#3 解决方案 | 多个独立模型与多种集成
首先,我要祝贺所有能够处理这个海量数据集并登上排行榜的人。这绝非易事。接下来,我要特别祝贺前 10 名中坚持到最后一天的所有人。在最后 5 天里,排行榜(LB)发生了相当大的波动。最后,我要提醒排在我下面的那位选手,你们将获得一件 Kaggle T 恤,因为我没有资格领取。
从一开始我就确信所有特征都应该被视为类别型特征(categoricals)。我最初认为 Annual_Premium 的唯一值太多(>53,000),无法这样使用,于是花了 4-5 天时间将该数字减少到 5,000-8,000。显然,这在第一天的解决方案中并没有体现出来,后来 @paddykb 发布了一个笔记本,表明没有必要减少任何变量中唯一特征的数量。我的大多数模型处理的数据都经过了对每个变量使用 OrdinalEncoder 的修改, resulting in 每个特征的唯一值计数如下:
Gender 2
Age 66
Driving_License 2
Region_Code 54
Previously_Insured 2
Vehicle_Age 3
Vehicle_Damage 2
Annual_Premium 55068
Policy_Sales_Channel 156
Vintage 290CatBoost 单独使用时表现最好,但奇怪的是,在模型集成时表现并不那么好。为此,我使用了通过数值优化进行的混合(对于超过 10 个模型来说确实不可行)、Keras、LAMA NNs 和 LightGBM。最后两种在集成方面表现最好。
如果你看看我的个人简介,你会发现我不是一个程序员。在每次竞赛期间,我会创建数百个脚本并在本地运行,它们都没有集成到一个大的流水线中。我喜欢把所有东西分成块并分别运行,这就是为什么如果没有重大努力就不可能在这里复制我的整个过程的原因。我会尝试链接 Kaggle 上已有的相关笔记本,如果周末能喘口气,我会尝试发布至少一个神经网络。我会解释我做了什么,但如果你只对代码感兴趣,请在此处停止阅读。
以下是基于 CV 得分的我最好的 5 种独立模型类型:
| 模型 | CV | 公共 LB | 私有 LB |
|---|---|---|---|
| CatBoost Optuna | 0.896733 | 0.89728 | 0.89699 |
| Keras FM | 0.894276 | 0.89527 | 0.89498 |
| Keras embedding | 0.894192 | 0.89469 | 0.89445 |
| xLearn FFM | 0.893223 | 0.89447 | 0.89414 |
| LAMA ResNet | 0.893647 | 0.89378 | 0.89359 |
当然,我有许多 CatBoost 模型比这里的一些模型更好,但这里仅展示多样性。我还有 3 种其他类型的 LAMA NNs 没有使用,还有一个 xLearn FM 模型,我将在下面解释。根本没有尝试 XGBoost。LightGBM 在使用类别变量时太慢,在我手中没有产生好的模型,但在集成过程中表现得像冠军一样。
其他人已经谈过 CatBoost 和 LAMA,所以我将重点关注中间的 3 个模型。Keras FM 指的是因子分解机(Factorization Machines)的神经网络实现。我们不是通过乘法、除法或其他方式组合特征来创建特征,而是让神经网络为我们这样做。很容易谷歌搜索因子分解机,所以这里是要旨。这些模型将所有特征(无论是数值型还是其他类型)转换为因子/类别,并明确建模它们的交互。它们非常适用于大型数据集,尤其是在推荐系统中,因为它们的速度很快。由于我将所有特征都转换为了类别,因此它是为此类分析量身定制的。以下是神经网络模型的样子:

这在屏幕上看起来很小,建议你右键单击图像并在新标签页中打开,在那里你可以使用放大镜。这是一堆嵌入节点,每个特征一个,它们以点积方式相互交叉。这样做的是从嵌入层获取两个数值向量并将它们压缩成一个数字。然后还有相同特征的线性表示,最后将所有内容连接起来并通过几个全连接层(dense layers)。我还使用了 Dropout 层,但该图像中未显示。下面有一个链接指向描述 Keras FM 的旧脚本,我的实现类似,只是添加了全连接层。
https://www.kaggle.com/code/qqgeogor/keras-based-fm/script
Keras 嵌入的实现类似于 这个笔记本,我很感谢 @paddykb 提出的将所有特征直接转换为类别型想法,而不尝试减少分箱的数量。在我的实现中,当所有特征都是类别型时,Keras 嵌入效果不是很好,但它增加了多样性。当将自编码器特征作为单独层添加到类别型特征中时,它的效果更好 - 见下文。
xLearn FFM 处理场感知因子分解机(Field-Aware Factorization Machines),其精神与 FM 相似,但数据类型编码不同。为了说明它的样子:
https://www.kaggle.com/code/ogrellier/libffm-model
我建议你尝试 xLearn 包:
https://github.com/aksnzhy/xlearn
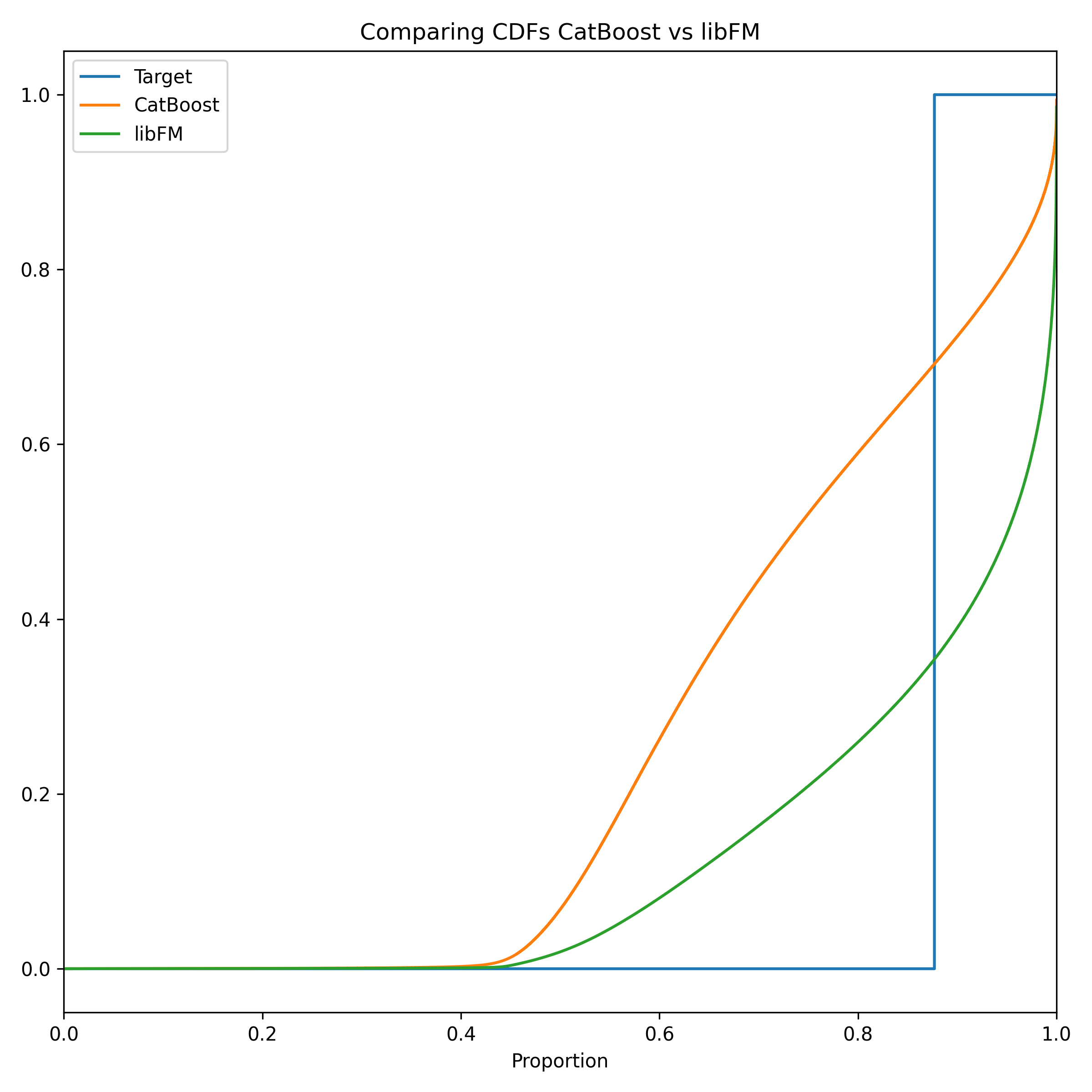
它非常适用于因子分解模型(包括 FM 和 FFM),并且是多线程的 - 非常快。最新版本无法通过 pip 安装,并且在 Kaggle 上不可用,但我认为旧版本应该可以正常工作。最重要的是,这些模型与其他所有模型相比具有极高的多样性,并且对集成贡献很大,即使它们单独表现不佳。 below 是一张显示最佳 CatBoost 和 xLearn FFM 模型的累积分布函数(CDF)的图像。FFM 在预测 0 方面要好得多,而 CatBoost 在预测 1 方面要好得多,这两个模型比我在测试中使用的其他任何两个模型更好地互补。
最后,我通过运行去噪自编码器(DAE)并提取其潜在因子进行了一些特征工程。我在瓶颈层选择了 3 个和 8 个因子,后者效果更好。基本上,我们使用 pd.get_dummies 将类别数据转换为 0 和 1 的字符串。在这里,我使用了 ['Age', 'Annual_Premium', 'Vintage'] 的数值表示并缩放到 0-1 范围,而不是它们的类别型,因为那样会使数据集非常宽。DAE 发现的这 8 个特征本身就具有不错的预测能力,如下面的 t-SNE 图所示。
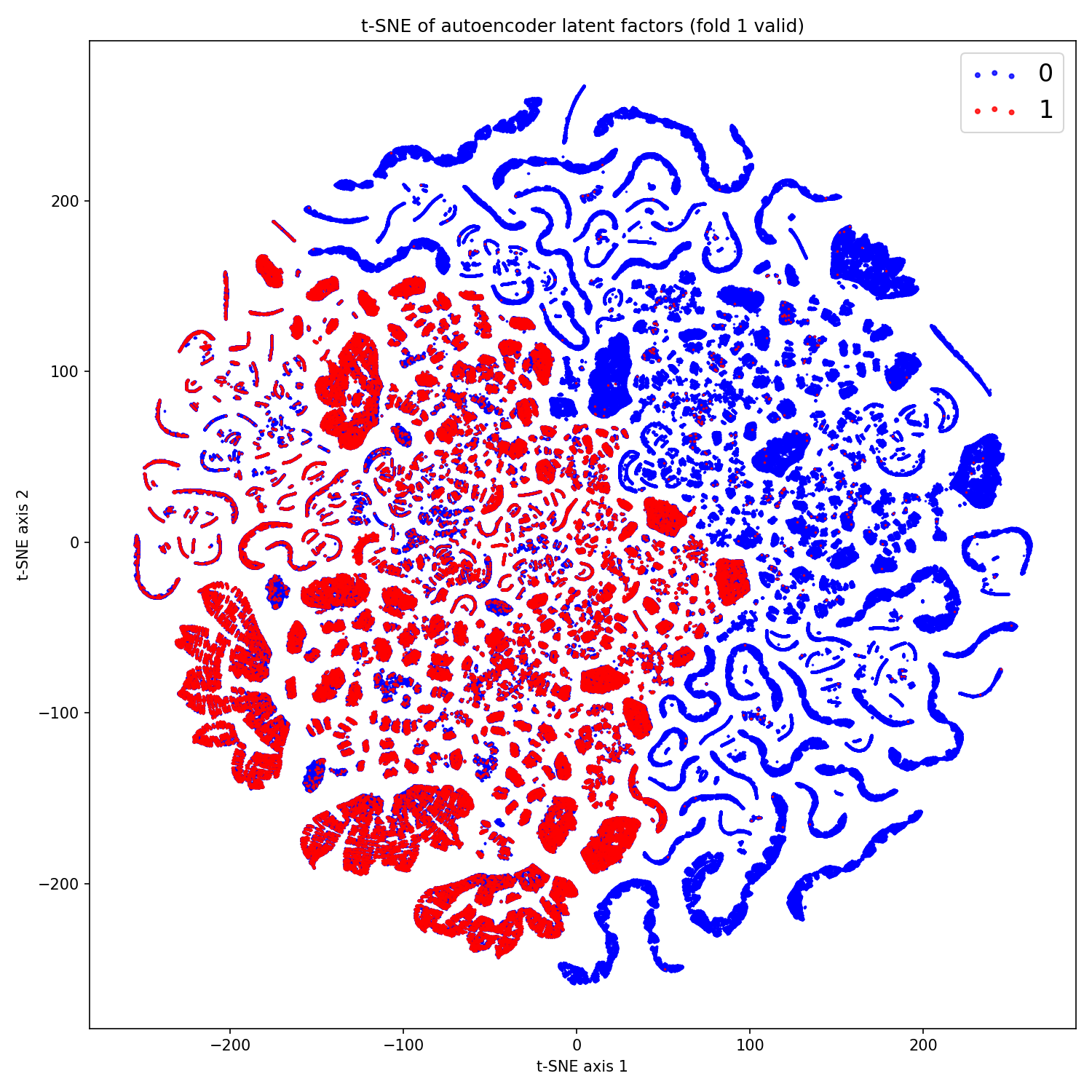
尽管如此,DAE 因子单独表现并不好,当添加到其他特征时效果最好。这排除了 FM,因为有数百万个唯一值且无法转换为类别,但独立的 CatBoost 和 Keras 嵌入模型可以处理这些额外特征,它们的得分提高了约 0.0002。
最终解决方案是由 LAMA DenseLight NN 制作的 38 个模型的堆叠,但 LightGBM 也有几乎相同的解决方案。查看更多详情请点击 这里。至少有 8 个 CatBoost 模型,有些带有 DAE 特征,有些没有。一些模型使用了来自 这里 的特征。还有 6-8 个 xLearn FM 和 FFM 模型,Keras FMs 和 Keras 嵌入模型。我在最后添加了 3 个 LAMA NN 模型,希望我有更多,因为它们肯定会基于与其他模型的多样性提供提升。还包括了几个 AutoGluon 模型。所有这些都使用 Optuna 驱动的 LightGBM 或 10 折 Keras 和 LAMA NNs 堆叠在一起。
我要感谢大家的精彩讨论,以及耐心分享知识,而我有时缺乏这种耐心。特别感谢 @paddykb 和 @ivanmitriakhin 公开了标签反转的信息,这给我们大多数人带来了不错的 LB 提升。