第一名 - RAPIDS cuML 堆叠 - 3 层!
感谢 Kaggle 举办了一场精彩的游乐场竞赛。本月的游乐场竞赛拥有一个很棒的数据集,其中包含许多有趣的模式!(感觉更像是真实数据而不是合成数据)。而且有很多强大的竞争对手,这使得这场竞赛既有趣又令人兴奋!
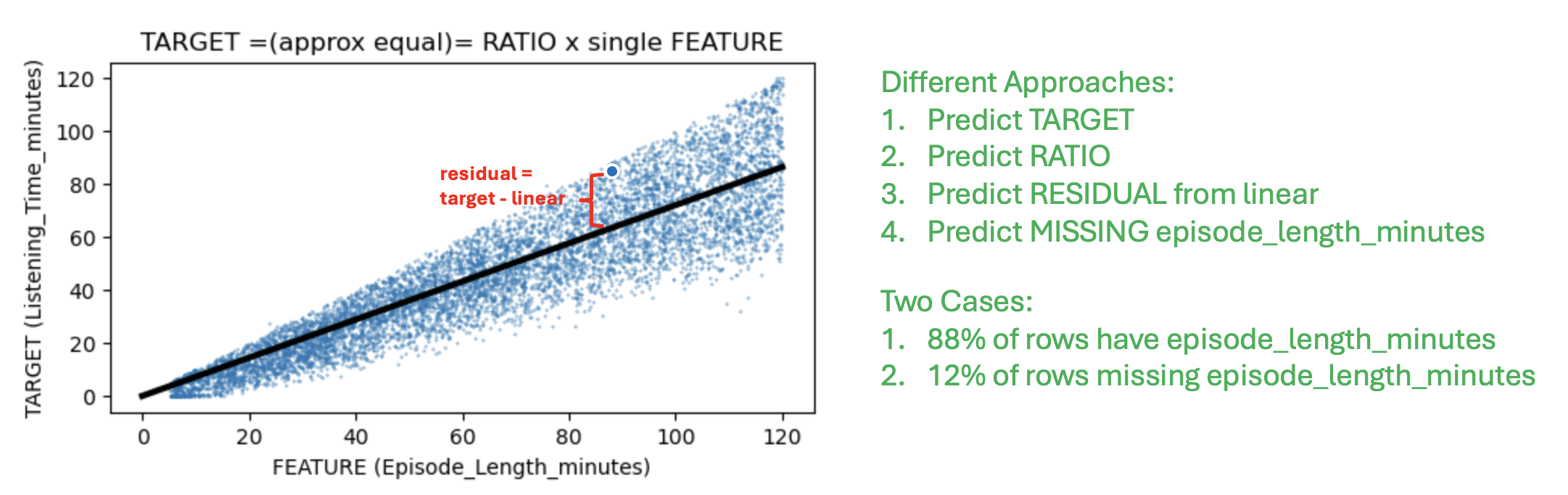
目标变量 Listening_Time_minutes 大约等于线性关系 0.72 x Episode_Length_minutes,正如我在 3 篇讨论帖中所描述的那样:这里, 这里, 这里。其他 9 个特征调节了这种线性关系。基于这一见解,我堆叠了以下方法:
我在 Kaggle 竞赛中最喜欢的解决方案是单一模型,第二喜欢的解决方案是爬山法集成。这两种解决方案都无法在 Kaggle 四月的游乐场竞赛中获得第一名,因为数据包含太多的交互作用和太多的深层模式。对于 Kaggle 四月的游乐场竞赛,我们需要一个大型多样化的深度 RAPIDS cuML 3 层堆叠!
爬山法(线性第 2 层模型)与 堆叠(非线性第 2 层模型)
爬山法(或 ridge)集成通常效果不错。然而在这场竞赛中,数据集非常复杂,以至于深度堆叠是最佳解决方案。最重要的特征是 Episode_Length_minutes。它包含90%+ 的信号。但它对于11.6% 的数据是缺失的!这意味着有两种场景:
- 有
Episode_Length_minutes的情况下预测目标Listening_Time_minutes - 没有
Episode_Length_minutes的情况下预测Listening_Time_minutes
爬山法(和 ridge)无法做到这一点(因为它使用线性第 2 层模型)。想象一下,我们构建一个模型在有 ELM 的情况下预测目标效果很好,我们构建第二个模型在没有 ELM 的情况下预测目标效果很好。爬山法只会对所有预测取加权平均。
但是堆叠(非线性第 2 层模型)将在预测有 ELM 时使用一个模型的预测,而在预测没有 ELM 时使用另一个模型的预测。换句话说,它将不是取所有模型的所有预测,而是针对每种情况取每个模型的最佳预测!
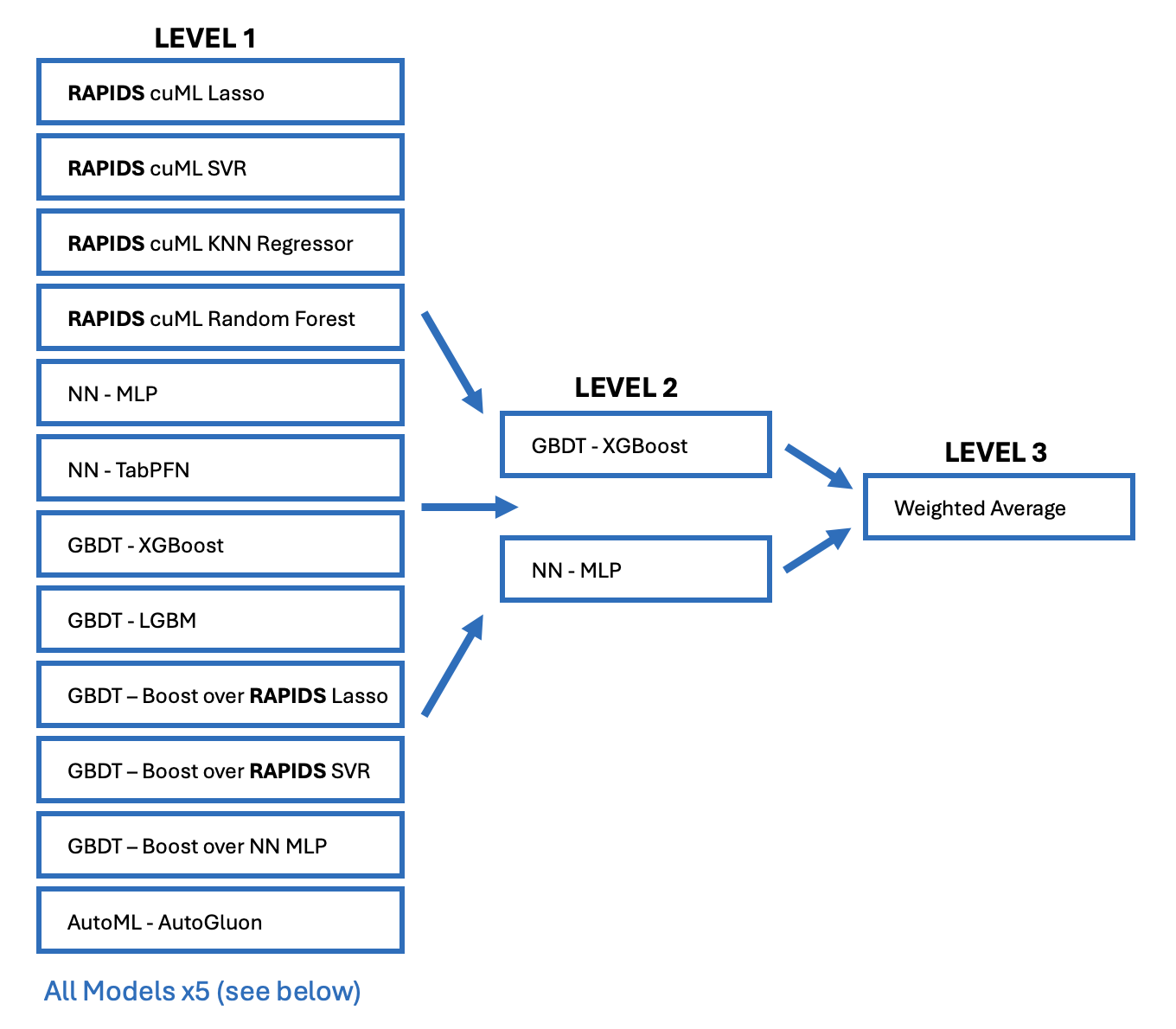
RAPIDS cuML 堆叠 - 3 层模型!
构建强大堆叠的秘诀在于模型的多样性。(并且每个模型都使用相同的 5 折交叉验证训练,我们必须消除目标编码、伪标签等中的所有泄露)。多样性来自不同的特征工程和不同的模型(和/或模型超参数)。
对于我构建的每个新模型,我使用 RAPIDS cuDF 的速度设计了不同的特征集。每个模型都有最适合新模型的定制特征。并且我使用 RAPIDS cuML 的速度训练了许多多样化的模型!以下所有模型都使用 GPU 的速度!
多样性 x5
为了给我们的堆叠增加多样性,我们可以将上述 12 个模型中的每一个至少以下述 5 种不同的方式进行训练。此外,我们可以更改特征工程和/或超参数并以更多方式进行训练。我的最终堆叠使用了75 个模型。所以我大约将上述 12 个模型中的每一个都以 6 种不同的方式创建了!
在四月的每一天,我都花几个小时构建新的多样化模型。使用 3xA100 GPU 和 RAPIDS cuDF 和 cuML 的速度,我每天大约构建一打新模型(带有新的复杂特征工程),并保留那些改进了我堆叠的少数模型!
(1) 不同的特征工程集合
预测 Listening_Time_minutes 的典型方法是使用 KFold 和 train.csv 的所有列训练模型。此外,我们可以通过特征工程创建更多列。我们可以构建多个 GBDT 模型,每个模型使用不同的工程特征。这为我们的堆叠提供了多样性。我们也可以更改 GBDT 超参数。例如,有时我们使用 max_depth=10,有时我们使用 max_depth=0, max_leaves=1024。这些会发现不同的交互作用并创建多样化的模型。此外,有时我们可以使用 max_depth=20 以获得更多交互作用,有时使用 max_depth=5 以获得较少交互作用。以下是在四月游乐场竞赛中训练模型的另外 4 种方法。
(2) 从所有行中移除 Episode_Length_minutes!
基于我在此处的讨论 这里,特征/列 Episode_Length_minutes 很重要。我们可以从所有行中移除 Episode_Length_minutes 并训练一个模型,从所有其他列预测 Listening_Time_minutes。这些模型将在 Episode_Length_minutes 缺失时强有力地预测目标。堆叠将在适当时使用这些模型。
(3) 预测目标除以 Episode_Length_minutes 的比率
基于我在此处的讨论 这里,对于每个模型,我们可以创建一个新目标 train['new_target'] = train.Listening_Time_minutes / train.Episode_Length_minutes。我们可以训练模型来预测这个新目标。然后我们可以将这个预测乘以 Episode_Length_minutes 或下面提到的 Episode_Length_minutes 的插补值。
(4) 预测 Episode_Length_minutes(使用 Train.csv 和 Test.csv)
基于我在此处的讨论 这里,特征 Episode_Length_minutes 非常重要,我们可以训练模型来预测 Episode_Length_minutes。此外,我们可以使用 train.csv 和 test.csv 数据来训练和预测 Episode_Length_minutes。因为 train.csv 和 test.csv 都有所有必要的列。
之后,我们可以至少通过 3 种方式使用这些 ELM 预测。(1) 我们可以用这些 ELM 预测填充缺失值,然后训练模型。(2) 我们可以将每一行的 ELM(缺失和未缺失)替换为这些 ELM 预测,然后训练模型。(3) 我们可以将这些 ELM 预测乘以比率预测(来自上面)来预测目标 Listening_Time_minutes。所有这 3 个想法都将创造新的多样化模型!
(5) 伪标签(使用 Train.csv 和 Test.csv)
基于我在此处的讨论 这里,我们看到许多列很重要。我们可以通过使用 test.csv 中的列来利用更多列中的更多信息。我们可以将带有伪标签的 test.csv 数据添加到我们所有模型的训练中。
堆叠模型 CV 分数
以下是第 1 层、第 2 层和第 3 层模型的 CV 分数( without 伪标签)。LB 分数基本与 CV 分数相同:
| 第 1 层模型 | 备注 | CV 分数 |
|---|---|---|
| RAPIDS cuML Lasso | 使用 6000 个特征! | 13.2 |
| RAPIDS cuML SVR | 使用 6000 个特征! | 13.2 |
| RAPIDS cuML KNN 回归器 | k=51, 按距离加权 | 12.8 |
| RAPIDS cuML 随机森林 | max_depth = 32 | 12.1 |
| NN - MLP | 由 ChatGPT 构建 | 12.0 |
| NN - TabPFN | 20x "SUBSAMPLE_SAMPLES": 10_000 | 13.2 |
| GBDT - XGBoost | 4x 模型带有 4x 特征集 | 11.8 |
| GBDT - LGBM | 与 XGBoost 多样化 | 11.8 |
| GBDT - 基于 RAPIDS Lasso 提升 | 预测 Lasso 残差 | 11.9 |
| GBDT - 基于 RAPIDS SVR 提升 | 预测 SVR 残差 | 11.9 |
| GBDT - 基于 NN MLP 提升 | 预测 MLP 残差 | 11.9 |
| AutoML AutoGluon | 公共 notebook 这里 | 12.4 |
| --- | --- | --- |
| 第 2 层模型 | 备注 | CV 分数 |
| GBDT XGBoost | 使用 73 个第 1 层模型 | 11.56 |
| NN - MLP | 使用 73 个第 1 层模型 | 11.56 |
| --- | --- | --- |
| 第 3 层模型 | 备注 | CV 分数 |
| 加权平均 | 50% / 50% | 11.54 |
致谢: 感谢 @pirhosseinlou 提供的 XGBoost 单一模型 这里 和 @greysky 提供的 LGBM 单一模型 这里,我将它们用作我的 XGBoost"4x 模型带有 4x 特征集”中的两个(然后制作了每个的十几种变体)。并感谢 @itasps 提供的 AutoML AutoGluon 模型 这里。我将所有这 3 个公共模型都 incorporated 到了我的最终堆叠中(通过使用我的堆叠的 KFold 重新运行,然后制作每个的十几种变体)!
最终提交 - CV 11.54, 公共 LB 11.51, 私有 11.44, 第一名!
我最终的 RAPIDS cuML 堆叠具有 CV 11.54, 公共 LB 11.50, 私有 11.44, 第一名!
赛后分析
既然竞赛结束了,我将使用我的 73x L1 模型比较爬山法与堆叠:
- 爬山法 - CV 11.64 - 公共 LB 11.57 - 私有 LB 11.503
- 堆叠 - CV 11.54 - 公共 11.51 - 私有 11.448