Google - Fast or Slow? 预测 AI 模型运行时竞赛的亚军方案
我们向 Kaggle 以及 Google 的 TPU 团队表示诚挚的感谢,感谢他们组织了这场卓越的比赛。
本解决方案的代码已发布在 Github: Fast or Slow by Latenciaga。
引言
我们的实现是一个基于 SageConv 的图神经网络(GNN),作用于整个图结构,并使用 PyTorch/PyTorch-Geometric 进行训练。该 GNN 采用了一种或两种损失函数进行训练,其中包括一种新颖的 DiffMat 损失,我们将在后文详细讨论。
数据集预处理
我们对所有 5 个子集的数据进行预处理,通过配置移除重复项。我们发现,对于每个图,多个配置实例(对于 Layout 是全部节点级联,对于 Tile 是子图)是完全相同的,而对应的运行时间却不同,最大与最小值之间的差异可达 0.4%。我们将这些组别的运行时间缩减为最小值。对于 Layout-XLA,我们过滤掉所有 Unet 图,因为我们发现 unet_3d.4x4.bf16 已严重损坏。出于同样的原因,我们从 Layout-XLA-Default 验证集中移除了 mlperf_bert_batch_24_2x2,以提高验证的稳定性。我们还发现了许多其他数据似乎已损坏的图,但并未将其过滤掉。作为预处理的一部分,我们重新打包了 Layout 的 NPZ 文件,使得每个图的每个配置加运行时间测量值(最多 10 万次)都可以从 NPZ 文件中单独加载,而无需加载整个 NPZ 文件。通过这种重新打包,得益于延迟加载,随机读取速度提升了 5-10 倍,训练墙钟时间也相应减少,训练过程也从数据加载受限转变为 GPU 受限。
模型
我们为每个子集从头训练了 5 个模型,并应用了不同的超参数,如下表所示。所有 GNN 层均为 SageConv 层,在输入和输出通道数相同时会使用残差连接。
| 子集 | 层数 x 通道数 | 参数数量 |
|---|---|---|
| Layout-XLA | 2x64 + 2x128 + 2x256 | 27万 |
| Layout-NLP & Tile | 4x256 + 4x512 | 230万 |
节点类型被嵌入到 12 维空间中。节点特征通过 sign(x)*log(abs(x)) 进行压缩,并通过线性层塑形为 20 维。对于 Layout,配置不进行转换;对于 Tile,图配置会广播到所有节点。我们在将三个特征(节点类型嵌入、节点特征和配置)传递到 GNN 层之前,通过早期融合将其组合成一个特征向量。GNN 层堆叠产生的特征被转换为每个节点一个值,然后通过求和归约为单个图级别的预测值。
训练过程
我们遵循比赛主办方提供的训练和验证集划分。对于所有 5 个子集,训练仅在训练集划分上进行。
批次被组织成两层层次结构:上层是不同的图,下层是相同的图和不同的配置,分组为相同大小的微批次(也称为 slates)。此过程允许将排序损失应用于微批次内的样本组。我们发现使用某种形式的排序损失对得分至关重要。使用排序损失(ListMLE、MarginRankingLoss)训练的模型在很大程度上优于逐元素损失(MAPE 等)。
| 超参数 | Tile 子集 | Layout- XLA-Random | Layout- XLA-Default | Layout- NLP-Random | Layout- NLP-Default |
|---|---|---|---|---|---|
| 微批次大小 | 10 | 4 | 4 | 10 | 10 |
| 批次中的微批次数量 | 100 | 10 | 10 | 4 | 4 |
| 批次大小 | 1000 | 40 | 40 | 40 | 40 |
以下超参数已设置:
- Adam/AdamW 优化器,
- 学习率 1e-3,
- 40万次迭代,
- 在 24万、28万、32万 和 36万 次迭代时按因子
1/sqrt(10)调整学习率的步进学习率调度器。
每个子集在 A100 上的训练时间约为 20 小时。未采用早停策略。提交的所有快照均来自第 40 万次迭代。
训练使用的损失函数:
- Layout-NLP 使用 ListMLE,
- Tile 使用一种新颖的 DiffMat 损失,
- 对于 Layout-XLA,结合了两种损失:DiffMat 损失和 MAPE 损失。
对于 ListMLE 损失,我们使用了预测范数裁剪,以避免因大数除以大数而导致的数值不稳定。在 ListMLE 损失之前我们不进行预测 L2 归一化,因为发现这会损害得分。
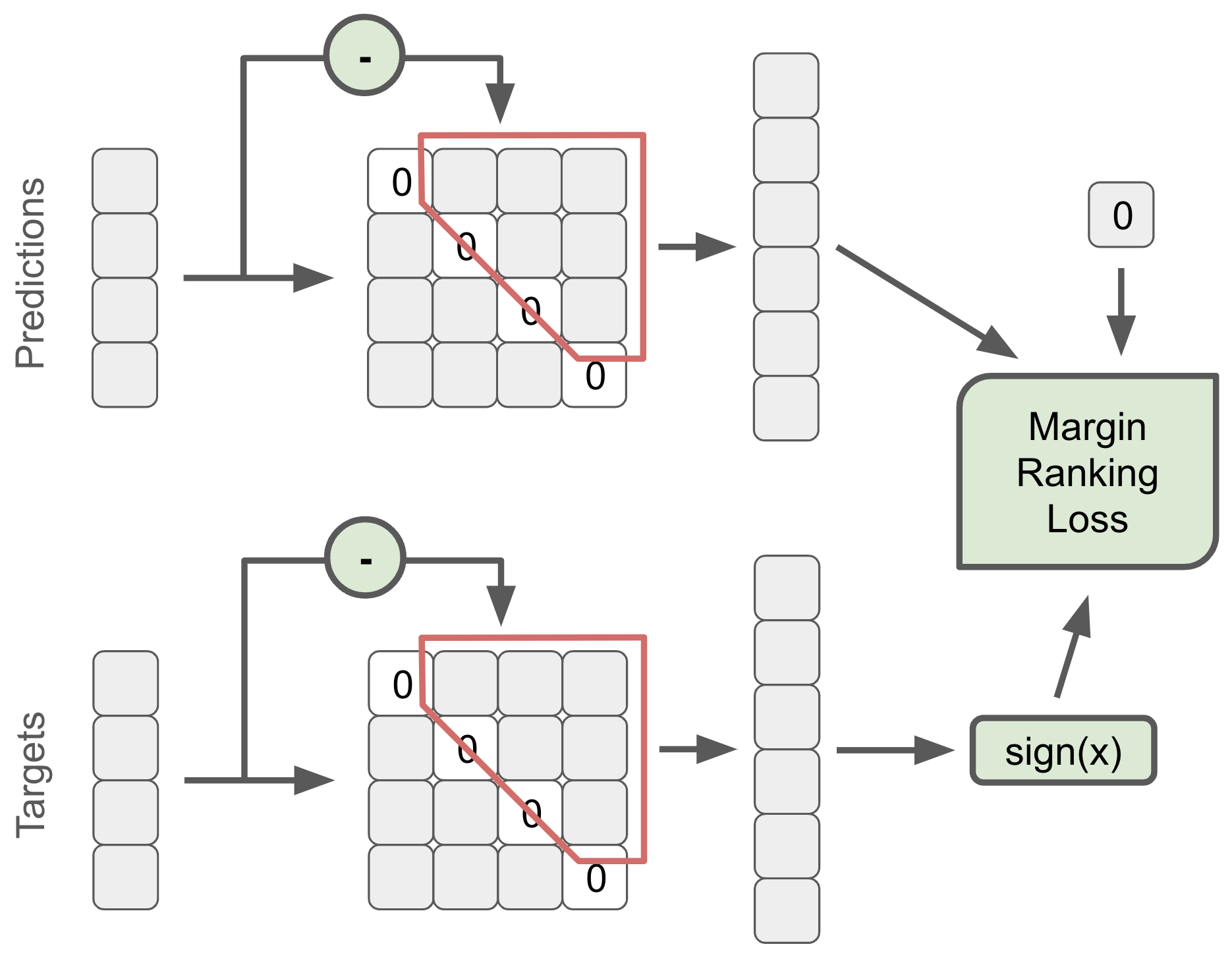
新颖的 DiffMat 损失通过以下算法描述。在微批次内,为预测值和目标值构建一个完整的反对称成对差异矩阵。从差异矩阵中取上三角矩阵并展平。在预测值和零之间应用 margin 为 0.01 的 Margin Ranking Loss。这种新颖的损失与 MAPE 损失结合,在 XLA 上始终优于 ListMLE。
关于验证(CV)稳定性的说明
我们发现,由于 XLA Random 和 Default 的数据集相对较小,且训练集与验证集(推测还有测试集)之间存在显著的领域差距,因此验证集上的 Kendall tau 极其不稳定。重复训练的结果之间差异高达 13 个百分点。
未成功的实验
数据过滤
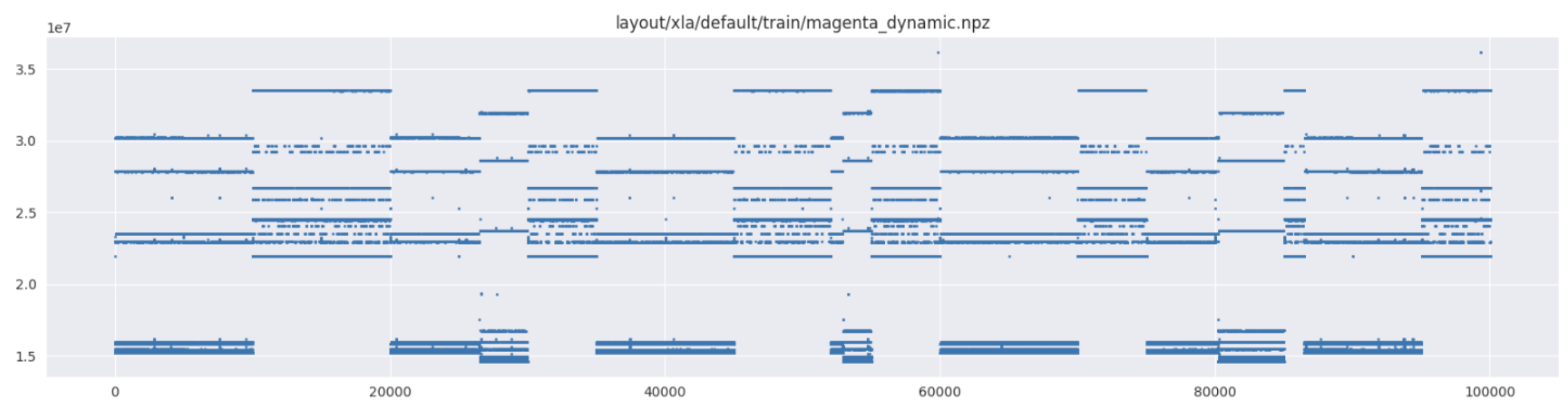
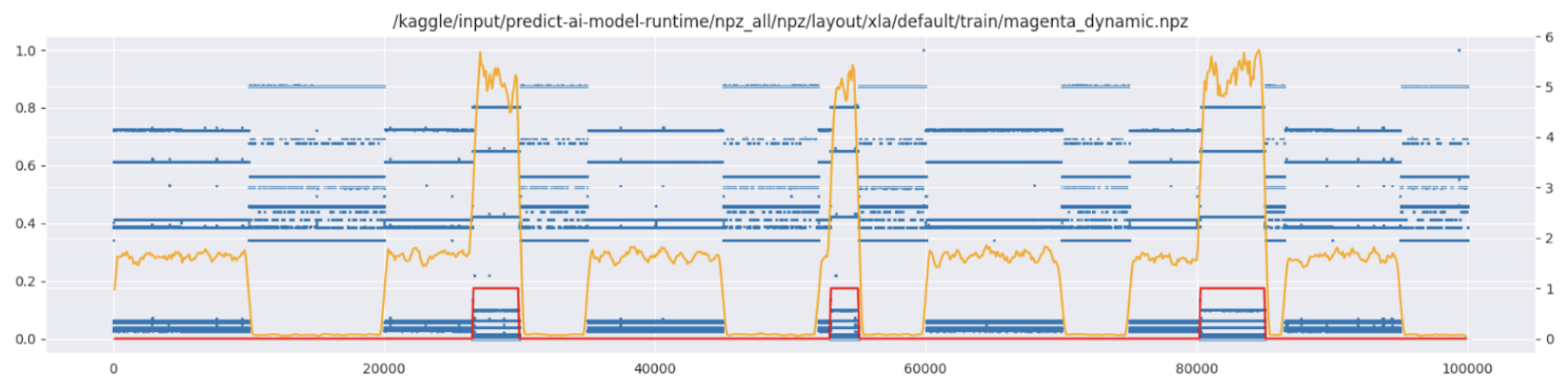
一些图的数据严重损坏。例如,magenta_dynamic 的运行时间随配置 ID 的变化如下所示。无论如何,这些都不可能是来自同一图的测量值。
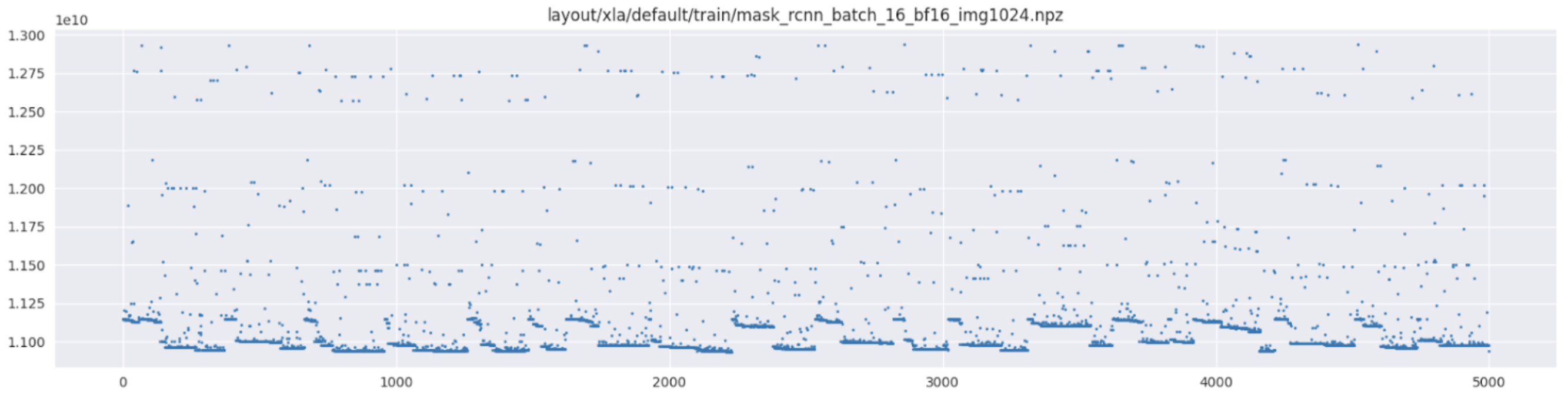
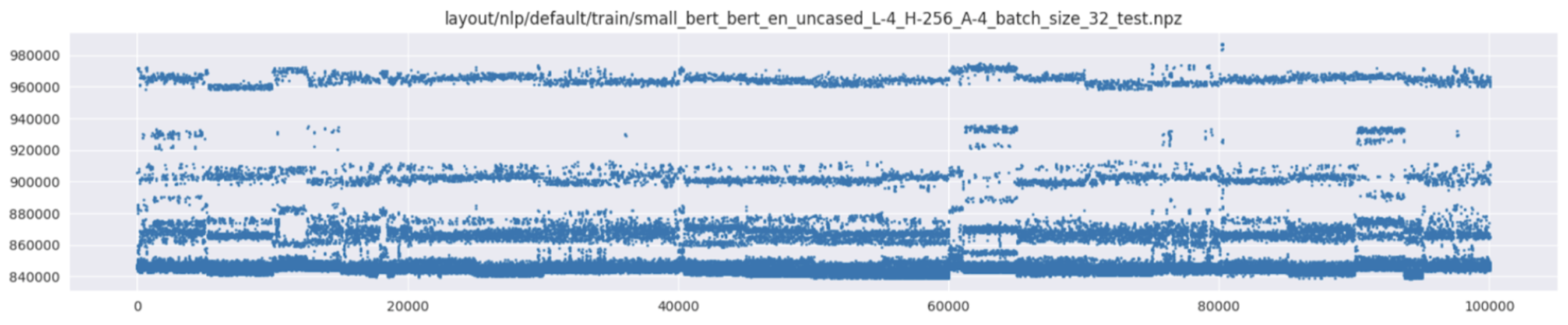
以下是其他一些不确定这些测量是在何种条件下进行的情况。
尽管如此,我们没有过滤掉这些图和其他图,因为由于前面提到的验证 Kendall 数的不稳定性,我们无法可靠地观察到移除它们所带来的改进。
数据恢复
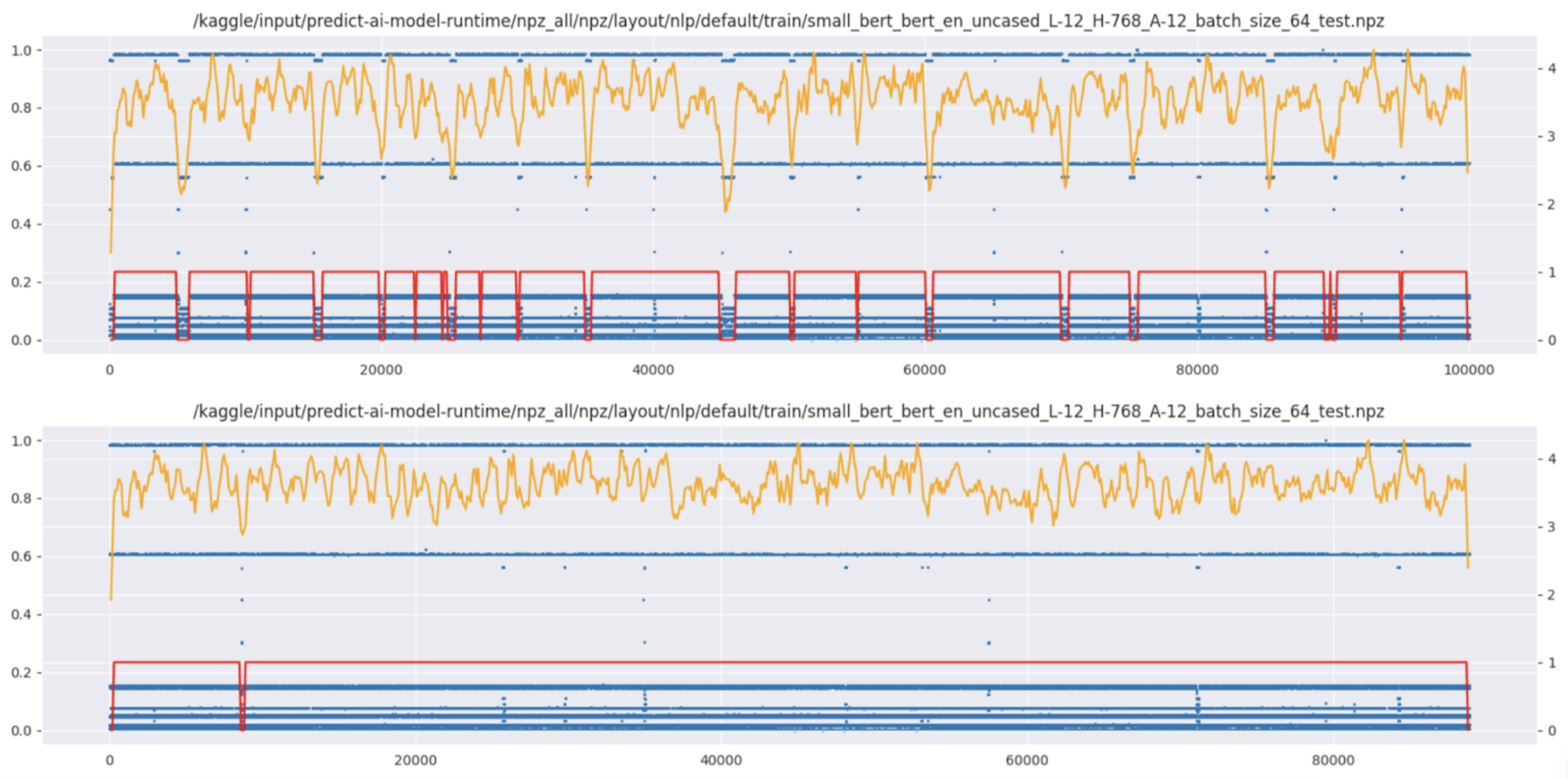
我们尝试通过计算相邻块之间运行时间的块级熵,以自动方式查找损坏的数据并将其移除。虽然检测在视觉上似乎有效,但我们观察到对得分的负面影响,因此没有继续此功能。
示例 1:
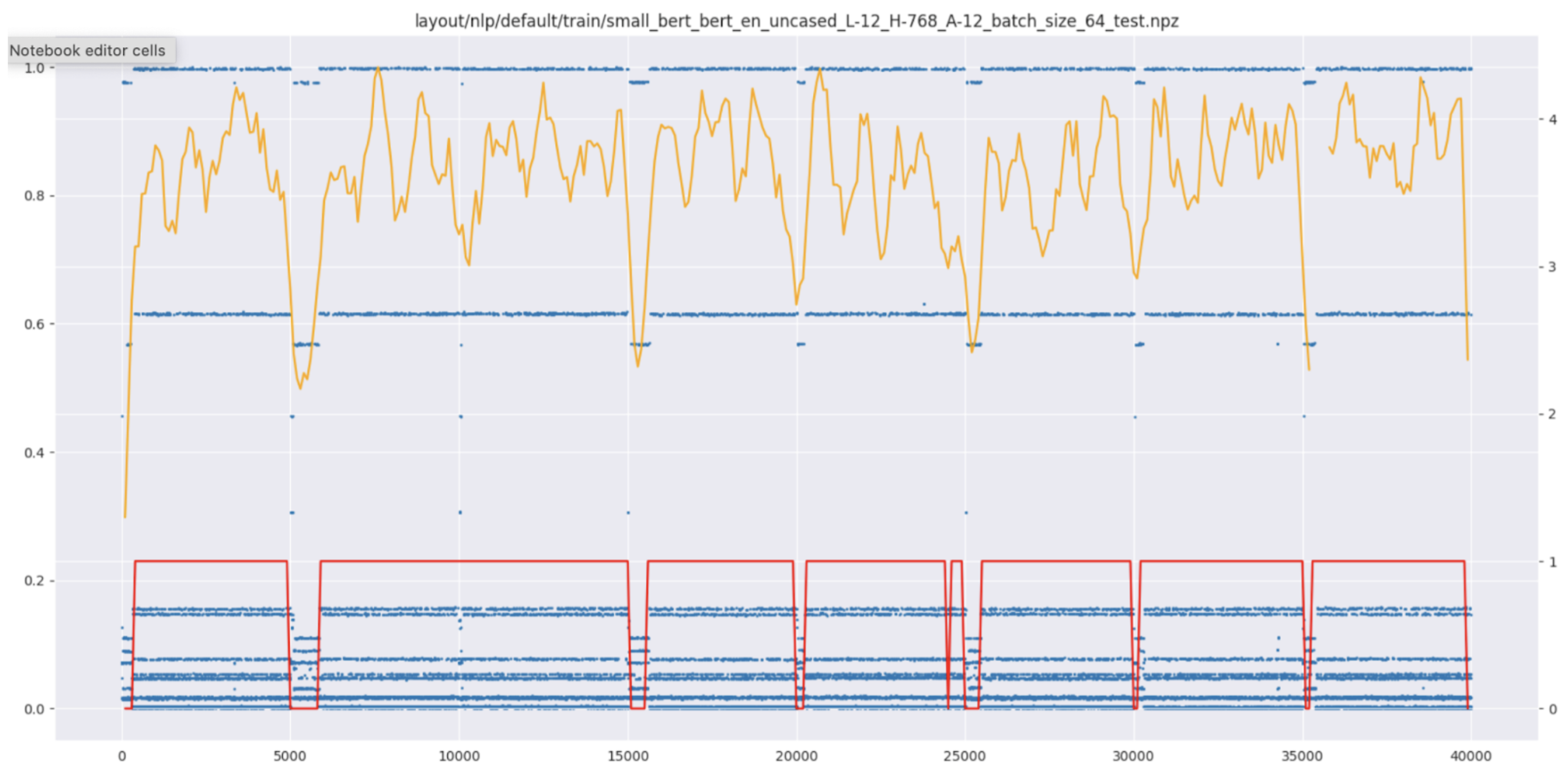
示例 2:
熵过滤前后的对比:
我们尝试过但未成功的其他实验:
- GATv2Conv、GATv2 骨干网络、GINEConv,
- Dropout,
- 在合并的 Random 和 Default 上训练 - 对两者都有损害,
- 添加反向边,
- 在线困难负样本挖掘(OHEM)- 没有帮助,因为训练损失远未达到零,
- 盲目地在合并的训练集和验证集(trainval)上训练,
- 训练 4 折并通过平均延迟和平均倒数排名(MRR)合并,
- 周期性学习率调度。
结论
我们发现 Google Fast or Slow 是一场非常棒的竞赛,我们非常享受其中,并学到了许多新知识,特别是排序损失。
部分受此次竞赛启发,Dmitrii 在 Towards AI 上发表了一篇文章 《深度学习实验的十大模式与反模式》。