第一名解决方案
我想向组织者表示衷心的感谢,感谢他们创建了这次竞赛,不知疲倦地修复匹配系统中的漏洞,并努力确保所有参赛者的公平性。
然而,值得注意的是, leaderboard 直到最后都显得有些不稳定,金牌区的任何竞争者都有可能赢得胜利。
因此,我带着谦卑和对幸运结果的感激之情 presenting 这个解决方案。
结果
- Agent 1: 1259.9 (第 1 名)
- Agent 2: 1228.2 (相当于第 4 名)
猜测者策略 (Guesser Strategy)
认识到表现最佳的 Answerers 可能会实施 Agent Alpha 模式,我决定在我的 Guess 策略中加入它以进行 competitive play。
接下来的问题是,是将“它是 Agent Alpha 吗?”作为第一个问题,还是强制进入 Agent Alpha 模式以减少回合数。
最终,我选择问“它是 Agent Alpha 吗?”,因为它在非 Agent Alpha matchup 中提供了显著优势。这种方法对于从低分区域中少量 Agent Alpha Answerers 造成的“愚蠢深渊 (pit of dumbness)"中恢复是必要的。此外,当位于 leaderboard 顶部但与低分 agent 配对时失败会导致大量的分数损失。
事后看来,鉴于最终的竞争格局,强制 Agent Alpha 的方法可能是可行的。
Agent Alpha
关键词列表: 我使用 Python 的 NLTK 库创建了一个潜在关键词列表(116,937 个名词)。只选择了名词,因为竞赛规定关键词将是“事物 (things)"。
关键词概率估计: 为了优化 Agent Alpha 的奖励期望,我通过考虑以下因素估计了每个关键词出现在测试数据中的可能性:
- 关键词中的单词数
- 使用 英语词频数据集 的英语单词频率
- 使用 GPT-4o mini 估计的“事物性 (Thing-ness)"概率
“事物性”是通过向 GPT-4o mini 询问以下问题,然后获得下一个 token 为"Yes"或"No"的概率来计算的:
"Would the word '{keyword}' generally be considered a thing?"(单词 '{keyword}' 通常会被认为是一个事物吗?)
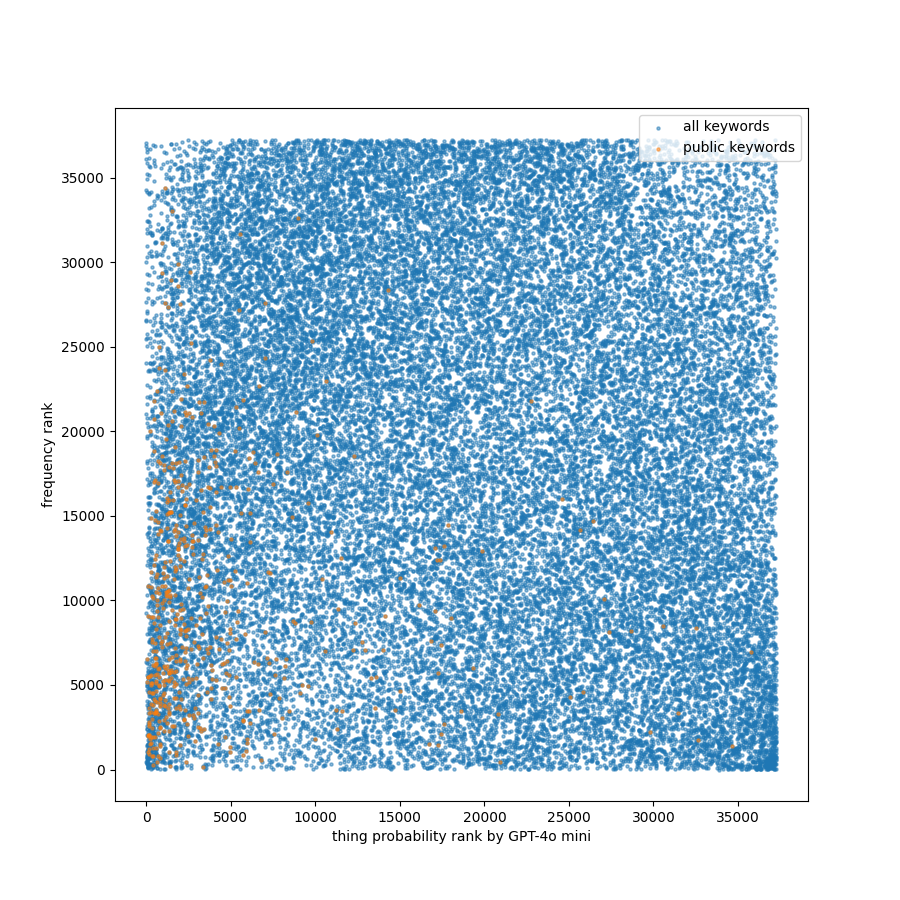
散点图展示了概率计算的影响。公共关键词往往具有较低的事物概率排名(意味着高概率)和较低的频率排名(意味着高频率)。排名和值是倒置的,因为我从高值到低值对关键词进行了排名。
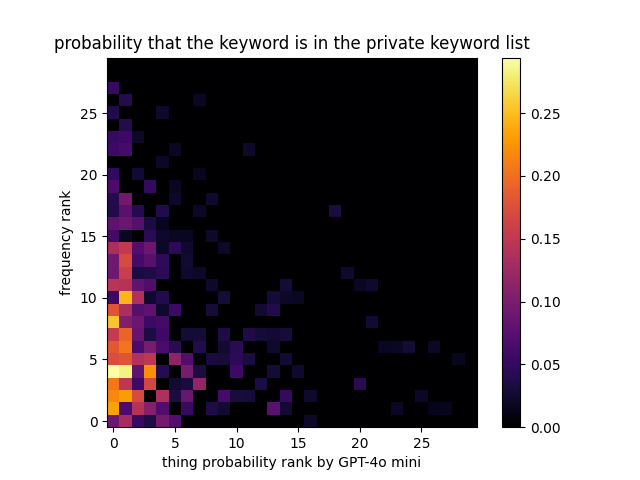
使用这个热力图,我们可以计算每个关键词被包含在私有关键词列表中的概率,基于公共关键词列表与私有列表非常相似的观察。
在实际计算中,引入了平滑因子,但本质保持不变。
对于未在英语词频数据集中找到的关键词(主要是复合词),仅使用事物性来确定概率。
以下是一些示例的表格:
| 关键词 | 概率 |
|---|---|
| towel (毛巾) | 0.222 |
| titanium (钛) | 0.130 |
| chocolate egg (巧克力蛋) | 0.050 |
| axis (轴) | 0.046 |
| mindset (心态) | 0.012 |
| banana boat (香蕉船) | 0.005 |
| toolmaker (工具制造者) | 0.002 |
| celastrus (南蛇藤) | 0.002 |
| ticktacktoo (井字棋) | 0.002 |
确立了每个关键词在私有列表中的概率后,我们可以执行高效的二分搜索,始终将概率缩小一半,而不仅仅专注于关键词的数量。这导致了更高效的搜索。
我的第一名 agent 使用了这种 biased 关键词概率,而第四名 agent 假设每个关键词的概率相等。biased 概率方法的影响体现在 @lohmaa 计算的作为 Guess 者的平均获胜奖励中 [帖子]。
我没有想出不在准备列表中的动态生成关键词,所以向那些做到的人致以热烈的掌声。
自然问题 (Natural Questions)
我采用了一种与 maejimakun 解决方案 非常相似的基于熵的方法,选择最小化预期熵的问题。具体方程请参考他们的解决方案(别忘了点赞!)。
主要区别在于关键词和问题的选择方式:
- 最终列表包含约 35,000 个关键词,按其估计概率排名(如前所述)。它们实际上是以不同方式构建的,但似乎几乎等同于这个解释。
- 使用了三种类型的问题:
- 26 个特定字母的问题(例如,“关键词是否以字母 'a' 开头?”)
- 来自公共 leaderboard 获胜游戏的约 3,000 个问题
- 使用 GPT-4o mini 生成的约 10,000 个问题
为了使用 GPT-4o mini 生成问题,我模拟了比赛,并提示模型创建可以有效区分游戏每个阶段可能关键词的问题。
例如,为了区分"apple"、"banana"、"orange"和"mango",我会问 GPT-4o:
"You are playing the 20 Question Game, and currently have to ask a question to guess the keyword. The current keyword candidates are 'apple, banana, orange, mango'. What question would narrow down the keyword candidates to half? Output only the question."
(你正在玩 20 问题游戏,目前必须问一个问题来猜测关键词。当前的关键词候选是'apple, banana, orange, mango'。什么问题会将关键词候选缩小到一半?仅输出问题。)
典型的回答可能是:"Is the fruit typically yellow when ripe?"(这种水果成熟时通常是黄色的吗?)
为了构建概率表,使用了与 maejimakun 团队类似的策略。使用了三个 LLM(Meta-Llama-3-8B-Instruct, Phi-3-small-8k-instruct, 和 gemma-7b-it)来估计每个关键词 - 问题对的 p(keyword, question)。最后对 LLM 的结果取平均值。
每个 LLM 都被提示:"The keyword is {keyword}. {question} Answer the question above with 'Yes' or 'No'."(关键词是 {keyword}。{question} 用'Yes'或'No'回答上述问题。)概率源自"Yes"和"No"成为下一个 token 的可能性。
鉴于最终表的巨大规模(约 35,000 x 13,000 = 455,000,000),我利用 vllm 进行更快的处理。最初在本地使用 4090 GPU 工作,当我意识到时间紧迫时,在竞赛的最后一周扩展到了 Runpod 上租用的 8x RTX 4090 设置。
这种方法被证明非常有效,当顶部很少有 Agent Alpha Answerers 时,确保了公共 leaderboard 上的顶部位置。计算资源的投资(约 500 美元的服务器成本)被最终结果证明是合理的。
回答者 (Answerer)
对于 Answerer 组件,我采用了双 LLM 方法,利用两个不同的模型来处理不同类型的问题:
- 通用大语言模型:
- 模型:meta-llama/Meta-Llama-3-8B-Instruct
- 目的:处理关于关键词的各种一般性问题
- 专用数学大语言模型:
- 模型:DeepSeek-Math
- 背景:该模型在最近的 "AI 数学奥林匹克 - 进步奖 1"竞赛 中获得了人气,该竞赛专注于使用 LLM 解决数学问题。
- 功能:DeepSeek-Math 接受数学问题作为输入,并输出 Python 程序来解决它们。对于更简单的查询,它提供直接答案而不生成代码。
- 目的:处理关于关键词的复杂、面向数学的问题
DeepSeek-Math 的集成显著增强了 Answerer 处理复杂查询的能力,例如:
- "Does the keyword contain the letter 'a'?"(关键词是否包含字母 'a'?)
- "Does the keyword have two or more vowels?"(关键词是否有两个或更多元音?)
这个专用模型允许对需要关键词内精确字母计数或模式识别的问题进行高精度响应。
模型选择逻辑:
两个模型之间的选择由基于规则的系统确定,主要由问题中是否存在特定关键词(如"letter")触发。虽然这种方法被证明是有效的,但我认为模型选择过程可能还有改进的空间。
最终想法
我非常享受这次竞赛,尽管存在一些挑战,例如评估期间包含公共关键词、分数收敛缓慢以及 leaderboard 顶部分数的持续 oscillation。
正如 @jeannkouagou 所指出的 [帖子],评估期的最后一天特别压力大,难以入睡(竞赛在这里日本时间上午 9:00 结束)。
我很 relieved 竞赛终于结束了,我期待着得到一些应得的休息。
感谢阅读,再次感谢 hosts 组织这次竞赛。
代码
代码可在 此处 获取。如果您想测试 Agent Alpha 但没有 GPU,可能需要在 utils/beta.py 文件中将 device="cuda" 更改为 device="cpu"。