第13名解决方案 - 仅使用Transformer模型

Kaggle Master | 发布于 2024年3月28日
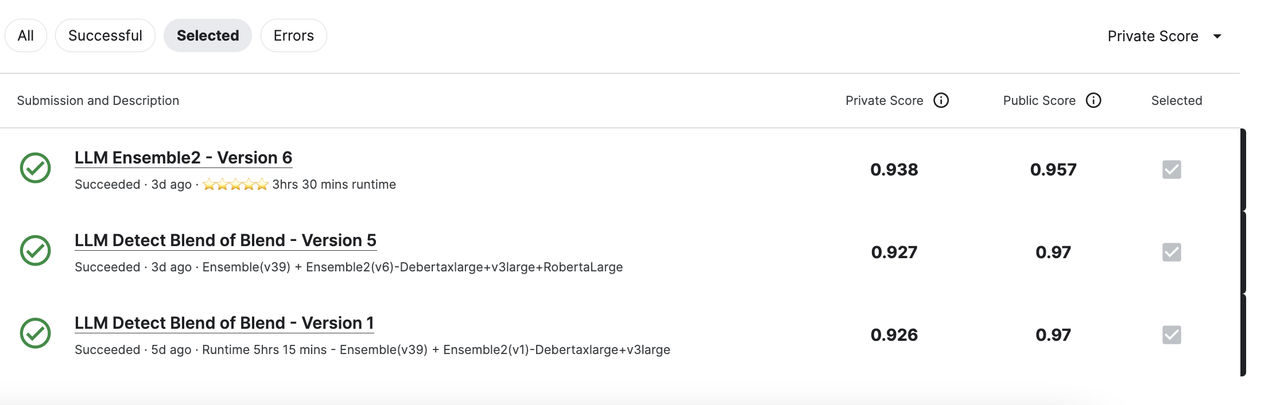
最终得分: 私有榜 0.938 | 公有榜 0.957
获赞数: 26票
我的解决方案
感谢The Learning Agency Lab 和 Kaggle 举办了另一场比赛。
得分情况:
私有榜得分:0.938,公有榜得分:0.957
我最好的私有榜提交也是最终选择的提交(这在公有榜上大约排名2000位)
中选提交(按私有榜得分排序):
数据集
我使用了一些公开共享的数据集。在所有尝试的数据集中,@thedrcat 的 v4 版本数据集对我起到了神奇的效果。感谢 Darek。我也自己生成了一些数据。
以下是我使用的一些提示词示例:
System Message
f"""You are a average non native english speaker grade {str(np.random.randint(6, 13))} student who writes argumentative essays \\
for given context. Essay must be between 450 and 650 words. Assume that essays are written without any help of word processing software. \\
Please add a minimal amount of typos and mistakes as your grade equivalent student would do in a time constraint environment. """
Prompt
'Write an argumentative essay about - Exploring Venus - In "The Challenge of Exploring Venus," the author suggests studying Venus is a worthy pursuit despite the dangers it presents. Using details from the article, write an essay evaluating how well the author supports this idea. Be sure to include: a claim that evaluates how well the author supports the idea that studying Venus is a worthy pursuit despite the dangers; an explanation of the evidence from the article that supports your claim; an introduction, a body, and a conclusion to your essay. 'Persuade Corpus 论文 包含种族/民族/性别信息 - 我尝试将这些信息融入提示词中。同时确保7个提示词类型都有良好的平衡。
我还移除了 persuade corpus 和训练集中存在的重复数据。我使用 `BAAI/bge-base-en-v1.5` 嵌入和余弦相似度来查找匹配项。
最终我的数据集包含约 45K 个样本。
交叉验证
几乎没有进行,除非数据集固定,否则我们无法评估和比较。我经常尝试不同的数据集。在后期我固定了数据集,开始观察小数点后第四位的CV变化 - 但效果并不明显。
模型构建
3个Transformer模型的集成:
| 模型 | 私有榜得分 | 公有榜得分 | 集成权重 |
|---|---|---|---|
| DebertaXLarge | 0.92 | 0.939 | 50% |
| Deberta v3 Large | 0.847 | 0.914 | 25% |
| Roberta Large | 0.849 | 0.923 | 25% |
所有模型使用相同的超参数训练:最大长度=512(更高的长度在公有榜上效果不好),5折交叉验证。
使用 Neptune.ai 进行日志记录 - 首次使用,体验愉快,下次还会尝试。
其他提交方案
我其他中选提交(最佳公有榜得分0.97,私有榜0.927,公有榜排名42)采用了基于TF-IDF的方法,与公开内核类似。我将这些方法与自己的deberta模型集成,公有榜得分提升至0.97。我没有调整TF-IDF模型的超参数,它们来自公开内核,且似乎已在公有榜上被集体优化。不过我对这些模型使用的数据集做了少量调整。一些对Transformer模型有效的数据集在提升/MNB/SGD模型上效果并不理想。因此我为不同模型使用了不同的数据集。
尝试但未成功的方法
- 使用 mistralai/Mistral-7B-Instruct-v0.2 生成数据(在Persuade Corpus上微调后,类似于Darek的数据集),但未能成功。本应使用基础Mistral模型
- 其他Transformer模型 - Electra,其他deberta变体
- 使用deberta v3 large进行MLM预训练
- 使用LGBM的对数概率 - 这些在私有榜上表现良好,但我没有投入足够时间研究
- 微调7B模型 - 私有榜得分仅0.69,公有榜约0.85(AUC 100%)
- 来自公开内核的Tensorflow模型
- 几乎没有对Transformer模型进行超参数调整/使用不同的头部结构,因为没有验证集
- 由于没有验证集,我无法尝试许多在其它竞赛中常用的方法。我希望这种"无固定数据集"和"无验证集"的模式不要成为Kaggle的常态
总结
仅使用Transformer模型比TF-IDF方法或两者集成效果更好。最终提交选择非常重要!