数据湖流批一体性能优化 · 二等奖方案

获奖团队简介
团队名称:炒粉|炒面|跑腿代驾|软件开发
团队成员:贾沛沛(指导老师)、何镇锟(队长)、徐鸿宇、梁湛承、黄文扬、赵翔宇
指导老师贾沛沛毕业于西安大略大学,获哲学博士学位,现于电子科技大学(深圳)高等研究院担任研究员。队长何镇锟,队员均就读于电子科技大学(深圳)高等研究院2021年级电子信息专业软件工程方向。团队成员对大数据方面相关知识有着浓厚兴趣,曾多次合作参与各类赛事,取得了优秀的成绩。
所获奖项:二等奖(A榜第一名,成绩90.4分)
摘要
湖仓一体、流批一体已经成为大数据新一代架构范式。通过在数据湖存储上构建数仓表存储,并支持流批一体写入,能够大幅简化大数据架构、开发流程以及部署运维开销,降本增效。业内涌现出 DeltaLake、Iceberg、Hudi 等数据湖存储框架。而 LakeSoul 作为国产唯一湖仓表存储框架,在元数据扩展性、并发性和数据实时更新能力上有着全新的设计实现和性能优势,也吸引了业内的广泛关注。
湖仓存储框架的流批一体读写性能,是非常重要的指标,关系到数据能否快速、准确的摄入到湖仓之中,并做高效的数据处理分析。本文基于这项需求,尝试异步以及并发等方法,最终通过Spark参数调优以及修改LakeSoul框架源码进行解决。最终取得了良好的效果,以90.4分的成绩获得A榜第一名。
关键词
数据湖,流批一体,LakeSoul,Spark
1 赛题任务
给定数据集,使用 Spark 计算框架(版本 3.1.2),以多个批次的方式模拟流式、并发写入,所有数据写入完毕后全量读取出来。选手可以在 LakeSoul、Iceberg、Hudi 这几个数据湖存储框架中选择一个,可以在保证数据正确性的前提下,通过调优参数、优化代码的方式来优化性能,提升写入速度。最终通过评测参赛方案的读写性能和方案实现的创新性来决定排名。
赛题的主要难点在于对大量数据进行不同类型处理的同时,通过算法克服框架性能瓶颈,在保证数据处理准确性的情况下提升数据处理的速度。
2 整体思路
本赛题任务的本质上是对于给定数据集的主键列进行聚合,并对其他列采取不同的操作,最终保证数据的完整性和准确性。可通过对数据湖框架功能利用以及异步并发等方式提升数据处理速度。
我们队尝试了使用Iceberg以及LakeSoul两套框架,在阅读参考代码时想到使用Spark将数据读取到内存中进行操作,可以实现大幅度提升数据处理速度,但是会陷入Spark性能瓶颈,难以再有进一步的提升。最终通过阅读和修改LakeSoul框架源码,使用LakeSoul框架提供的option操作以及内置的merge操作,将数据Union形成一张大表,通过主键对其进行聚合,结合对Spark参数的调优,得到了最终方案,并取得了不错的效果。
3 数据处理
3.1 数据读取
将数据全部读取并union形成一张大表,在写入时对数据进行处理。
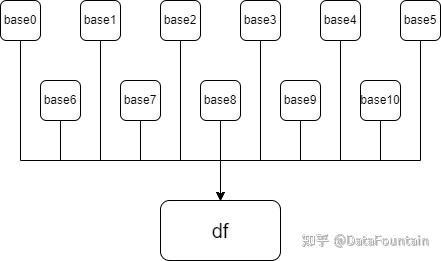
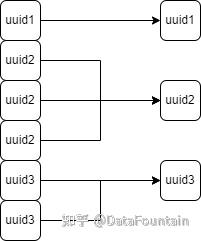
3.2 源码修改
本赛题官方指定了三种数据框架,分别是Apache基金会维护的Iceberg、Hudi,以及元灵数智出品的LakeSoul框架。在经过一个月的对比后我们选择对LakeSoul的源码进行更改。LakeSoul同时支持Merge On Read和Copy On Write两种模式的数据读写,使用LakeSoul的Merge On Read可以优化数据写入性能。通过LakeSoul的upsert的函数可以轻而易举地将需要更新和插入的主键写入数据湖中,在读出数据时,指定自定义的merge算子即可对插入的同一个主键不同版本信息进行处理,得到自己预期的结果。upsert支持delta file文件以Parquet的文件格式写入,主要逻辑代码在TransactionalWrite.scala里。在writeFIles函数中,首先对主键进行重分区,分区数由用户指定。分区根据提供的主键进行MurMurHash散列,对散列后的值和分区数取模,主键对应的列分配到指定的桶中。其后是对表normalize和主键合法性校验,主键合法性保证主键不能为空,由于赛题保证主键不为空,这部分逻辑可以去掉。然后调用Spark的FileFormatWriter的write对主键排序后按照不同的桶进行写入。我们修改FileFormatWriter.write里的逻辑,这里为了方便编译和调试,将FileFormatWriter从Spark源码中抽取出来,放入到与TransactionalWrite.scala同级包中。在对主键排序阶段,由原来的分区列、桶ID以及hash主键进行排序,去掉桶ID的排序。读取过程中的merge操作也移到了写入阶段。原来的写入逻辑是加入SortExec操作并执行物理计划,得到RDD[InternalRow]。然后传入到一个新建的Spark Job,job的每个task对应RDD的一个分区的迭代器,通过迭代器我们可以进行merge操作。因为主键是排好序的,也就是相同的主键挨在一起,当主键发生变化或者迭代器结束后即可以对该主键进行merge操作。在该过程中,依照赛题要求,最后每行数据的name字段保持最新的非null,requests累加,其他字段为最新。因此我们只需要设置最后的键、最后的非空name、最后的累加requests、以及最后InternalRow。此外还设置一个shouldMerge的布尔变量,当其值为true时,表示该键有多个版本需要创建新的InternalRow,对每列填入最后更新的值;为false便直接返回最后的Row。注意每次完成merge操作后,清空保存的临时信息。最后,在DynamicPartitionDataWriter新增writeInBucket函数,由job分配的sparkPartitionID来指定所需要写入的桶ID。
3.3 参数调优
对Spark部分参数进行调优,主要调整分区数、并行数以及内存使用率。
4 总结与思考
本方案基于LakeSoul框架所提供的功能,通过简化一些逻辑判断实现对数据处理的性能实现较大提升,主要特点是由于本赛题的数据量大小并不是限制性能的关键因素。
致谢
感谢CCF中国计算机协会创办本届比赛,也感谢DataFountain提供的大赛平台,感谢专家评委以及工作人员的耐心指导。感谢指导老师给予的帮助,也感谢团队成员之间的团结互助,没有团队之间的沟通交流就不会有后来方法的改进以及分数的提升。
参考
- Spark参数调优,https://www.cnblogs.com/shendeng23/p/15240689.html
- spark中文官网,https://spark-reference-doc-cn.readthedocs.io/zh_CN/latest/more-guide/configuration.html
- spark性能优化,https://zhuanlan.zhihu.com/p/108454557
我是行业领先的大数据竞赛平台 @DataFountain,欢迎广大政企校军单位合作办赛,推动优秀数据人才揭榜挂帅!