银牌 - LB 0.770 - 两行代码的改进!
感谢Kaggle和Google举办了一场有趣的ASL(美国手语)竞赛。
我在几天前加入比赛,因此没有时间构建自己的模型。于是我从最佳公开笔记本(版本17)开始尝试改进它。经过一些修改后,我将线上得分从0.700提升到了惊人的0.770!并获得了银牌!!
修改两行代码
最佳公开笔记本是Rohith Ingilela的优秀作品,随后由Saidineshpola进行了改进。Saidineshpola笔记本的版本17实现了CV=0.689和LB=0.697。
该笔记本使用了Rohith Ingilela创建的TF Records。一个提升公开笔记本性能的简单技巧是:创建包含手部缺失帧的TF Records。原笔记本中的TF Records会移除所有没有手部的帧,而我们保留50%的手部缺失帧来提升CV和LB。
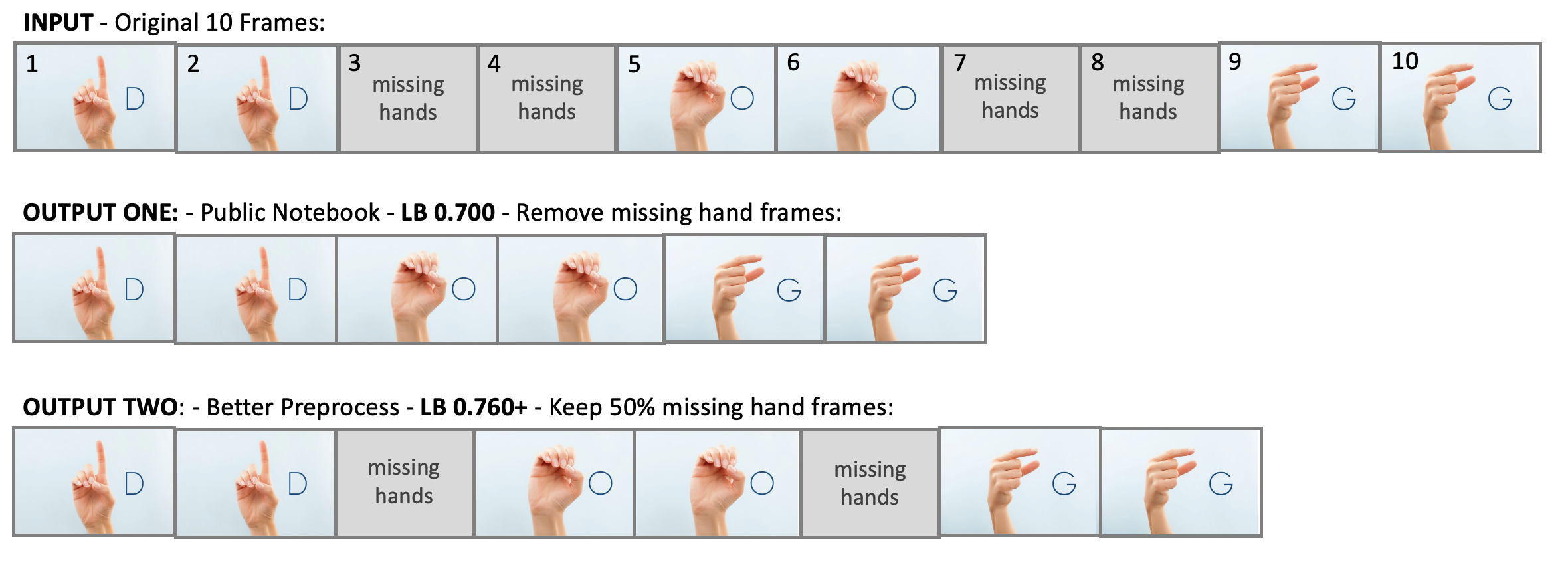
在制作TF Records和推理时使用的预处理代码:
hand = tf.concat([rhand, lhand], axis=1)
hand = tf.where(tf.math.is_nan(hand), 0.0, hand)
mask = tf.math.not_equal(tf.reduce_sum(hand, axis=[1, 2]), 0.0)
alternating_tensor = tf.math.equal(tf.cumsum(
tf.ones_like(tf.reduce_sum(hand, axis=[1, 2])))%2, 1.0)
mask = tf.math.logical_or(mask, alternating_tensor)CTC(连接时序分类)损失
通过这次比赛,我学习了CTC损失函数。这个损失函数非常强大!它允许我们创建具有可变长度输入并预测可变长度输出的模型。因此,我们可以像seq2seq模型一样工作,而无需等待顺序解码器逐步解码。相反,我们可以一次性快速预测整个输出!给模型提供一些手部缺失的帧有助于识别重复和过渡:
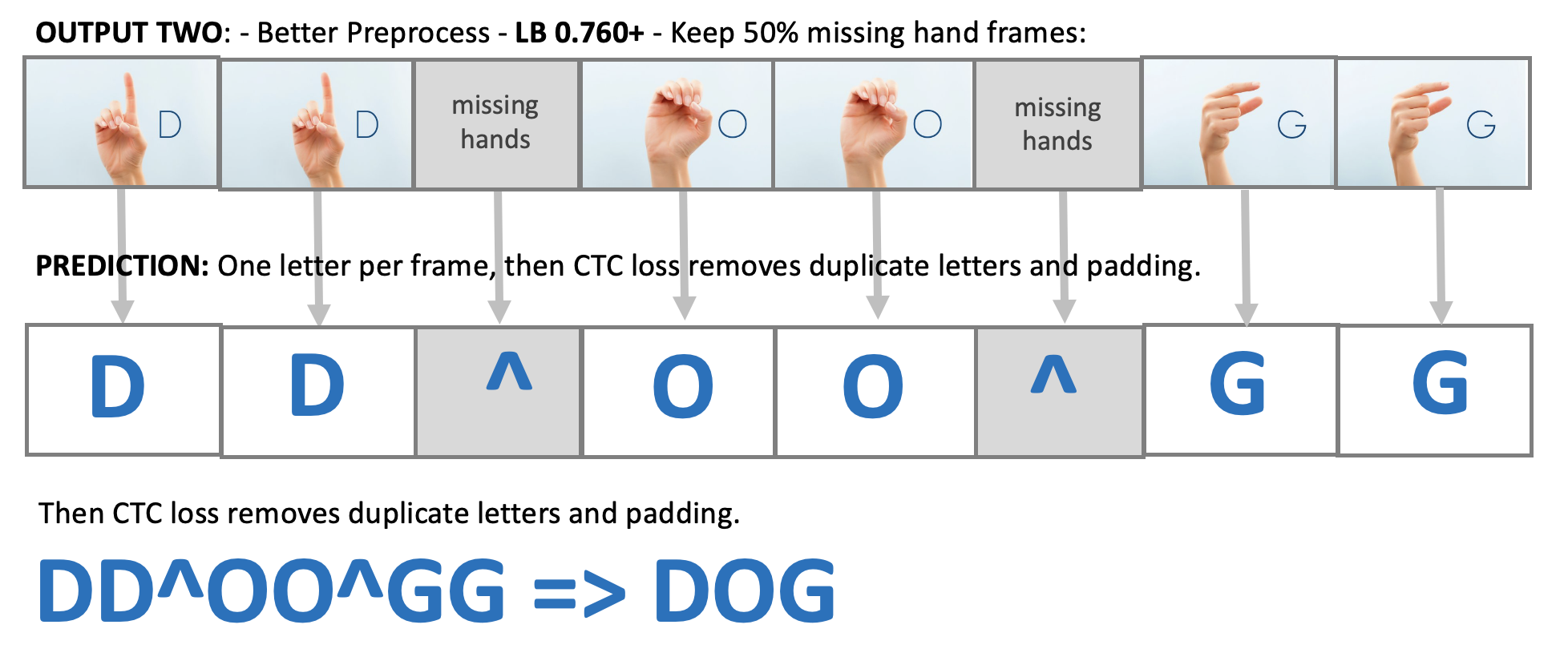
时间增强 +0.004
公开笔记本训练50个轮次,我发现增加训练轮次可以持续提升CV和LB分数!我的最终提交训练了200个轮次。此外,我们还可以添加数据增强(即正则化),这有助于模型训练更长时间,防止过拟合并提高泛化能力。
下图显示了训练数据中帧数除以目标短语字符长度的直方图。从这个图中可以看出,该比率变化很大。有些视频的录制帧率不同,有些参赛者打手语的速度更快。
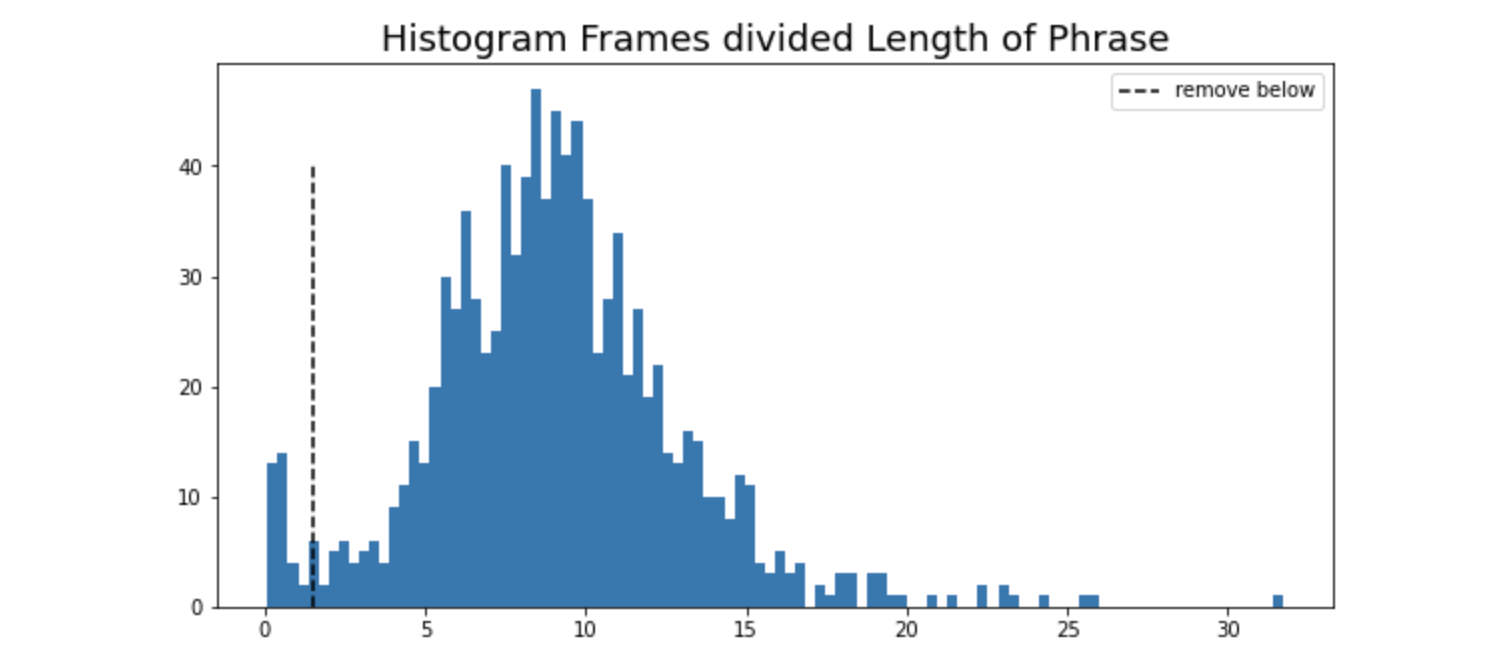
这意味着模型很难从一个帧率迁移学习到另一个帧率。我们可以通过时间增强来帮助模型。对于每个输入序列,我们可以随机将帧长度缩小50%或扩大150%。这将增加大量新的训练数据,并帮助模型学习不同的帧率:
if tf.random.uniform(shape=(), minval=0, maxval=1) < 0.2:
new_height = tf.math.round(tf.random.uniform(
shape=(),
minval=tf.cast(tf.shape(lip)[0], tf.float32) / 2.0,
maxval=tf.cast(tf.shape(lip)[0], tf.float32) * 1.5))
for x in [lip, rhand, lhand, rpose, lpose]:
x = tf.image.resize(x, (new_height, tf.shape(x)[1]))后处理 +0.004
有时模型的预测效果不佳。最短的训练数据长度为3。当模型预测长度小于等于2时,我们知道这是不好的预测。因此,我们可以用最佳恒定长度预测替换这些不良预测。Anokas找到了最佳恒定长度预测。我们将以下代码添加到TF Lite模型中:
x = tf.cond(tf.shape(x)[0] < 3,
lambda: tf.constant([17, 0, 32, 12, 36, 0, 12, 32, 49, 46, 36], tf.int64),
lambda: tf.identity(x))解决方案代码
我发布了一个Kaggle笔记本,演示了上述3项改进。以下前四点实现了LB = 0.763,然后时间增强提升了+0.004,后处理提升了+0.004。注意第二点(关于批量大小)只是让训练更快,但不改变CV或LB分数:
- 修改两行代码:保留50%的手部缺失帧
- 将批量大小从32改为128,学习率从1e-3改为4e-3
- 将FRAME_LEN从128改为216
- 训练轮次从50增加到200
- 添加时间增强
- 对小于3个字符的预测添加后处理