第七名金牌 - 具有不变特征的 CNN Transformer
我非常享受参加这次比赛。两个月前,当我看到没有公开的深度学习笔记本时,我立刻被吸引了,因为这个挑战正是深度学习所喜欢的!我参加这次比赛的目标很简单:用神经网络(NN)击败最好的公开 XGBoost 笔记本。
XGBoost 公开笔记本 - 前 100 名!
感谢 Mahdi Ravaghi 提供的强力 XGBoost 基线 在此(也感谢其他包含在其中的 Kaggle 用户的想法)。在修改该笔记本以为每个 lab_id 每个动作构建一个模型,并在 100% 的训练数据上进行训练后。该笔记本达到了 CV = 0.475, 公开 LB = 0.477, 私有 LB 0.450, (第 88 名) 前 100 名的排名,哇!
本地验证分数
在这次比赛中,当我们使用正确的验证分数时,我们观察到 CV 和 LB 之间近乎完美的关系。(即当 XGB CV 为 0.475 时,XGB 公开 LB 为 0.477)。正确的 CV 仅使用 15 个 lab_id 计算,排除了 MABe22、CalMS21 和 CRIM13 实验室,因为主持人说这些实验室不存在于测试数据中。因此,本 write-up 中讨论的所有 CV 分数都使用正确的本地验证分数。(更新:与私有 LB 的关系没那么好)
如何构建神经网络
神经网络的力量在于从一个实验室到另一个实验室的迁移学习!为了让神经网络大放异彩,我们需要以某种不变的方式预处理数据,因为实验室是不同的。此外,我们需要正确定义目标标签。最后,我们使用数据增强来释放神经网络的全部潜力 🔥
我们将所有实验室的数据一起训练我们的神经网络。通过观察一个实验室,神经网络将学会对另一个实验室做出更好的预测。为了实现这一点,我们需要使输入特征对 lab_id 不变。我们可以进一步通过使用数据增强来最小化 lab_id 特征差异,从而鼓励迁移学习。(即如果实验室之间的老鼠大小不同,那么我们就数据增强随机缩放老鼠的大小)。
=> 正样本、负样本和掩码目标
我们的神经网络有 37 个输出神经元来预测 37 种可能动作中每一种的概率。然而,并非所有视频或实验室都包含所有 37 种动作,如下所示:
在训练我们的神经网络时,我们需要正确定义目标。对于每一视频帧,如果 train_annotation 说 1,则 target=1。否则它要么是负样本要么是掩码。当 train.csv 说 behavior_labeled 但目标缺失于 train_annotation 时,我们设置 target=0。如果一个动作既缺失于 train_annotation 也不包含在 behavior_labeled 列表中,我们设置 target=MASK。“掩码”意味着我们不在这个视频帧中为该动作包含损失。(且 t=0 和 t=1 应用损失)。
=> 不变的老鼠位置
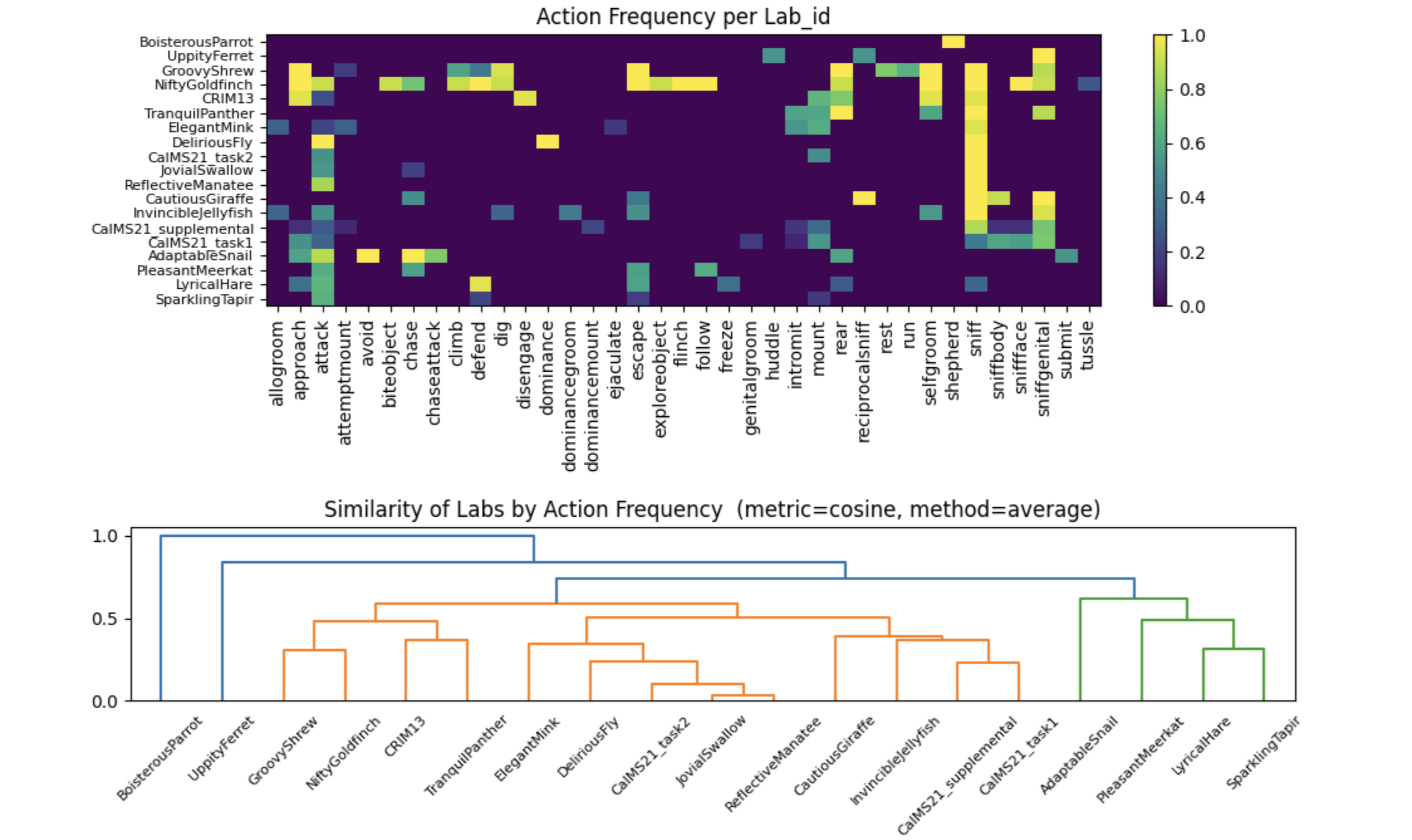
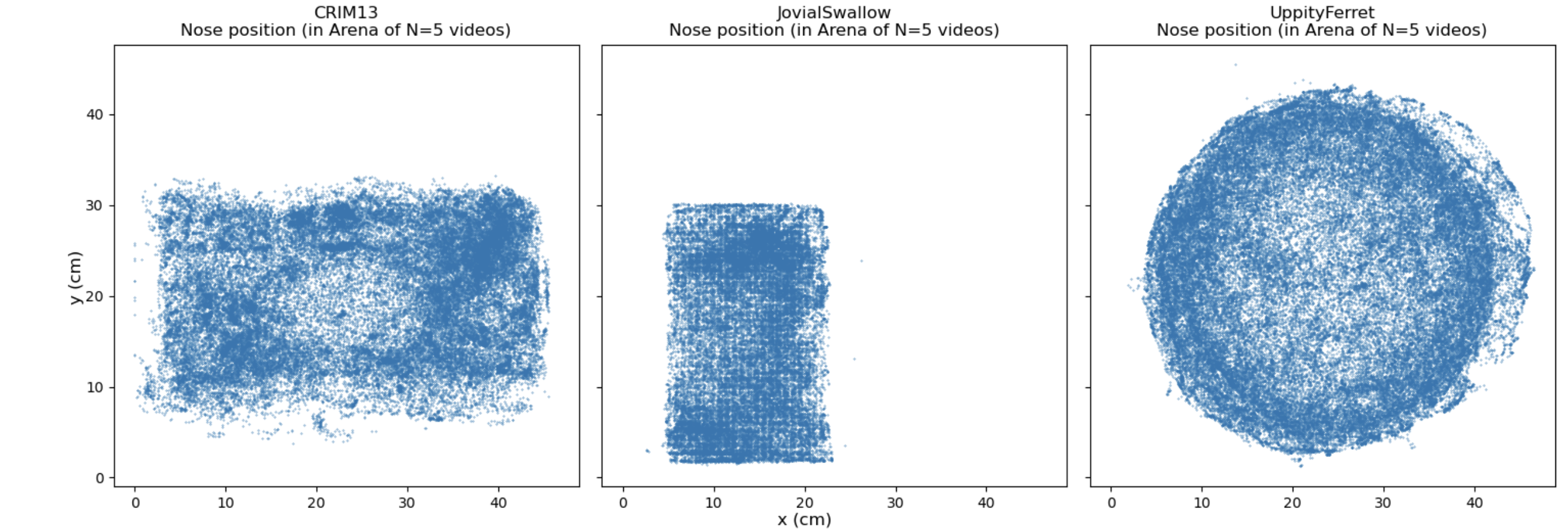
如果我们输入老鼠身体部位的 x,y 作为它们在 train_tracking 文件中的样子,神经网络会感到困惑。因为每个实验室的活动区域大小和形状都不同。一个实验室中的位置 x,y = 10,10 与另一个实验室中的位置 x,y = 10,10 含义不同。下面我们通过制作 1 只老鼠鼻子在 5 个视频上的散点图,看到了 3 个实验室活动区域之间的差异。我们看到实验室的形状和大小各不相同:
至少有 3 种方法可以为我们的神经网络制作不变的老鼠身体部位位置:
- 以代理为中心的坐标系 - 将代理老鼠移动到原点,
ears之间的中点位于(0,0),并旋转tail_base指向负 y 轴下方。(视频中的所有其他老鼠都通过相同的变换进行移动和旋转)。 - 最小最大缩放(使用 5% 和 95% 分位数)所有
x,y,使得活动区域左侧为 0,右侧为 1。底部为 0,顶部为 1。(同时向神经网络提供pixels_per_cm特征)。 - 使用距离而不是绝对
x,y。不是说鼻子在(10,10),我们使用nose和其他身体部位(如tail_base)之间的距离。我们可以将距离计算为向量或大小。
上述要点使位置不变。关于速度,我们注意到速度向量和速度大小已经是不变的。我们注意到代理老鼠身体部位和目标老鼠身体部位之间的所有距离(作为向量或大小)已经是不变的。
下面是我们用以代理为中心的坐标系变换后代理老鼠鼻子位置的散点图示例。我们在散点图中观察到所有鼻子位置现在都在 (0,2) 附近,当老鼠头向左转时它去到 (-2,2),当它向右转时它去到 (2,2):
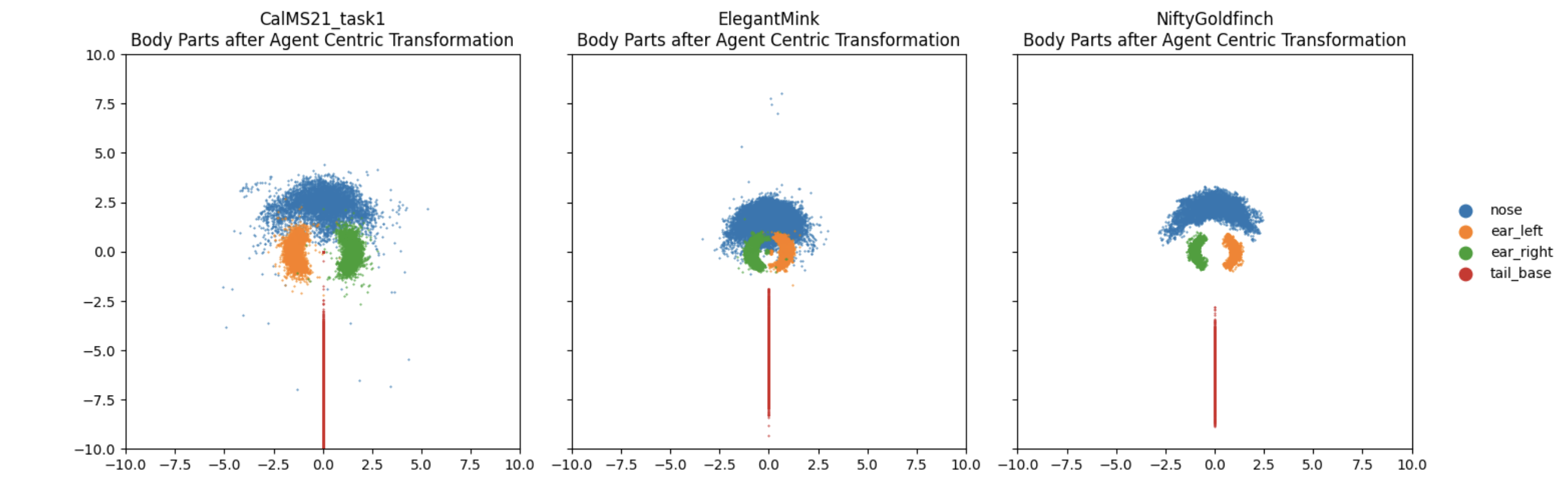
=> 不变的老鼠身体部位
实验室之间迁移学习的另一个挑战是身体部位。我们观察到不同的实验室跟踪不同的身体部位:
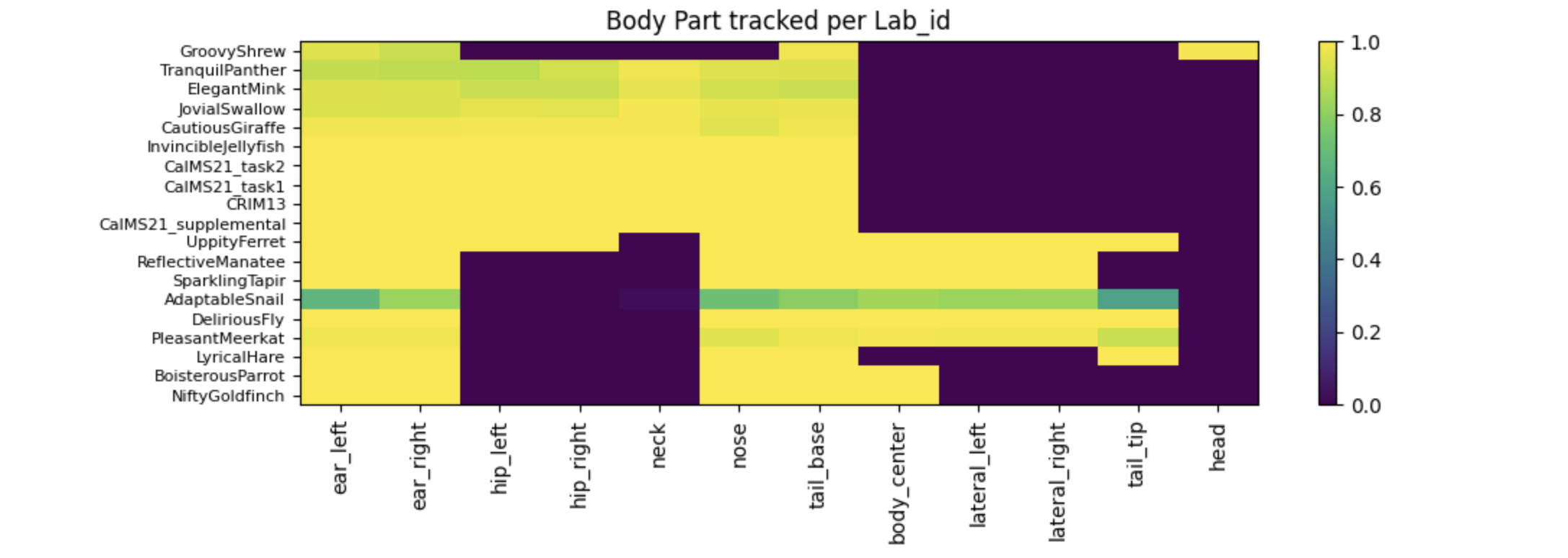
我们观察到所有实验室都有 ["nose", "ear_left", "ear_right", "tail_base"]。然后大约一半的实验室使用 ["hip_left", "hip_right"],另一半使用 ["lateral_left", "lateral_right"]。事实证明,hip 和 lateral 足够相似,我们可以将它们都重命名为 ["side_left", "side_right"] 以最大化迁移学习!
构建 CNN Transformer
我们将所有实验室的数据一起训练我们的神经网络!使用上面列出的 8 个身体部位和正样本、负样本、掩码损失的方法。我们构建一个使用不变位置、速度和距离特征的 CNN Transformer。CNN 层首先出现在时间方向上进行卷积。它们学习根据一切如何变化来制作特征。接下来,神经网络将这些特征输入到注意力层。使用交叉(老鼠)注意力和自(老鼠)注意力,Transformer 层学习比较代理和目标老鼠,并比较单个老鼠内的身体部位。最后,头层输出 37 个输出,给出 37 种可能动作中每一种的概率!
![]()
不同的时间尺度
- window = 64 帧,stride = 16(约 2 秒窗口),CNN 层 = 6
- window = 128 帧,stride = 32(约 4 秒),CNN 层 = 8
- window = 256 帧,stride = 64(约 8 秒),CNN 层 = 10
- window = 512 帧,stride = 128(约 16 秒),CNN 层 = 12
数据增强
使用数据增强可以大幅提高性能。数据增强有两个原因有帮助。首先是使神经网络更难过拟合(即记忆而不是泛化数据),我们可以训练更多轮次。其次,它有助于实验室之间的迁移学习,因为所有实验室开始看起来都一样。例如,如果一个实验室的老鼠比另一个实验室的大,经过随机缩放后,模型从每个实验室接收所有大小的老鼠。我们使用:
- 时间增强 - (随机将 30 fps 更改为 15 或 60)
- 旋转增强
- x 轴缩放增强
- y 轴缩放增强
- 水平翻转
- 用左侧身体部位重新标记右侧
- 身体部位 dropout
推理
我们使用与训练相同的滑动窗口方案进行预测。然后每个视频帧预测 37 个概率。接下来我们在时间上平滑概率,并过滤掉不在 behaviors_labeled 中的动作(每个 video_id, agent_id, target_id 三元组)。最后,我们应用每个 lab_id 的动作阈值字典。每个低于阈值的动作被设置为 prob=0。最后我们采取 argmax 来选择帧动作。(更新:我有一个未选定的提交,实现了 +0.004 私有 LB(排名第 4 或 5),它使用更好的平局打破逻辑来决定当多个动作超过阈值时会发生什么)。
神经网络集成 - CV 0.546 - 公开 LB 0.551 - 私有 LB 0.518 (第 8 名)
我们对所有不同时间尺度的神经网络取等权重平均, achieve CV = 0.546 和 Public LB = 0.551 和 Private LB = 0.518 (第 8 名)。在这个集成中,我们包含了 3 个家族的神经网络。每个家族使用一组不同的不变特征和一系列时间窗口。总之,我们的最终集成使用了来自家族一的 2 个 NN,来自家族二的 5 个 NN,以及来自家族三的 3 个 NN(总共 10 个 NN)。
在 NN 之上堆叠 XGB - CV 0.559 - 公开 LB 0.562 - 私有 LB 0.523 (第 7 名)
为了提高我们的神经网络分数,我们使用来自 3 个神经网络家族的每个 OOF 和 Mahdi Ravaghi 公开笔记本 在此 的所有特征训练一个 XGB。我们为每个实验室每个动作训练一个 XGB。这个 XGB 的 CV 达到 CV = 0.528 和 Public LB = 0.536 和 Private LB = 0.508 (第 12 名)。当我们将其与我们的集成神经网络混合时,结果是 CV = 0.559 和 Public LB = 0.562 和 Private LB = 0.523 (第 7 名),哇!