第二名 - 堆叠 Transformer 和线性回归
预测挑战
哇,我很兴奋能获得第二名,我觉得很幸运。预测竞赛很难,因为为未来年份(2017、2018、2019)选择正确的乘数对你最终的 LB 分数和排名的影响,比拥有一个能准确预测天数的模型(即周一与周日的区别,或假日与非假日的区别)更大。在这次竞赛中,训练数据可以帮助我们预测天数,但未来年份会发生什么需要猜测和/或假设。
在这次竞赛中,我们获得了 2010、2011、2012、2013、2014、2015、2016 年的销售数据,我们必须预测 2017、2018、2019 年。在每个未来年份,我们必须为每个国家、商店、产品组合每天预测 90 个数字。在我们构建了一个线性回归模型(带有正弦工程特征)并包含了以下影响后:GDP、商店、产品、国家、星期几、一年中的第几天,数据中仍然存在一个未 accounted for 的趋势(数据每年如何变化,如下图所示)。
下面是来自顶级公共 Notebook 的预测误差图。Y 轴是我们需要乘以预测值的乘数(即百分比误差)以匹配真实值。我们看到这个误差范围在正负 6% 之间。那么我们对未来该怎么办呢?
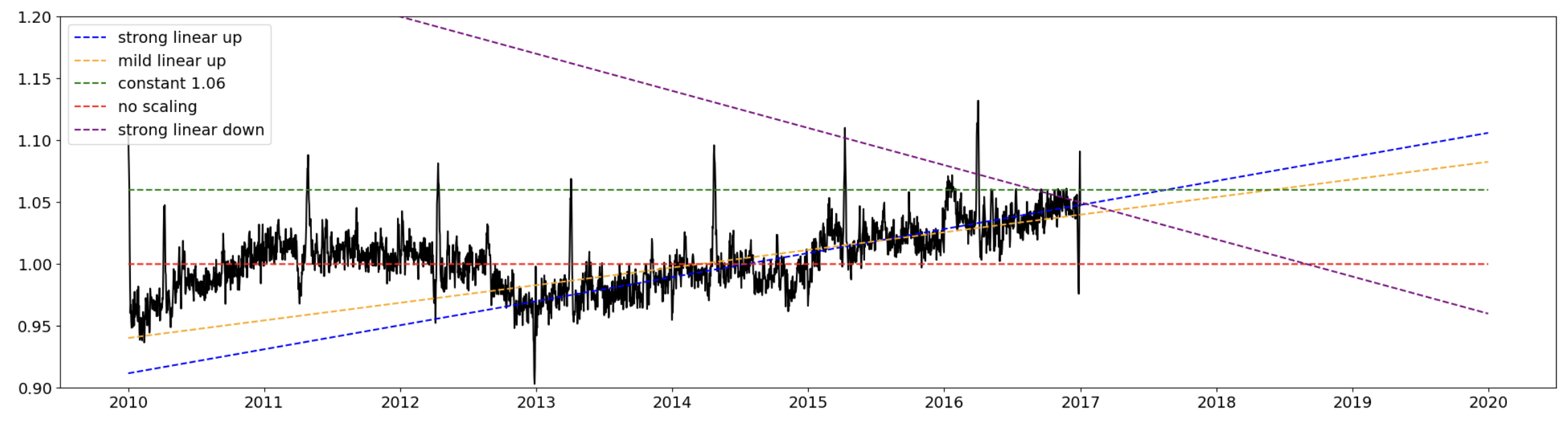
- 我们可以将所有未来预测乘以最后一个已知的百分比误差,即
m=1.06(像流行的公共 Notebook 一样)。 - 我们可以不使用乘数,
m=1.00。 - 我们可以使用线性乘数,随着时间推移增加或减少,
m = 1.06 + slope * (year - 2017),其中 slope 为某个斜率。
上述不同的选项在上图中用虚线表示。未来乘数有很多选择。这就是预测如此困难的原因。如果没有训练数据之外的更多信息,我们无法确定哪个未来趋势是正确的。所以我们只需要猜测。对于我的最后两个提交,我选择了 常数 1.06(绿色虚线)和 温和线性上升(橙色虚线)🤞
仅 Transformer - 公共 LB = 0.04867, 私有 LB = 0.04967 (第 59 名)
仅使用我的公共 starter 这里,我们可以通过以下更改达到 公共 LB = 0.04867,私有 LB = 0.04967 和 私有第 59 名:
- 在所有 5 个产品上训练 1 个模型(15 个 epoch 余弦调度)
- 为 30 个假日添加 30 个布尔特征
- 使用第一次预测(2017,2018)作为伪标签来训练第二次预测
- 使用第二次预测(2017,2018,2019)作为伪标签来训练第三次预测
- 使用 5 个不同种子训练的模型的中位数(用于第 1、2、3 次预测)
- 提交第 3 次预测
- 不使用乘数。Transformer 决定如何处理未来
注意,我们使用了 2 轮伪标签(这是在自回归之外的)。有关伪标签的更多详细信息,请参阅下面的评论 这里。我们还集成了 5 个副本的模型,它们本身是在不同种子上训练的。这两种技术都提高了准确性,并帮助我们在 2019 年私有测试数据的未来获得良好的预测。
仅线性回归 - 公共 LB = 0.04733, 私有 LB = 0.04650 (第 6 名)
从 Konstantin 优秀的公共 Notebook (model 1) 这里 开始,我们可以通过添加假日效应达到 公共 LB = 0.04733,私有 LB = 0.04650 和 私有第 6 名 这里。(参见所有假日 这里)。
- 添加国家假日
- 保持乘数
m=1.06
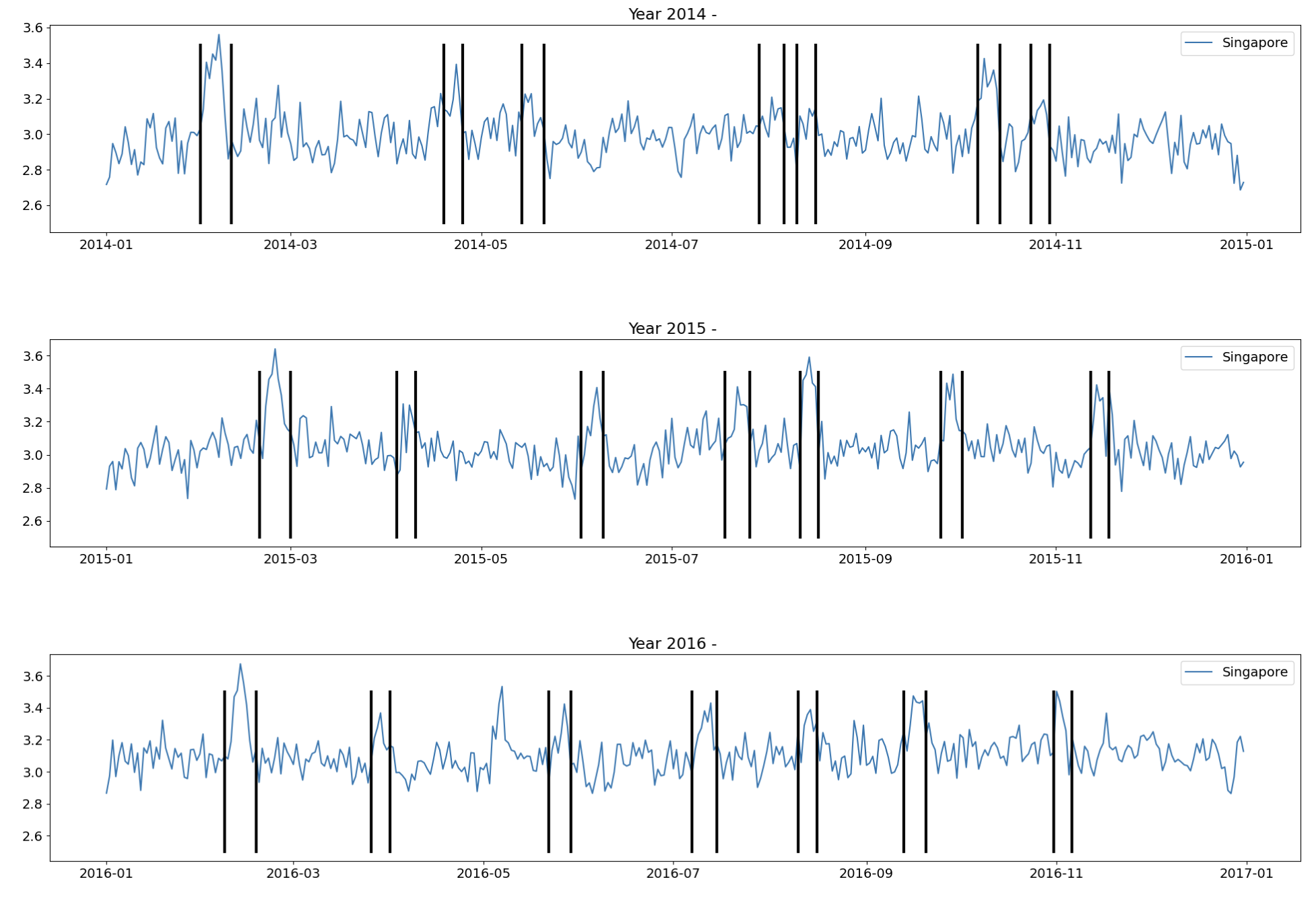
下面是一个如何定位和添加特定国家假日的示例。假日每年可能会改变日期,所以我们进行 EDA 并在假日前后放置黑色垂直线(针对特定国家)。然后我们查看特定国家每年的 2010 到 2016 年,看看销售额是否一致地升高或降低。如果是,我们将此假日添加到我们的模型中。
对于新加坡,我们观察到每年以下 7 个假日的销售额都会升高:春节、复活节、卫塞节、国庆日、开斋节、排灯节、古尔邦节。这 7 个假日显示在下面的 2014、2015 和 2016 年。更多示例,请参阅我的 Notebook 这里。对于线性回归模型,我们提升这些时间窗口。对于 transformer 模型,我们添加布尔特征以便模型可以找到并预测这些假日。
堆叠 - 公共 LB = 0.04526, 私有 LB = 0.04498 (第 2 名)
通过将我的 Transformer 堆叠在线性回归之上来预测残差(误差),我们可以达到 公共 LB = 0.04526,私有 LB = 0.04498 和 私有第 2 名!🎉(堆叠与集成的详细解释见 这里)
Transformer 学习线性回归模型没有学习到的模式。使用两者的最有效方法是在线性回归模型的预测误差上训练 Transformer。所以,首先我们使用线性回归模型预测训练数据 2010 年 1 月到 2016 年 12 月。然后我们从真实值中减去预测值得到预测误差。接下来我们训练 Transformer 来学习并预测这个误差(即我们用 target = 真实值减去预测值 训练 Transformer,时间为 2010 年 1 月到 2016 年 12 月)。最后我们提交两个模型预测值的总和。