Public 71st 解决方案总结
首先,感谢Kaggle和比赛主办方举办这场精彩的比赛。这是我第一次尝试作为团队成员合作,是一次很棒的经历!因此,感谢我的队友 @patrick0302 和 @chunweishen 的所有支持、讨论和辛勤工作 Also,感谢所有分享宝贵见解的Kagglers,特别感谢 @vitalykudelya 提供的高质量笔记本,我们的最终方案很大程度上基于此。
1. 概述
- 将数据分为3个目标类型进行建模,包括
prod、cons_c和cons_b。prod:is_consumption == 0cons_c:is_consumption == 1 and is_business == 0cons_b:is_consumption == 1 and is_business == 1
- 按照公开笔记本中分享的方式转换目标,并添加
target / eic_count。- 结合目标类型分割,我们使用下表中总结的
model_type训练不同的模型,

- 结合目标类型分割,我们使用下表中总结的
"raw"代表
target,"diff"代表target / target_lag2d,"dcap"代表target / installed_capacity,"deic"代表target / eic_count
- 为每个
model_type训练xgb和lgbm两个版本。 - 为每个模型选择自定义特征集,特征数量在27到55之间。
- 使用3折时间序列交叉验证,验证区间为
202209 ~ 202211、202212 ~ 202302和202303 ~ 202305。 - 从模型池中集成模型,并在最终评估阶段重新训练(稍后详述)。
2. 基础模型训练
如上所述,我们使用自定义选择的特征为每个模型训练。此外,我们使用不同的样本训练每个模型。
数据采样
我们使用以下逻辑对模型训练的数据进行采样,
p_x模型使用所有生产数据,其中x可以是上表中的任何目标转换。c_raw和c_diff使用所有消费数据,模型在cons_c和cons_b之间共享。cc_dcap和cc_deic仅使用cons_c数据。cb_dcap和cb_deic使用所有消费数据。
因为我们观察到使用dcap和deic目标时,cons_b数据会拖累cons_c的性能,所以我们仅使用相同目标类型的数据训练cc_dcap和cc_deic。
特征工程和选择
我们使用的大多数特征来自公开笔记本。除了以下这一个,我们未能创建其他能提升CV评分的特征,
target_lag?d_xpc:跨越生产和消费的普通滞后目标特征。也就是说,我们将生产/消费的滞后目标作为消费/生产模型的特征。
我们相信还存在更强大的特征,期待更多分享!
然后,我们进行了一些实验,验证公开笔记本中的大多数特征可以直接删除。有时候,少即是多。因此,我们使用2阶段方法为每个模型选择特征集。
- 集合式前向选择
我们逐个集合地添加特征(例如,预测天气的局部均值),如果所有3折的CV评分都提升,则保留该特征。对于大多数模型,最终得到的特征集包含70到80个特征。 - 元素式后向消除
然后,我们逐个元素地消除特征(例如,target_lag4d、target_lag5d),仅基于特征重要性。再次强调,如果移除这些特征不会使3折CV评分恶化(逐折而非平均),则删除该特征。有时,我们甚至在这个阶段观察到CV提升。最终,我们得到包含27个(p_diff_lgb)到55个特征的选定特征集。
模型训练和超参数
我们只是在最开始手动调整了超参数(主要是没有early stopping的n_estimators),然后就固定了它们。在提交截止日期前两周左右,我们用最终选择的特征集重新审视了这一点,但未能观察到超参数调整的CV/LB同步。因此,我们回滚到开始时的固定参数。
3. 重新训练和集成策略
模型重新训练
为了弥补8个月的数据差距并使CV设置与最终评估场景保持一致,我们使用以下方法之一重新训练每个模型,
- 开始时重新训练:仅在第一次
currently_scored触发后重新训练模型。也就是说,收集完8个月的数据后。 - 每月重新训练:在每个月的第一天重新训练模型。

为了确定选择哪种重新训练策略,我们比较两种CV设置的CV分数,3折(每折3个月)模拟开始时重新训练,9折(每折1个月)模拟每月重新训练。然后我们为每个单一模型选择表现更好的那个。
模型集成
我们基于以下逻辑集成模型,
- 对于
?_raw和?_diff(其中?可以是p、cc或cb),我们等权重平均它们(例如,p_raw_xgb * 0.5 + p_diff_xgb * 0.5,称为p_ens_xgb)。 - 对于每个
model_type,我们等权重平均xgb和lgbm(例如,p_dcap_xgb * 0.5 + p_dcap_lgb * 0.5,称为p_dcap_xl)。 - 每个模型使用3个随机种子训练。
然后,预测策略描述如下,
- 对于
prod,选择dcap作为基础预测。如果installed_capacity缺失,我们使用raw * 0.5 + diff * 0.5作为预测。如果再次缺失target_lag2d,则仅使用raw。 - 对于
cc,对于训练集中出现的分段,使用d_cap * 0.5 + d_eic * 0.5作为基础。否则,应用与prod相同的预测层级。 - 对于
cb,dcap或deic有不错的CV提升,但无法与LB同步。因此,一个提交使用raw * 0.5 + diff * 0.5,另一个则考虑deic即(raw + diff + deic) / 3。
4. 更多研究
级联或滚动训练集
我们观察到某些模型在使用最近1年数据训练时表现略好,而不是使用到202109为止的所有可用数据。我的问题是,如果两者表现相似,您会选择哪个训练集?
开始时重新训练或每月重新训练
如上所述,我们通过比较2种CV设置(3折3个月和9折1个月)的表现来选择重新训练策略。消费原始模型c_raw的示例如图所示,
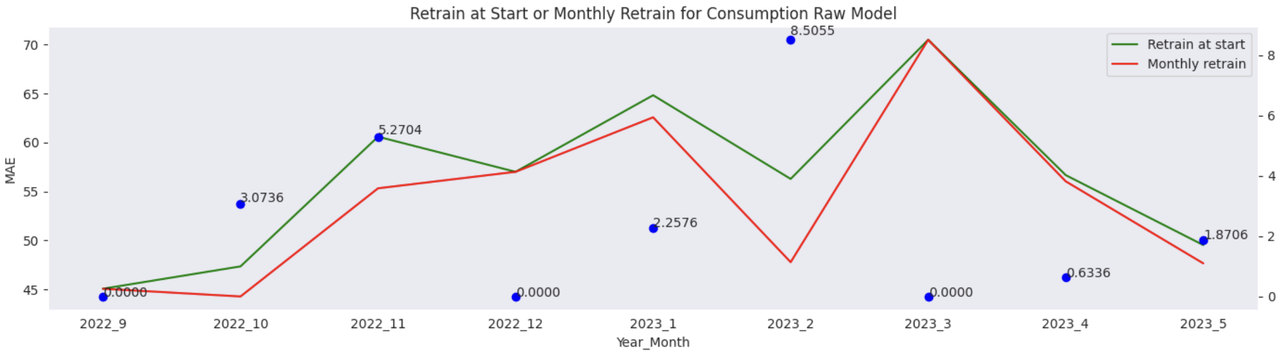
在这种情况下,每月重新训练比开始时重新训练表现更好。随着月份差距增加(从0到2),每月重新训练的性能提升变得更大。
未见分段测试
考虑到私榜中会有新单元,我们测试了哪种目标形式更适合每个目标类型的未见分段。实现方式是在数据分割完成后,掩码训练集中每个县的一个单元。也就是说,我们可以在训练集中不出现的分段上进行验证。
对于prod,我们选择dcap作为基础预测。对于cc,raw * 0.5 + diff * 0.5比基础dcap * 0.5 + deic * 0.5表现更好。并且,对于未见的cb分段,我们使用基础raw * 0.5 + diff * 0.5。
5. 剩余工作
- 我们花了大约3天时间构建一个达到LB 74的单一NN模型,但没有时间继续完善。它基于WaveNet,共同训练24小时的生产和消费,可以视为多步预测问题。
- 我们尝试根据历史误差模式动态选择最佳模型进行预测,但观察到与简单混合相比仅有微小提升。
6. 对我们不起作用的东西
- 生成更强大的特征。
- 调整超参数。
- 为每个模型增加超过3个随机种子。
- 对
cb使用dcap或deic(CV提升很多,但LB不稳定)。