单模型获胜!
我在 Kaggle 比赛中最喜欢的解决方案是强大的单模型,而不是大型集成模型。我很兴奋看到一个具有创造性特征工程的单模型赢得了这场比赛!虽然这是一场数据奇特的奇怪比赛,但这是我最喜欢的比赛之一,因为这是一个需要大量创造性特征来解决的棘手谜题!
奇特的比赛数据
正如 这里 所解释的,本次比赛的数据既奇怪又不自然。在这场比赛中成功的技术并不是我们在预测真实背包价格时所需要的。然而,重要的是要注意,这里使用的每种技术都用于其他现实世界的模型中。因此,学习这些技术是有益的。
最终方案
我的最终解决方案是使用 1xA100 GPU 80GB 训练的具有 500 个特征的单模型。然而,使用 Kaggle 的 1xT4 GPU 16GB 训练的仅具有 138 个特征的单模型也获得了第一名。我在此处 发布了这个简单的 Kaggle T4 GPU 解决方案。
特征工程
在这场比赛中取得成功的关键是尽可能多地运行实验,尝试尽可能多的不同特征工程想法。为了尽可能快速地进行实验,我使用了 RAPIDS cuDF-Pandas,如我的入门笔记本 这里 所示。在一个月内,我训练了 300 多个 XGBoost 模型,并尝试了数千种不同的特征工程想法!我的最终解决方案保留了最好的想法。下面我列出了我最终解决方案中的一些最喜欢的想法。
Groupby(COL1)[COL2].agg(STAT)
基本的 groupby 统计信息在我的入门讨论 这里 中有解释。我们选择一列 COL1,然后选择一列 COL2,然后选择一个 STAT,如 "mean", "std", "count", "min", "max", "nunique", "skew" 等等。(如果 COL2 是目标列,我们使用嵌套折叠以防止泄漏)。下面是更高级的特征!
Groupby(COL1)['Price'].agg(HISTOGRAM BINS)
我发明这个技术很有趣。我以前从未见过它被使用过。当我们 groupby(COL1)['Price'] 时,我们每组都有一组数字。
下面我们要显示组 Weight Capacity = 21.067673 的直方图。我们可以计算每个(等间距)桶中的元素数量,并创建一个新的工程特征,将这个桶计数返回给 groupby 操作!下面我们要显示 7 个桶,但我们可以将桶的数量视为超参数。
result = X_train2.groupby("Weight Capacity (kg)")["Price"].apply(make_histogram)
X_valid2 = X_valid2.merge(result, on="Weight Capacity (kg)", how="left")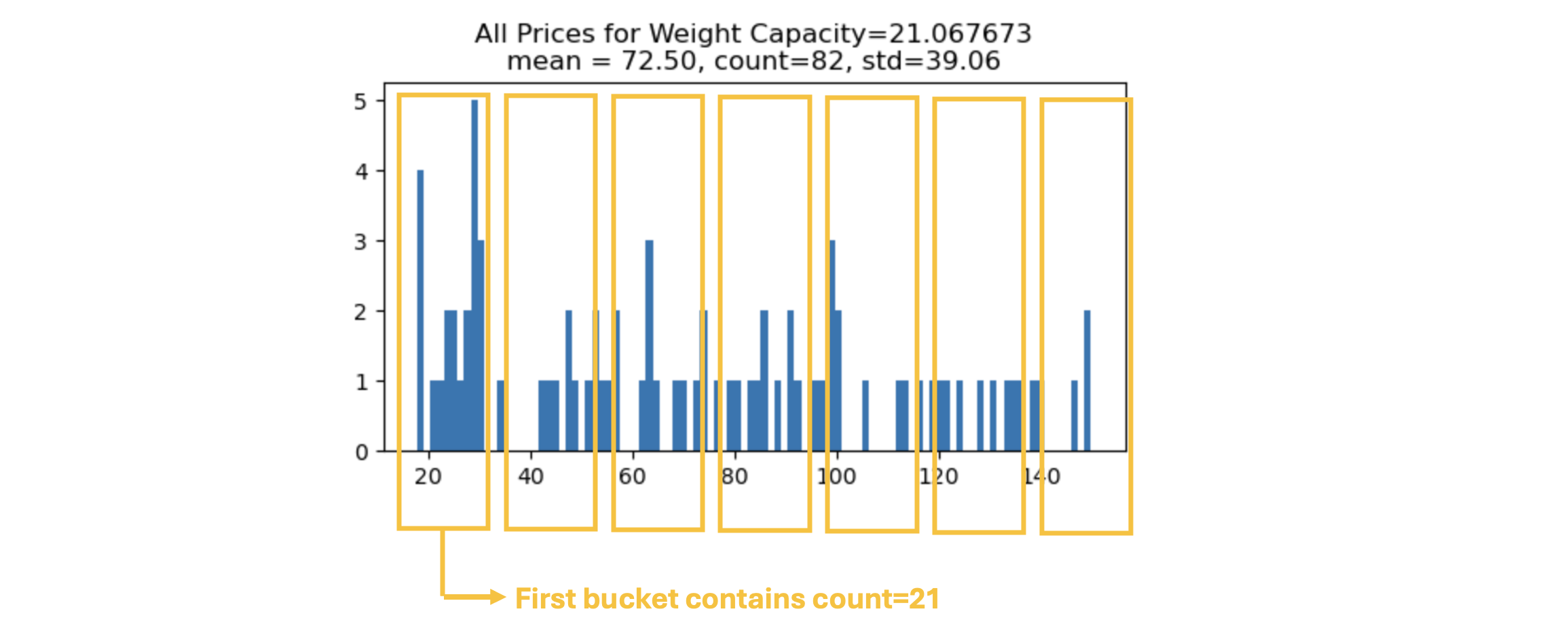
Groupby(COL1)['Price'].agg(QUANTILES)
在 groupby 之后,我们可以计算 QUANTILES = [5,10,40,45,55,60,90,95] 的分位数,并返回 8 个值以创建 8 个新列。
for k in QUANTILES:
result = X_train2.groupby('Weight Capacity (kg)').\
agg({'Price': lambda x: x.quantile(k/100)})将所有 NaN 合并为单个二进制列
我们可以从多列中的所有 NAN 创建一个新列。这是一个强大的列,我们可以随后将其用于 groupby 聚合或与其他列组合!
train["NaNs"] = np.float32(0)
for i,c in enumerate(CATS):
train["NaNs"] += train[c].isna()*2**i将数值列分箱
这场比赛中最强大的列是 Weight Capacity。我们可以通过舍入对此列进行分箱,从而基于此列创建更强大的列!
for k in range(7,10):
n = f"round{k}"
train[n] = train["Weight Capacity (kg)"].round(k)提取 Float32 数字位
这场比赛中最强大的列是 Weight Capacity。我们可以通过提取数字来基于此列创建更强大的列!这个技术看起来很奇怪,但它经常用于现实生活中,从产品 ID 中提取信息,其中产品 ID 中的各个数字传达有关产品的信息,如品牌、颜色等。(想法来自 @jordanbarker 这里)
for k in range(1,10):
train[f'digit{k}'] = ((train['Weight Capacity (kg)'] * 10**k) % 10).fillna(-1).astype("int8")分类列组合
数据集中有 8 个分类列(不包括数值列 Weight Capacity)。我们可以通过组合所有分类列的组合来创建 28 个更多的分类列。首先,我们将原始分类列标签编码为整数,其中 -1 为 NAN。然后我们组合整数:
for i,c1 in enumerate(CATS[:-1]):
for j,c2 in enumerate(CATS[i+1:]):
n = f"{c1}_{c2}"
m1 = train[c1].max()+1
m2 = train[c2].max()+1
train[n] = ((train[c1]+1 + (train[c2]+1)/(m2+1))*(m2+1)).astype("int8")使用生成合成数据的原始数据集
以下特征看起来很奇怪,但它是基于产品的价格基于 manufacturer suggested retail price 的想法。我们可以将创建此比赛的原始数据集视为制造商建议零售价。而本次比赛的数据作为各个商店的价格。因此,我们可以通过让每一行了解 MSRP 来帮助预测:
tmp = orig.groupby("Weight Capacity (kg)").Price.mean()
tmp.name = "orig_price"
train = train.merge(tmp, on="Weight Capacity (kg)", how="left")除法特征
在使用 groupby(COL1)[COL2].agg(STAT) 创建新列后,我们可以组合这些新列以创建甚至更多的新列!例如
# COUNT PER NUNIQUE
X_train['TE1_wc_count_per_nunique'] = X_train['TE1_wc_count']/X_train['TE1_wc_nunique']
# STD PER COUNT
X_train['TE1_wc_std_per_count'] = X_train['TE1_wc_std']/X_train['TE1_wc_count']最终提交代码
我在此处 发布了我单模型代码的简化版本!