
团队简介
赛博赛克(FZU_CyberSec),2019年依托于大数据智能教育部工程研究中心和福建省网络计算与智能信息处理重点实验室基地群组建。此后,FZU_CyberSec先后参加了CCF大数据与计算智能大赛(BDCI)、中国计算机高校(C4)网络技术挑战赛、大数据安全分析竞赛(DataCon)等多项学科竞赛,取得2019年BDCI总决赛一等奖1项,2020年C4网络技术挑战赛国家级三等奖2项、华东区一等奖1项等,在安全大数据智能分析方面积累了良好基础。
摘要
针对赛题提供的无标签、多源异构的大数据平台日志数据,主要采用了知识库、UEBA、机器学习等相融合的技术思路。基于数据分析处理、划分数据子集和安全事件知识库构建,首先采用多种无监督的时间序列检测算法,对划分的数据子集分别进行异常检测;根据异常识别结果,通过细粒度分析的方式,指导规则编码模块提高数据标注的准确性。接着,对少量的标注数据进行半监督学习,训练优化分类模型,实现未标注数据的异常识别。然后,融合细粒度分析与分类结果,完成部分数据的安全事件检测分类。最后,根据上述分类结果构建基于XGBoost算法的安全事件检测与分类识别模型,实现数据安全事件的自动化和智能化实时识别,为企业内部数据的有效管理提供重要支持。
关键词
异常检测、无监督时序检测、安全事件知识库、半监督学习
数据分析处理与安全事件知识库
大数据平台由于管理复杂、安全机制不健全等原因导致平台面临着多种不同的安全事件,不同的攻击类别和以及攻击序列等问题,需要分析大数据平台日志数据的正常行为模式,以及这些安全事件或攻击的特点。因此,对大数据平台下的多源异构数据进行表征统计与规律挖掘,以及对安全事件知识研究,是解决数据安全分类问题的基础。
本节内容通过统计数据日志的宏观表现,识别出可能的异常模式,并针对各类特征的具体数值进行梳理分析与可视化验证,有效地对安全事件日志与正常日志进行分割。进而经过初步的安全事件知识调研,总结出符合赛题背景的安全事件知识库,为后文特征提取、安全事件分类做出有效指导。
1 数据统计分析与处理
用D表示复赛数据集,首先对数据集D的数据分布情况和数据基本信息进行统计分析,结果如图1。
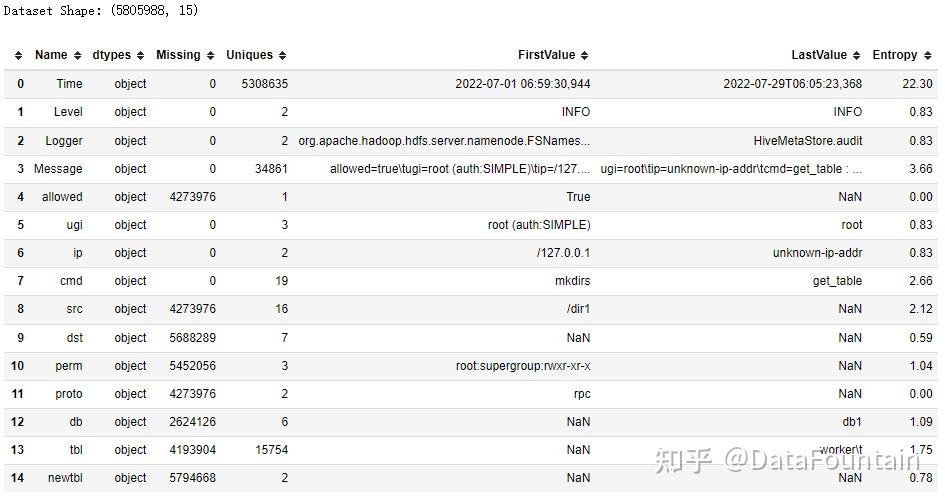
从图1可以看出,数据集D主要由ip为/127.0.0.1和ip为unknown-ip-addr的操作实体产生的日志组成。通过分析,ip为/127.0.0.1的日志在部分字段上有唯一取值,部分为空值,如Level为INFO,db等字段为空,在ugi和proto字段上的熵值为0。ip为unknown-ip-addr的日志在Level等字段上有唯一取值,在allowed等字段上取值为空。
根据赛题提示,将数据集D划分为三部分,分别是数据子集D1(2022-07-01至2022-07-12)、数据子集D2(2022-07-13至2022-07-23)和数据子集D3(2022-07-24至2022-07-29)。其中数据子集D1包含数据删除日志和数据泄露日志,数据子集D2包含SQL注入日志、差分攻击和重标识攻击日志,数据子集D3包含SQL注入日志和加密勒索日志。分别去除三部分数据中取值唯一或全部取值为空、熵值为0的字段。将保留字段进行LabelEncode编码,并进行统计分析,再通过TF-IDF方法对Message字段进行分词处理[1],对特征进一步拓展和衍生。
2 安全事件知识库
为了分析日志数据的正常行为模式,及安全事件的表现特点。我们从攻击的基础概念、行为特征出发,并进一步结合日志数据中明显异常的行为模式,总结出可能的安全事件模式。
首先,从攻击的概念出发,分析攻击可能出现的特点和形式。以SQL注入攻击为例,SQL注入攻击为攻击者在定义好的查询语句的结尾上添加额外的SQL语句,以此来实现欺骗数据库服务器执行非授权的任意查询。进一步,从非法查询的查询频率,查询对象,上下文等出发。我们认为SQL注入攻击可能具有的特点为查询命令连续,查询频率高以及查询对象不唯一等特点。
基于上述,多视角地对赛题中六类安全事件进行深度调研和数据理解,得到安全事件在数据集中可能的表现形式如下:
- SQL注入攻击:在间隔极短且连续的时间段内频繁地对数据库中的表进行访问操作。
- 差分攻击:对数据库中的目标数据表进行查询-更改-查询的固定模式操作。
- 重标识攻击:在一段连续的时间内对数据库中两个不同的表进行重复的信息查询操作。
- 数据删除攻击:在文件系统上获得文件权限后进行越权删除操作。
- 数据泄露攻击:访问文件系统目录中待攻击的目标,获取文件信息后将源文件进行多次的重命名操作,再进行读取操作。
- 加密勒索攻击:对目标数据库中的数据表进行加密操作。
安全事件检测分类
在大数据平台下,由于数据大规模和高度多样性,标记大量数据的成本可能非常高。本节通过无监督时序检测算法对数据日志进行异常检测,识别出可能的异常时间序列,有效地进行对异常数据的标注。随后针对各异常片段进行可视化验证,结合可视化结果和日志数据梳理,确定异常标注的有效性并基于安全事件知识库进一步精确标注的范围。再针对少量的标注数据进行半监督学习,训练分类模型,并对未标注数据进行异常识别。
1 基于无监督时序检测算法的异常识别
基于python提供的ADTK工具库[2],采用多种无监督异常检测算法识别异常的数据序列并可视化。异常数据可视化结果表明了数据异常现象的具体表现形式,由此在验证安全事件知识库的基础上,进一步完善安全事件分类的编码设计需求及合理性。
1.1 ADTK
ADTK(Anomaly Detection Toolkit)是无监督异常检测的python工具包,ADTK提供的主要是无监督或者基于规则的时间序列检测算法,可以用于常规的异常检测。支持离群点、突变和季节性等异常检测。
其中,异常识别和可视化要求为均匀间隔的数据,同时ADTK算法要求的数值为数值类型。因此,首先我们重新编排原时间索引,生成均匀的时间索引或以记录序号。进一步将例如cmd、db和tbl字段及其拼接等的目标特征进行编码(LabelEncoder编码或依据出现频率编码),最后在可视化的时候将纵坐标显示为编码值对应的原始特征值。
1.2 时间序列异常检测
在日志数据中,部分字段信息存在明显规律,我们认为这些规律在时间序列上体现为不同的行为模式。通过时间序列异常检测识别出异常的行为模式,再通过上述安全事件知识库,将识别的异常进行分类,下面对数据子集D1和D2进行检测为例进行分析。
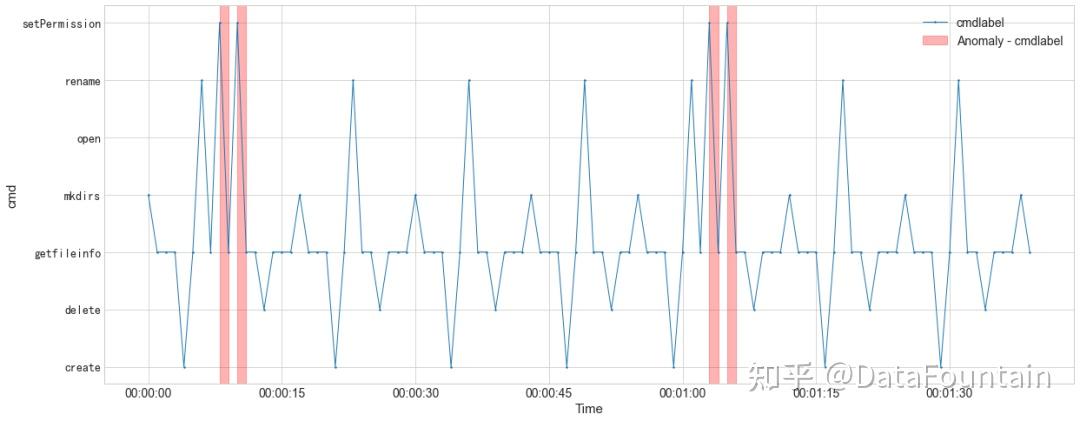
对D1的部分日志着重进行操作命令字段编码分析,采用SeasonalAD算法进行检测异常并可视化。图2为检测结果,可以看出,异常检测结果(红色部分)为delete操作之前进行了setPermission操作。
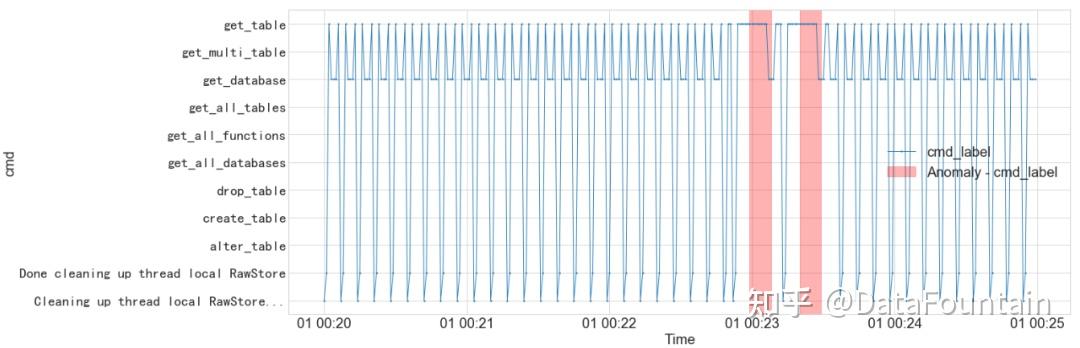
基于安全知识库,着重对数据子集D2字段cmd、db和tbl进行分析。以cmd字段为例,采用VolatilityShiftAD算法进行不同时间窗口的波动检测,得到图3所示的异常检测结果。从图中可以看出,频繁访问数据库的操作序列被检测为异常。
1.3 异常识别与验证
在无监督时序异常检测的基础上,为了确保标注的有效性和标注范围的准确性,我们结合可视化结果和安全事件知识库对标注进行验证。
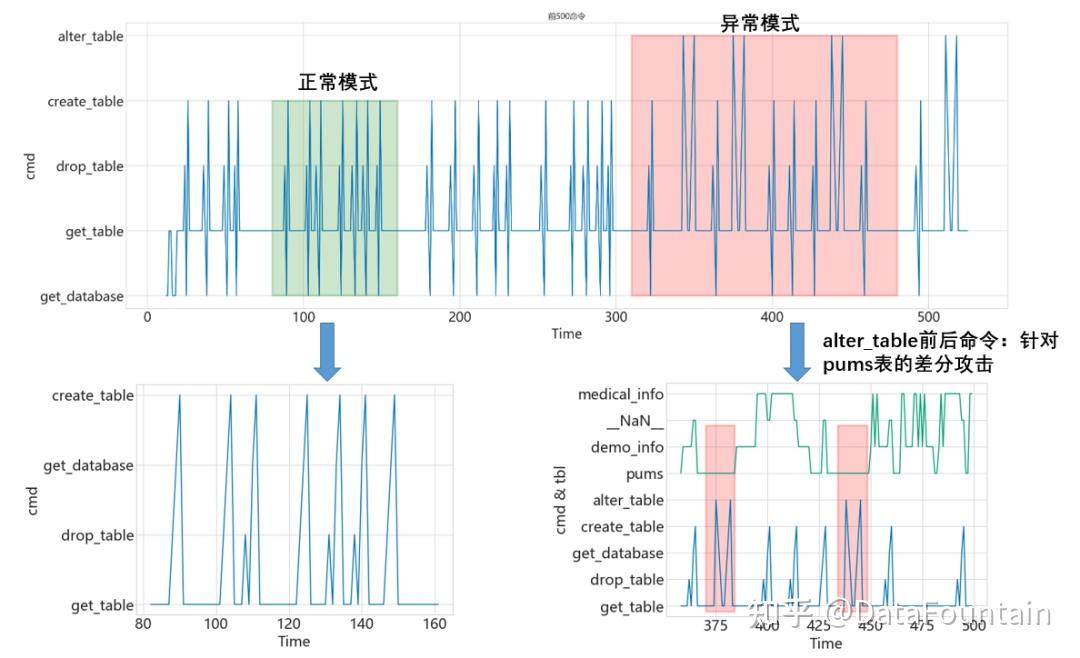
如图4所示,在可视化片段中,可以清晰的看到该cmd命令片段下具有两种不同的行为模式。通过时间序列异常检测能够检测出异常的时间片段(图中的红色标注片段)。但异常检测的精度和有效性仍需进一步验证。
结合安全事件知识库,符合差分攻击对数据库中的目标数据表进行查询-更改-查询的行为模式。进一步地结合数据日志中的具体数据,找到正常模式和异常模式的边界,保证标注的准确性。
2 基于半监督学习的异常识别
解决经典的分类问题,使用分类器训练时需要正样本和负样本。然而,在实际应用中,可能只有少数的正例样本,存在着大量的数据属于无标记状态。因此,解决带有正、无标记样本数据的分类问题的方案,称为PU Learning[4],成为近年来研究的热点。PU Learning中典型的方法是采用bagging的变种形式即PU bagging:
- 随机抽取无标记样本与所有正样本数据组合,创建训练集。
- 将训练集中的正样本当作“positive”,无标记样本当作“negative”。
- 用分类器训练数据集,将分类器用于预测未抽取到的无标记样本即袋外数据,并记录其分别为正负样本的概率。
- 重复上述三个步骤,最后每个样本的预测概率为计算得到的平均值。
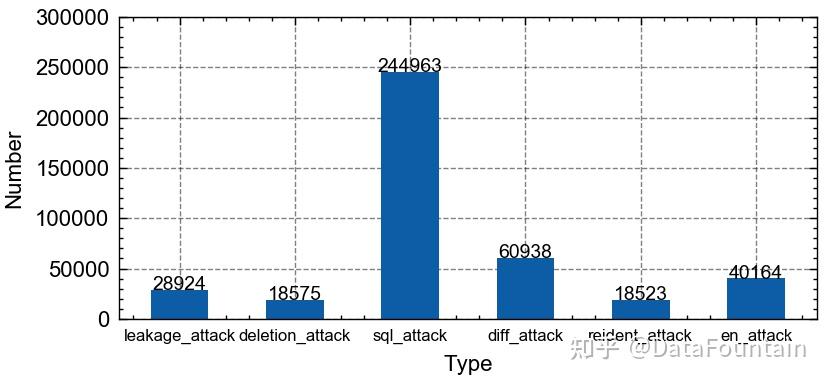
通过上述无监督时序异常检测结果和编码标注结果,得到标注为异常的数据安全事件日志和未标注的日志记录[3]。针对数据子集将相应字段进行编码,分别统计每个字段不同类型的取值出现的次数,并对Message字段进行TF-IDF分词处理。将无标记样本与正样本随机组合,通过多轮迭代计算,由得分阈值划分出正负样本,经过PU bagging的正负样本分类,我们对识别的异常样本进一步划分安全事件类别,最终分类识别的数据安全事件日志分布如图5所示。
安全事件分类模型构建
为了保护企业内部数据安全,防止攻击者的后续攻击,实现对后续数据安全事件的自动化和智能化实时识别,根据此次赛题提供的数据集和上述识别初步标注结果,基于XGBoost算法构建了一个大数据平台安全事件检测与分类识别模型[5]。
XGBoost是boosting算法的一种实现方式。主要是降低偏差,也就是降低模型的误差。因此它是采用多个基学习器,每个基学习器都比较简单,避免过拟合,下一个学习器是学习前面基学习器的结果和实际值的差值,通过多个学习器的学习,不断降低模型值和实际值的差。针对分类或回归问题,XGBoost的效果非常好。
输入数据为此次赛题提供的数据集和上述识别分类结果。经数据统计分析和数据预处理后,输入数据的字段特征分别是cmd, src, dst, perm, db, tbl和newtbl。将上述字段特征进行标签编码,统计每个字段不同类型的取值出现的次数,并通过TF-IDF方法对Message字段进行分词处理。算法采用softmax目标函数处理多分类问题(即multi:softmax),同时设置参数num_class(类别个数)为7。从数据集中划分出训练集和验证集,通过多轮迭代计算,评估模型在验证集上的分类效果(如准确率),从而指导对模型超参数的优化,使得分类模型达到较好的效果。
总结与展望
我们将异常检测和分类识别问题简化为一个多分类问题,并采用无监督时序检测算法和UEBA技术相融合生成少量标注数据,利用NLP等技术对日志数据进行解析形成特征,通过半监督学习的方式对未标注数据进行异常检测,得到了较好的分类效果。方案还有部分需要优化的地方,首先需要优化时序检测算法,使初步标记更加准确。同时对异常检测算法进行优化,针对不同安全事件实现高效的多分类,并形式化建模构造解决框架,实现自动化检测并分类。
致谢
感谢数字安全公开赛赛方提供的宝贵数据和参赛机会,感谢组织人员以及代码审核老师们的辛苦付出。
参考
- 王根生,黄学坚.基于Word2vec和改进型TF-IDF的卷积神经网络文本分类模型[J].小型微型计算机系统,2019,40(05):1120-1126.
- arundo, A Python toolkit for rule-based/unsupervised anomaly detection in time series, https://github.com/arundo/adtk.
- Li S, Yin Q, Li G, et al. Unsupervised Contextual Anomaly Detection for Database Systems[C]//Proceedings of the 2022 International Conference on Management of Data. 2022: 788-802.
- Zhang Y L, Li L, Zhou J, et al. POSTER: A PU learning based system for potential malicious URL detection[C]//Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security. 2017: 2599-2601.
- Chen T, Guestrin C. Xgboost: A scalable tree boosting system[C]//Proceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining. 2016: 785-794.