第 16 名 - 离金牌如此之近 😀
我很享受这次比赛!感谢 Kaggle 和 LMSYS!这是一个学习微调和推理大型 LLM 的绝佳机会。
我最近才开始学习如何微调大型 LLM(4B+ 参数),那是四个月前。我在 Essay 竞赛中发布了我的第一个笔记本 这里 (LLM-7B),在 Twenty Questions 竞赛中发布了 这里 (LLM-8B)。然后在 KDD Cup 2024 中练习,解释见 这里 (LLM-72B)。接着开始将我所学应用到 LMSYS 竞赛中,并发布了 starter 笔记本 这里 (LLM-34B)。大型语言模型真是太令人兴奋了!
LoRA/QLoRA 高效训练 LLM
使用 LoRA/QLoRA 允许我们训练 Gemma2-9B-IT 模型,就像它只有 DeBERTa-v3-base 或 large 一样,哇!如果我们微调完整的 Gemma2-9B-IT, 我们需要更新 90 亿个参数。相反,我们可以使用 rank=64 的 LoRA/QLoRA,只微调 20 万个参数(或者使用 rank=16 和 5 万个参数)。
作为参考,DeBERTa-v3-base 有 9 万个参数,DeBERTa-v3-large 有 30 万个参数。LoRA 基于线性代数工作。如果 Gemma2 的权重是 (m x n) 矩阵,其中 m*n=9B,我们保持它们不变,只找到两个大小分别为 (m x r) 和 (r x n) 的 LoRA 矩阵,每个大约 10 万。然后我们的微调模型是这两个矩阵的乘积加上原始基础矩阵。(当然 Gemma2 权重不止一个矩阵,但你明白这个意思)。
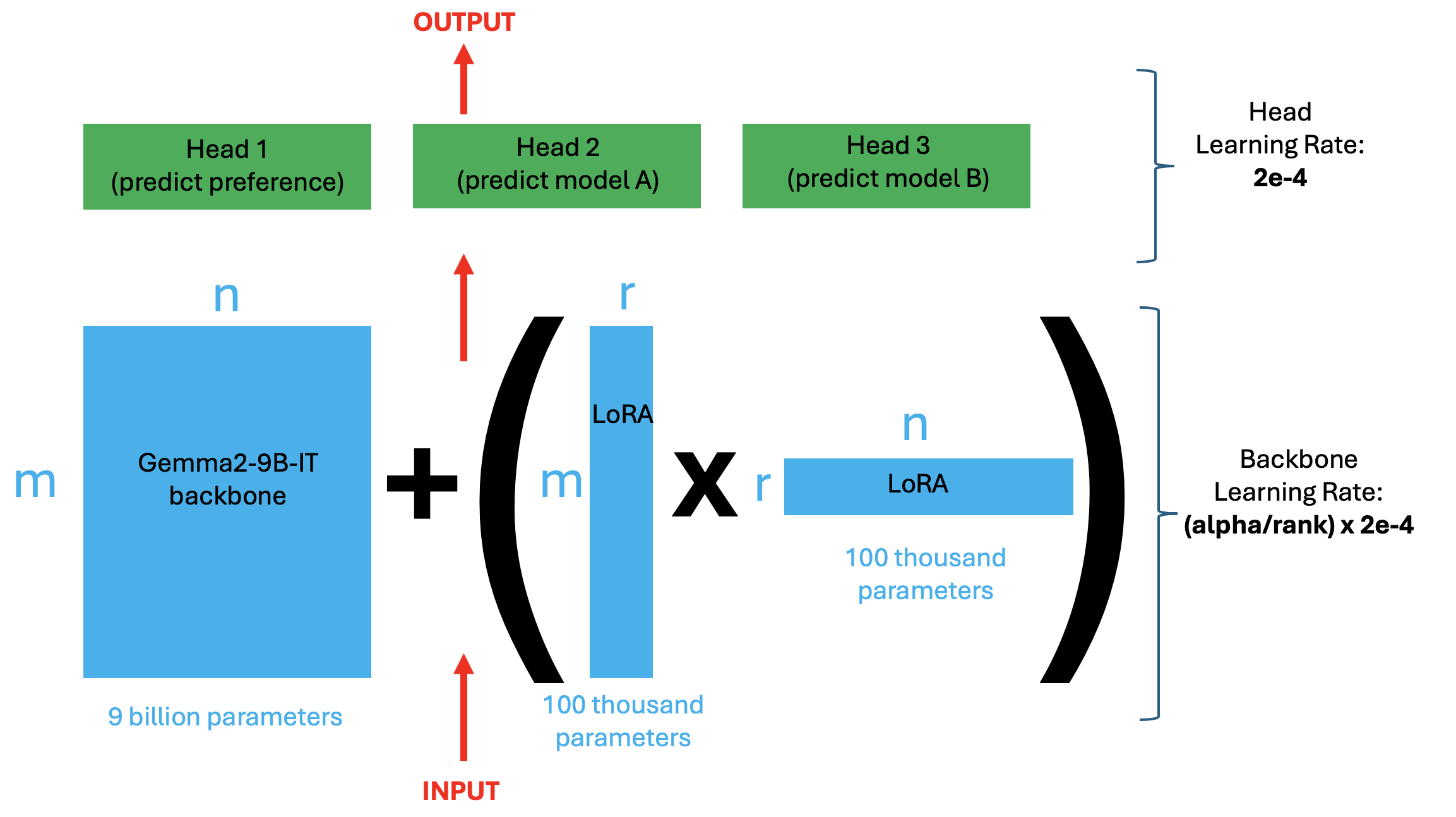
如何调整 LoRA/QLoRA
使用 LoRA/QLoRA 引入了更多需要调整的变量。即我们现在有 r (即 rank), alpha, 和 modules。除了我们 usual 的训练参数 learning rate, epochs 和 batch_size。以下是调整所有内容的策略:
- 首先选择 modules。如果可能,使用所有 modules 将产生最佳结果:
target_modules = ["q_proj", "k_proj", "v_proj", "down_proj","up_proj","o_proj","gate_proj"]. - 接下来选择学习率。这将是模型 head 的学习率。使用
2e-4或2e-5是个不错的选择。使用full batch size = 8也不错(即bs per gpu乘以number of GPUs)。使用梯度累积、梯度检查点或多 GPU 来实现这个batch size。(注意当使用 HuggingFace trainer 的model parallelism时,per_device_train_batch_size实际上是full batch size而不是每设备。另外注意梯度检查点似乎与 HuggingFace trainer 配合不正确)。 - 接下来从
r=16开始尝试不同的 alphas。参数alpha决定了backbone 的学习率 = alpha/rank * head_LR。尝试alpha = 2, 4, 8, 16, 32, 64。训练 1 个 epoch(线性 schedule 带 warmup)。我们现在有了r=16和对应的最佳 alpha。 - 保持我们发现的 alpha 固定,尝试不同的 ranks。上面如果我们使用
LR=2e-4,我们会发现a=4是最佳的。所以现在我们要尝试r=4,a=4,r=8,a=4,r=16,a=4,r=32,a=4,r=64,a=4等(在这次竞赛中,一旦我们找到一个 rank 的最佳alpha,当保持LR(学习率) 相同时,它也是所有 rank 的最佳alpha)。 - 我们通常会发现有一个特定的
rank r分割性能。在这次竞赛中rank<16表现不佳,rank>=16表现良好。(增加到r=16以上通常会带来轻微改进。对我来说使用r=1024比r=16给了+0.002的提升)。
( FYI, 如果我们使用 LR=2e-4 1 个 epoch 线性 schedule 带 warmup,那么 a=4 是所有 rank 的最佳 alpha。如果我们使用 LR=2e-5,那么 a=192 是所有 rank 的最佳 alpha。如果我们使用 LR=6e-5,那么 a=64 是所有 rank 的最佳 alpha)。
多 GPU 训练
使用多 GPU 训练大型 LLM 有助于内存和速度。在这次竞赛中,我使用了 Nvidia 8xV100 32GB GPUs,有时也使用 Nvidia 4xA100 80GB GPUs。感谢 Nvidia 提供的计算资源。
我们需要意识到至少有三种方法可以用多 GPU 并行训练 LLM。搜索关于这些主题的博客以了解更多。我们可以使用:
- 数据并行 (data parallelism)(每个 GPU 都有 LLM 的副本, batches 并行处理)
- 模型并行 (model parallelism)(LLM 分割在 GPU 上,batches 顺序处理)
- 混合并行 (hybrid parallelism)(LLM 分割在 GPU 上,batches 并行处理)

HuggingFace trainer 使用前两种。更先进的库如 Axolotl/DeepSpeed 可以使用最有效的第三种。这些影响我们的训练速度和内存需求。理想情况下,在训练期间我们希望所有 GPU 利用率达到 100%。所以我们可以运行 nvidia-smi 或 gpustat -i 并调整我们的并行代码,直到我们实现最有效的 GPU 使用。
如何用公开笔记本获得银牌
Kaggle 用户 @emiz6413 发布了一个惊人的 starter 笔记本 训练这里 和 推理这里,达到了 LB = 0.941!感谢 Eisuke Mizutani 的分享!只需 few changes,我们就可以将这个公开笔记本提升到 LB < 0.900 银牌!
- 使用 TTA!将
tta = False改为tta = True提升LB 0.941 => 0.926 - 更改 LoRA
r=16, a=32, freeze=16为r=64, a=16, freeze=0提升LB 0.926 => 0.913 - 添加 modules:
["down_proj","up_proj","o_proj","gate_proj"]并使用r=64, a=4提升LB 0.913 => 0.903 - 添加外部
33k dedup dataset这里 并使用100%数据训练 提升LB 0.903 => 0.899银牌!
如何几乎获得金牌(即第 16 名)
从上面开始,我们可以通过以下更新几乎获得金牌(即第 16 名):
- 使用
max=2048训练 vsmax=1024提升LB 0.899 => 0.895 - 更改 LoRA
r=64, a=4为r=1024, a=4提升LB 0.895 => 0.894 - 使用
LoRA train fp16 infer 8bit代替QLoRA train 4bit infer 4bit=> 10% 推理速度提升! - 使用
max=3072推理(并通过上面的 8bit 量化避免超时)提升LB 0.894 => 0.893 - 使用两个不同的 Gemma2 进行 TTA 提升
LB 0.893 => 0.891 - 推理 3 个 heads (preference, model_a, model_b 丢弃后两个) 提升
LB 0.891 => 0.890 - 从左侧截断 vs 右侧 提升
LB 0.890 => 0.885几乎金牌!
向左截断而不是向右截断
最大的提升之一来自于从开头(即左侧)截断长文本,而不是从结尾(即右侧):
def prepare_text(self, prompts, responses_a, responses_b):
prompts = json.loads(prompts)
responses_a = json.loads(responses_a)
responses_b = json.loads(responses_b)
rounds = [
f"<start_of_turn>prompt\n{prompts[i]}<end_of_turn>\n"
+f"<start_of_turn>response_a\n{responses_a[i]}<end_of_turn>\n"
+f"<start_of_turn>response_b\n{responses_b[i]}<end_of_turn>"
for i in range(len(prompts))
]
for k in range(len(rounds)):
text = "\n".join(rounds[k:])
if len( self.tokenizer(text)["input_ids"] )<3072: break
return textLLama3.1-405B 作为裁判
我读到研究论文说 LLM-as-a-Judge 的表现与人类相似。所以在比赛期间,我多次尝试使用 Llama3.1-405B 创建合成数据以提高 CV 和 LB 分数。我尝试了 3 个想法,但都没有成功。:-(
在下面的每种 scenario 中,我都采用了 few shot learning。我会向 Llama 展示 10 到 20 个真实训练数据的示例,然后要求 Llama 创建一些东西。除了 user prompt 外,我还会提供详细的 system prompt:
- 向 Llama3.1-405B 展示 15 个示例,并要求 Llama3.1 创建新的训练数据
- 向 Llama3.1-405B 展示 10 个示例和来自
lmsys-1M-dataset的prompt-responseA,并要求 Llama 创建responseB和target - 向 Llama3.1-405B 展示 20 个示例和来自
lmsys-1M-dataset的prompt-responseA-responseB对,并要求 Llama 创建target。本地验证显示 Llama 达到了大约logloss = 0.95,但这些数据没有帮助。
赛后实验
我很好奇想了解我错过了什么才能获得金牌。我将阅读其他顶级解决方案,并尝试将新想法纳入我的最终解决方案,并向 LB 进行 late submissions。如果发现任何能将我的 CV 和 LB 分数提升到金牌区域的内容,我将更新本节!
更新:发布单模型代码
我发布了代码以复现我最好的单模型 CV 0.878 和 LB 0.888(在原始公共 LB 数据上)。共有三个 Jupyter notebooks:
前两个公开 notebooks (1 和 2) 使用设置通过 QLoRA 训练并量化为 4bit,以便在 Kaggle 的 2xT4 16GB GPUs 上工作。如果我们这样做,那么我们只能使用 max token 2048 进行推理, achieve LB 0.889。如果我们在离线训练这些 notebooks,我们可以更改设置使用 LoRA 并量化为 8bit,推理 max token 3072, achieve LB 0.888。