我们团队都是数据挖掘新手,本次是我参加的第三个大数据比赛,也是第二次在Datafountain平台上获奖(感谢平台..)。这里做一些赛后分享主要面向数据挖掘新手,老鸟轻喷。本次赛题是时序回归预测的赛题,这样的比赛通常有几个大的思路:
1)深度学习模型:LSTM等适合时序预测的变种模型
2)集成树模型:滑动窗口提取特征构建LGB等集成树模型
3)同时涉及时空数据也常有图神经网络来做的,不过这道题的空间信息不太好抽取
4)差分移动平均等一些统计规则模型,在预测数据处于波动区间时往往收益较高,也可以快速提统一个基线方便模型参考
一、赛题解读
原赛题地址:https://www.datafountain.cn/competitions/428/
赛题选取北京市100个不同类别的重点区域,提供各区域历史多天分小时人群密度数据。同时,提供北京六环内历史多天分小时的网格(200*200)人群密度、北京市迁入和迁出指数、网格间联系强度指数。参赛者需要根据这些已知数据,结合自己从互联网上获取的其他任何数据,来预测接下来每天分小时北京市重点区域的人群密度。
这是一道时间序列预测问题,难点在于预测时间跨度长并且由于预测时间处于疫情期间,所以数据波动大,很难训练出一个稳定的模型。
比赛的评价指标采用的是1/(1+RMSE),注意到采用RMSE作为评价指标,那么结果中的较大值对于预测结果的影响会更大,那么对于预测结果中的较大人流量区域(机场等)我们就需要重点关注。
二、初步分析
在人流量指数数据表中为北京各个区域每小时的人流量指数,选择某个细分并对其可视化,如图2.1所示,虽然每天的人数波动明显,但是具有明显的周期性特征。如图2.2所示,在两年中各个省份下每个天的人流量变化趋于平稳。每天中凌晨3/4点是最少的,然后逐渐上升的趋势在15/16点是达到高峰期,然后又下降。
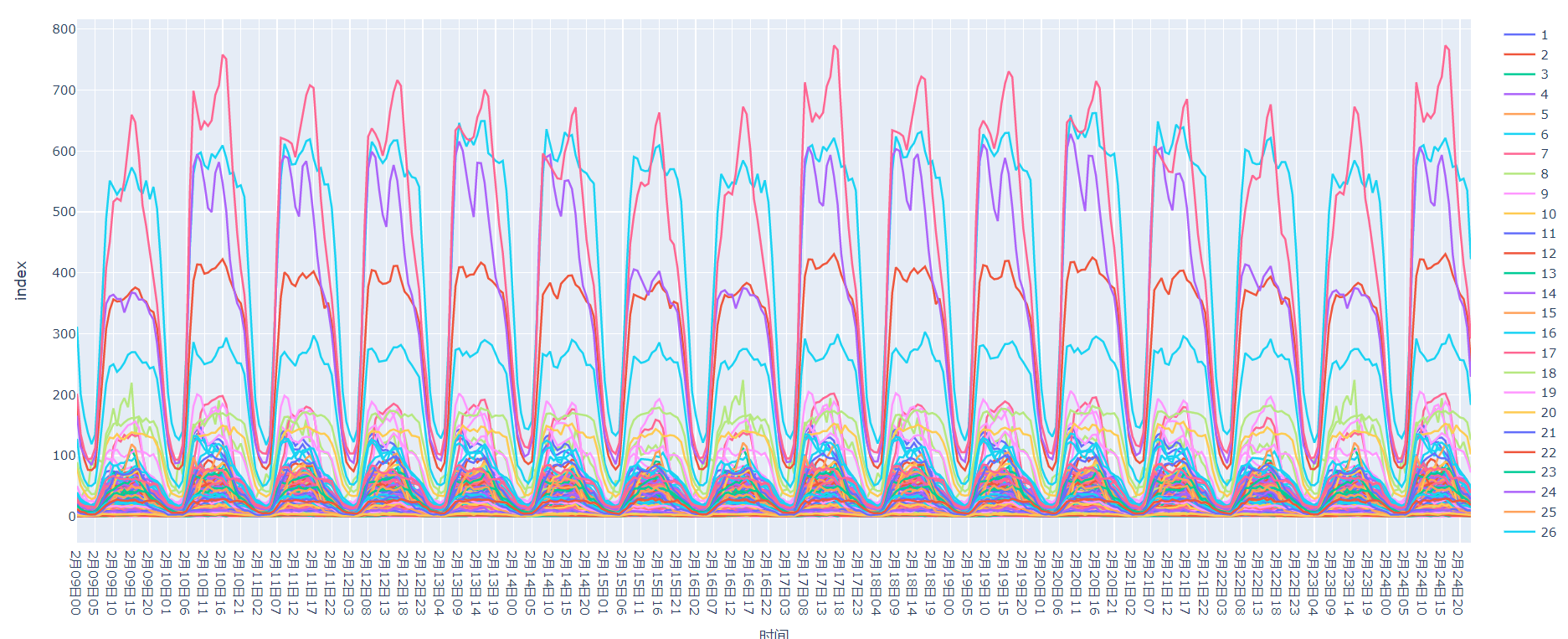
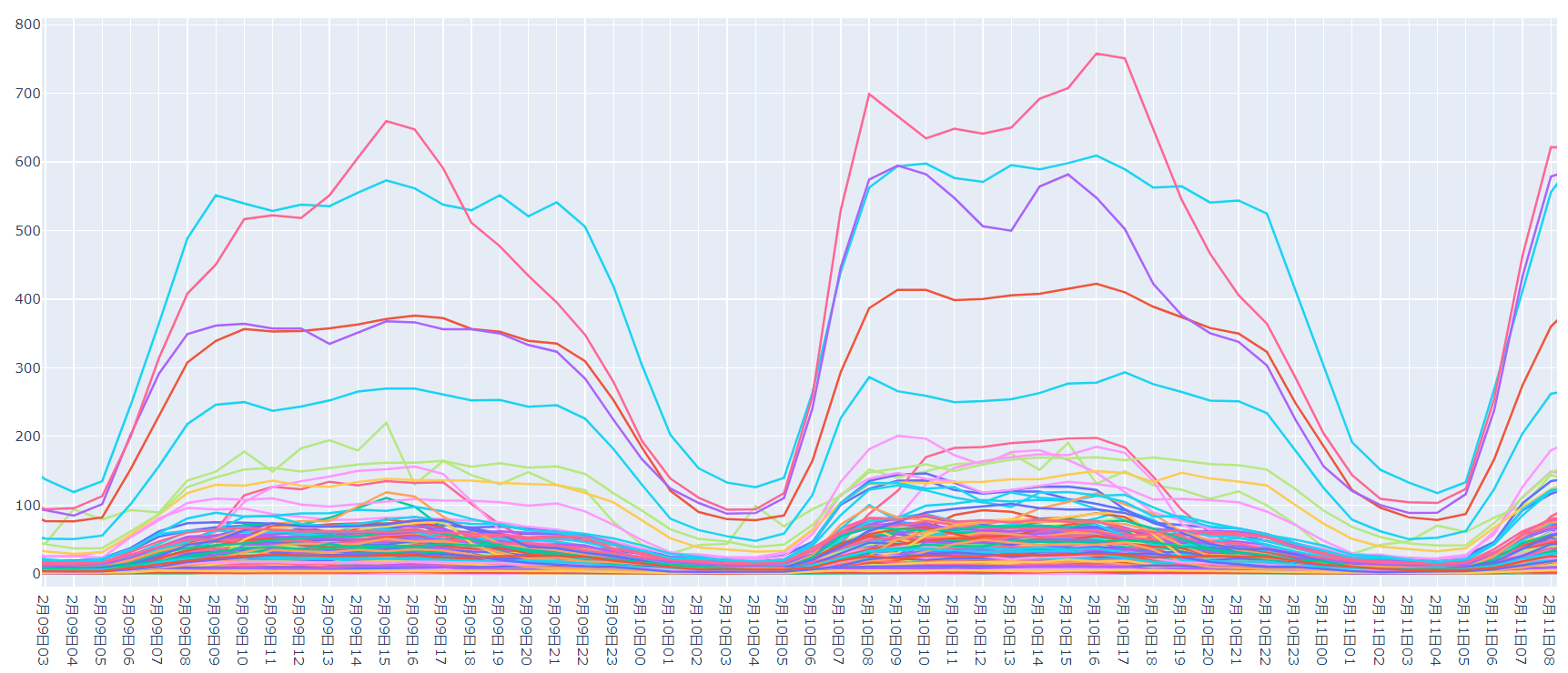
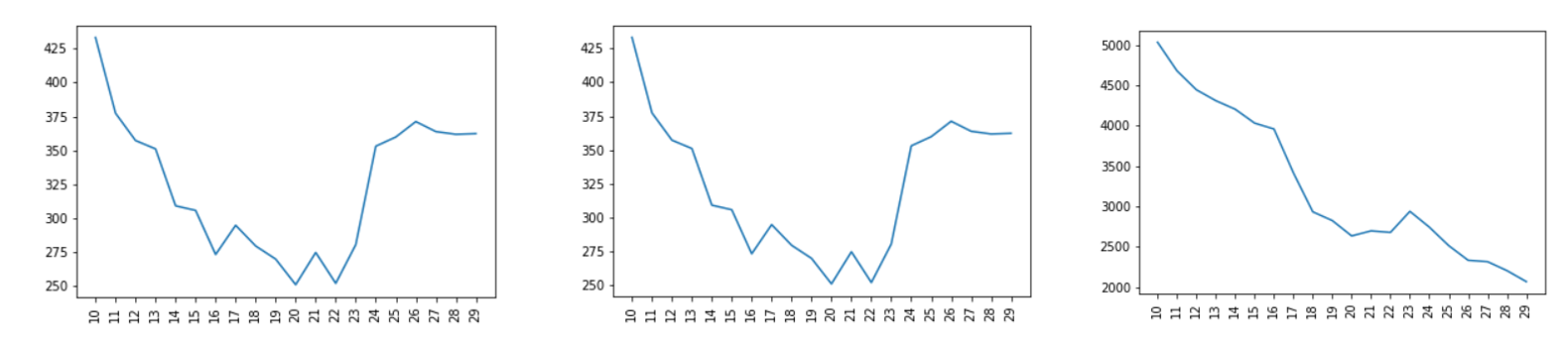
再细化到某一地区的人流量图,从图中可以明显看到1月23日后人流量开始显著的下降,这也和疫情大面积散开的时间相符合。并且整体的趋势是下降的。
同时注意到,在1月27号前是离京高峰,之后趋于平稳,这部分波动数据影响较大,在建模时应考虑去掉或者做以区别。
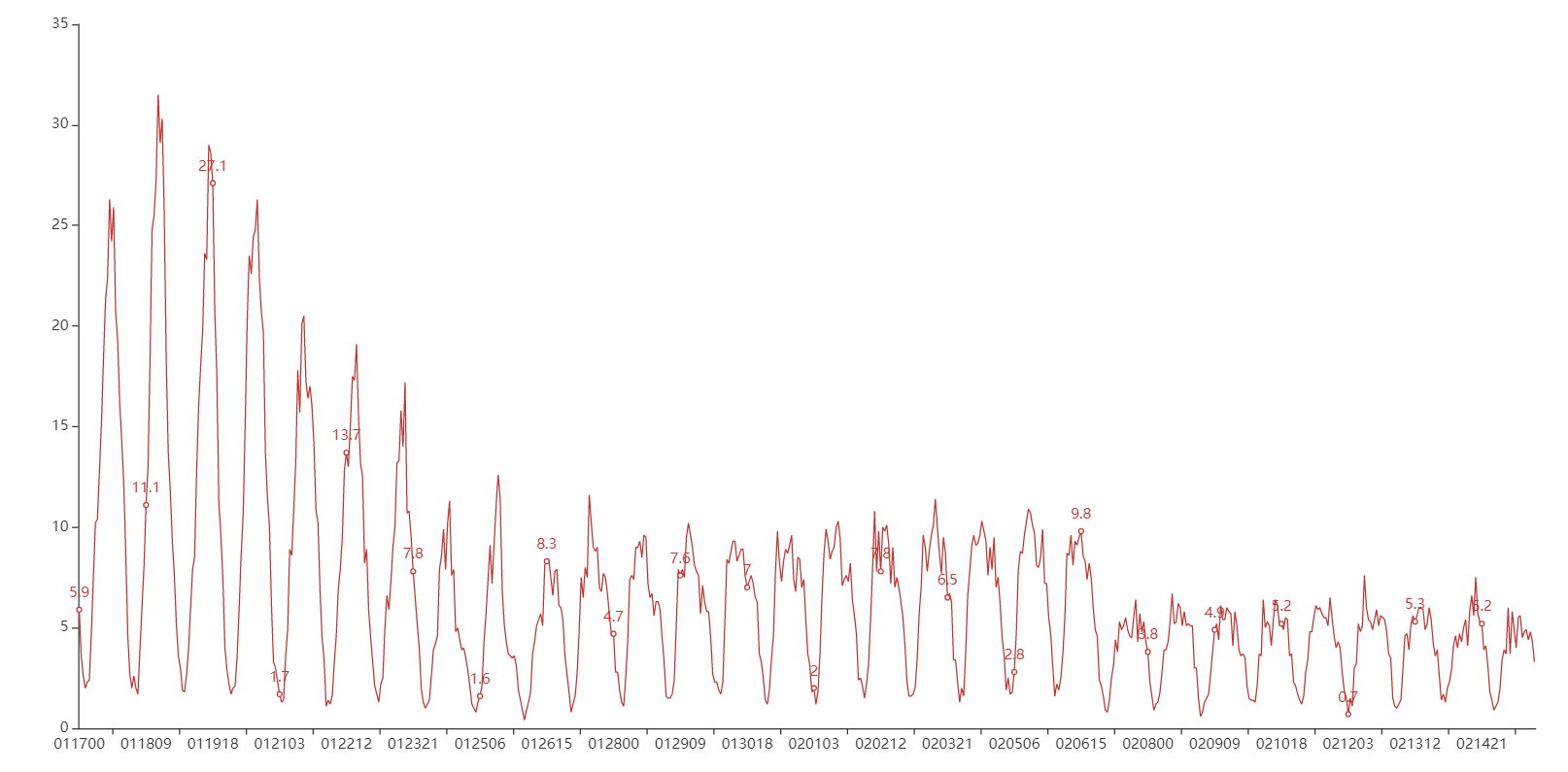
另外我们通过进一步可视化可以进一步发现,不同地区人群密度,在一天的时间内变化规律较为明显,存在一个天的周期性。
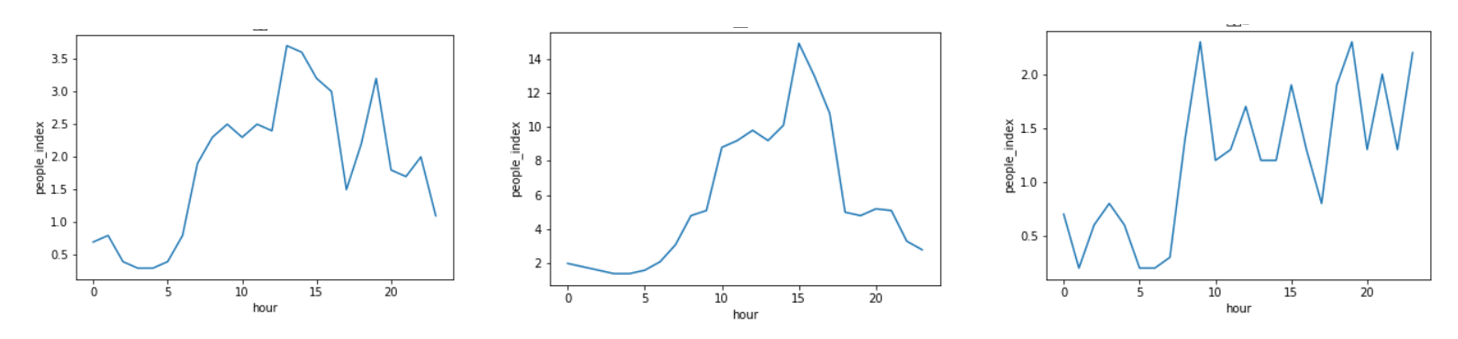
不同地区的人群密度变化趋势明显不同,但主要呈现出一直下降或是持续下降后上升两种趋势,但都远不能达到离京高峰期的密度。
三、模型建立
1)统计规则模型
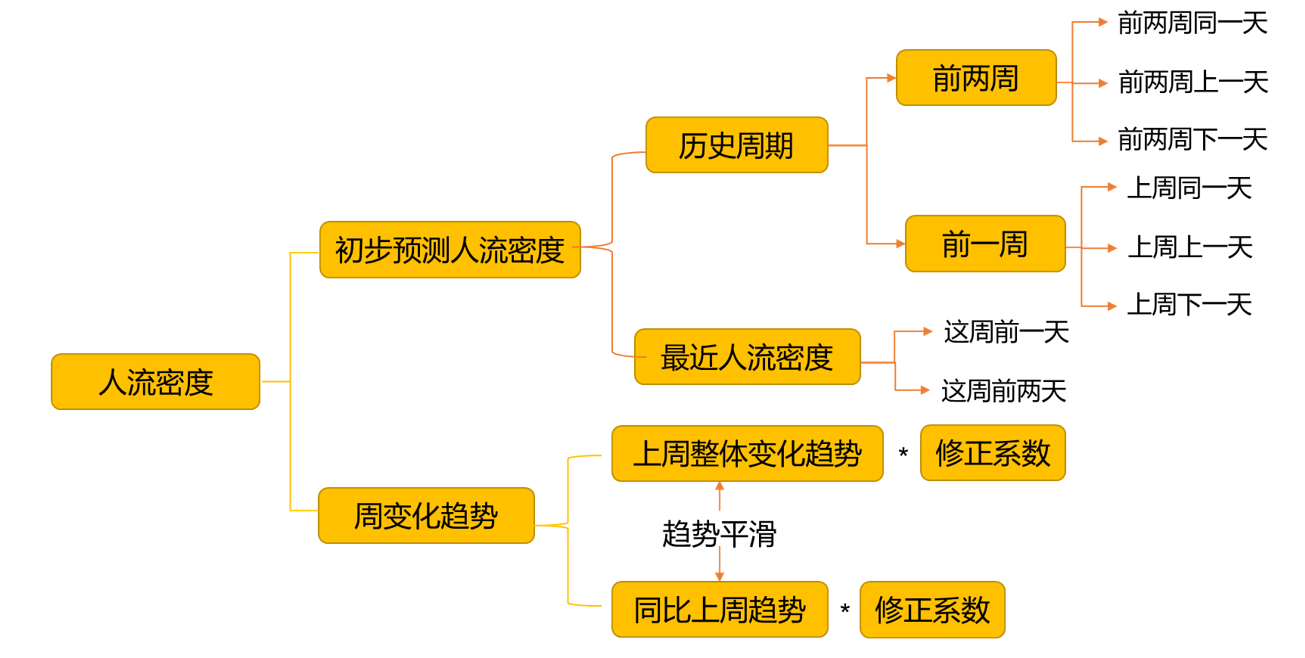
获取历史周期的平均人群流量密度和最近人群流量密度加权合并,分别乘以周期整体趋势和同比趋势,并将趋势变化过大的进行平滑(平方根处理),整体轻微上浮修正,最终结果以不同权重合并以此获得人群密度的平稳周期变化。
2)LGB模型
树模型方面,我们主要使用了两种建模方案:
- 从环比同比出发挖掘有效特征,采用机器学习模型一次性预测
- 从实际业务场景出发挖掘有效特征,采用机器学习模型逐天预测
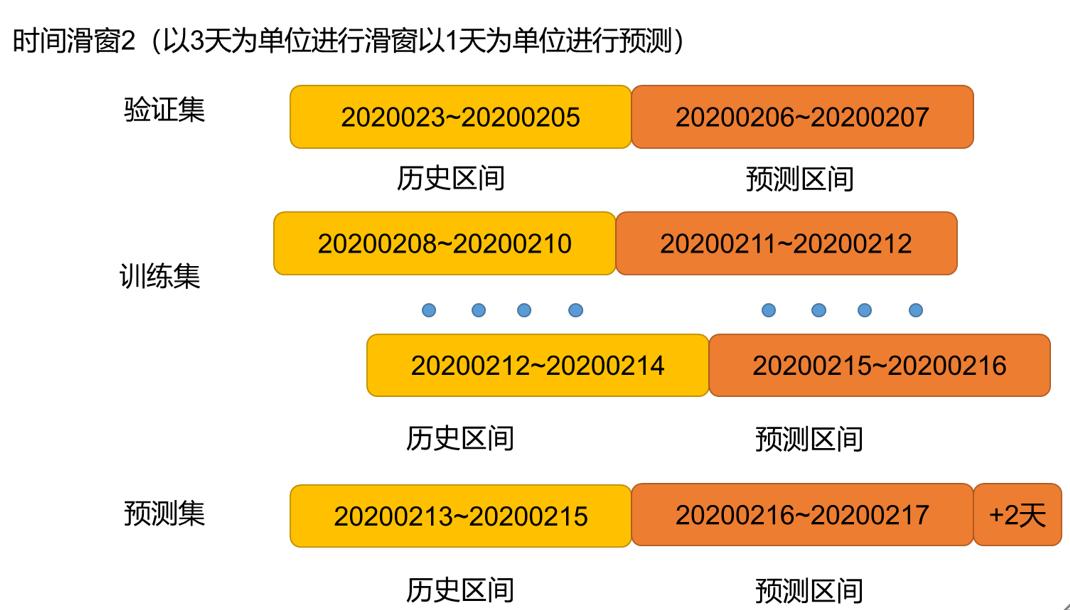
数据划分分别对应如下:

我们一共在北京市重点区域人流量指数、重点区域人流量情况、北京市迁徙指数、北京市分网格人流量指数四个表上进行了特征提取。
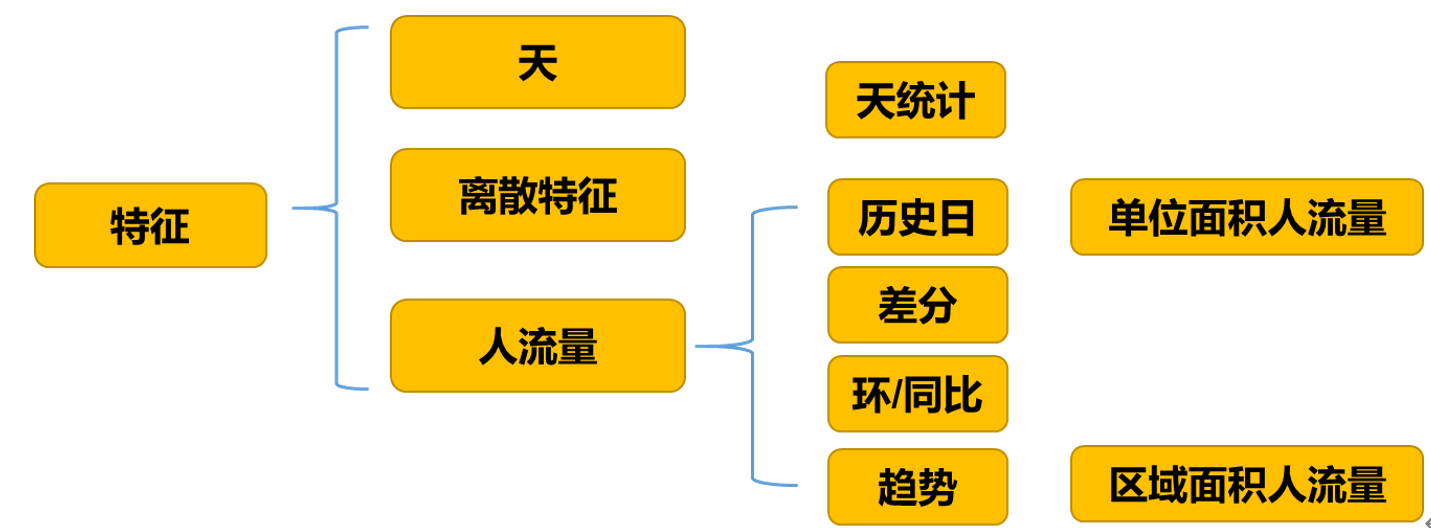
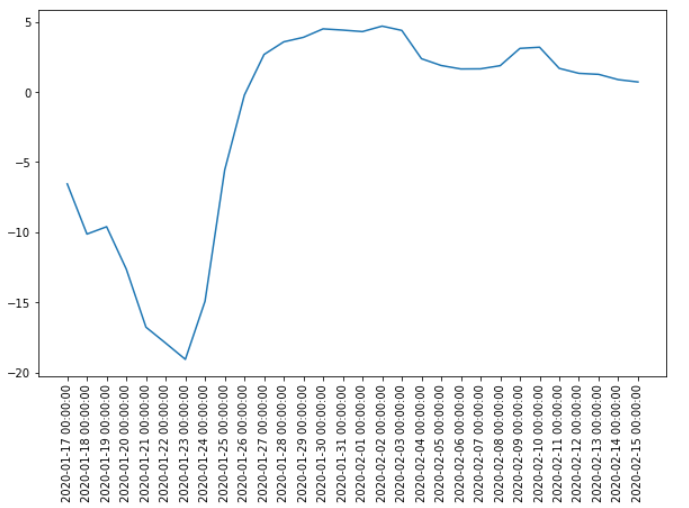
以及为了让模型更能拟合未来数据(疫情前后不稳定),可以进一步将结果可视化进一步分析未来趋势。
最后对两种模型进行加权融合,再与队友的模型融合,不过我和队友之间的模型差异度不高,收益一般,融合前后都是线上第三的成绩。
由于时间原因,我们并没有尝试深度学习方面的探索,以及空间信息上面的特征整合工作还没能深入,这些都是一些需要改进的地方。