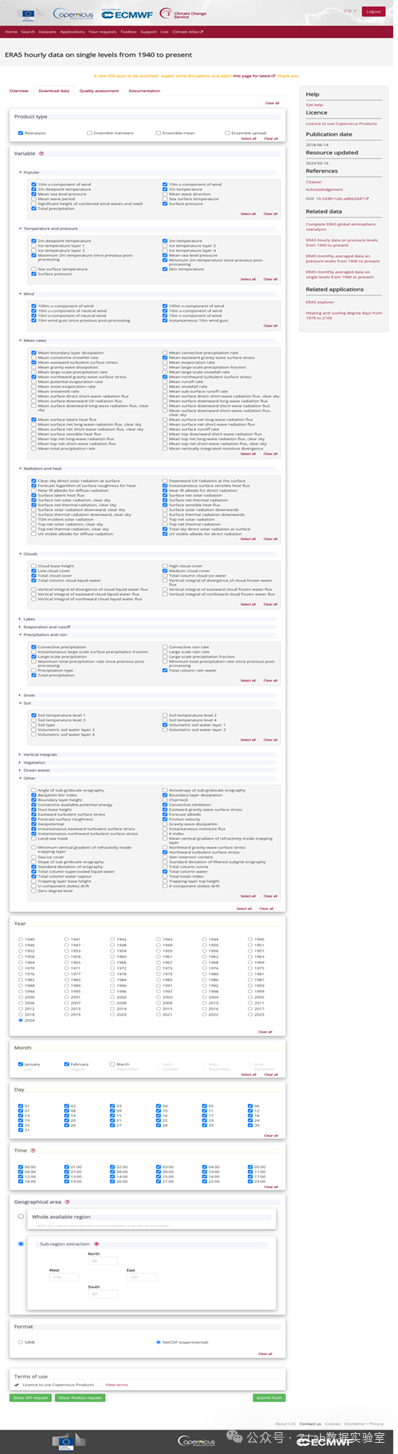
我们使用了ERA5的地面层再分析数据:
https://cds.climate.copernicus.eu/cdsapp#!/dataset/reanalysis-era5-single-levels?tab=form
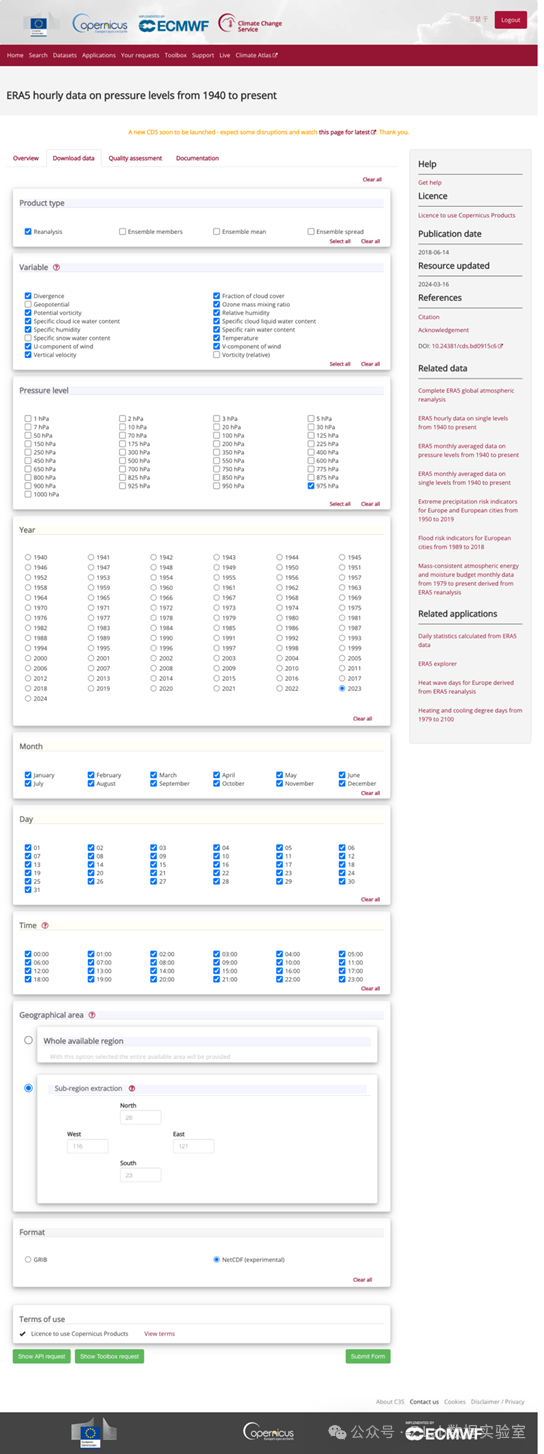
与压力层再分析数据:
https://cds.climate.copernicus.eu/cdsapp#!/dataset/reanalysis-era5-pressure-levels?tab=form
选取2022年1月1日-2024年1月31日,逐小时再分析数据,经纬度为23N-28N、116E-121E,格式为.nc。选取数据包括:
ECMWF历史预报数据(付费)
欧洲中期天气预报中心(European Centre for Medium-Range Weather Forecasts 简称 ECMWF)是一个包括34个国家支持的国际性组织,是当今全球独树一帜的国际性天气预报研究和业务机构。其网站链接为 https://www.ecmwf.int/en/forecasts/datasets/set-i。该中心于1979年6月首次做出了实时的中期天气预报。自1979年8月1日中心开始发布业务性中期天气预报,为其成员国提供实时的天气预报服务。其提供的全球预报数据是全球公认的综合准确率最高的预报数据之一。
本次选取2022年1月1日-2024年1月31日,UTC12时刻未来24小时逐小时历史预报数据,经纬度为23N-28N、116E-121E,格式为.nc。选择字段包括:

风电场位置提取
由于题目并未给出各海上风电场的具体坐标,因此外部数据使用的关键在于找出题目中风电场对应的经纬度位置。部分选手采用地图及搜索信息的方式,我们采用相关系数法提取位置(相对自动)。具体而言,由于对于风电出力而言风速是最重要的量,因此我们将外部数据中每个坐标网格的风速与题目给出的每个站点的风速数据进行相关系数计算,将取得相关系数值最大的经纬度作为外部数据中该站点的真实位置。更细致的可以对网格中插值,对插值点的风速与题目风速进行相关系数计算,获取更精细的经纬度。
特征工程
本题的特征工程没有太多可以说的,基本都是些很基本的操作,包括u和v方向的速度合成,时间信息提取及一些时序特征(开窗统计和差分)。其实试过不少特征,由于线下不准,抖动厉害,最后也没做出来有效特征。
df[f+'_roll3_mean'] = df[f].rolling(window=3, center=True, min_periods=1).mean()
df[f+'_roll5_mean'] = df[f].rolling(window=5, center=True, min_periods=1).mean()
df[f+'_roll7_mean'] = df[f].rolling(window=7, center=True, min_periods=1).mean()
df[f + '_roll3_max'] = df[f].rolling(window=3, center=True, min_periods=1).max()
df[f + '_roll5_max'] = df[f].rolling(window=5, center=True, min_periods=1).max()
df[f + '_roll7_max'] = df[f].rolling(window=7, center=True, min_periods=1).max()
for d in [1,2,4,7,15,30,50,80]: # 可调整
df[f+'_diff%d'%d] = df[f].diff(d)其他小Tips
- 用时序划分验证集可能会靠谱一点,先用最后一段时间作为验证集获得迭代次数后对全量进行训练,全量训练次数可以稍多于前面得到最优迭代次数。
- 可以尝试分站点和分装机容量进行建模,作为融合模型。
- 对预测值按时间进行均值平滑后处理可以提高分数。