第六名解决方案
非常感谢组织如此有趣的比赛,对主办方和Kaggle工作人员深表谢意。
延续上一届比赛,我很高兴再次获得个人金牌,总计四枚奖牌(表格1,自然语言处理×2,计算机视觉×1)。这也是我首次尝试图像分割任务,从@tanakar的优秀笔记本这里开始。对此我深表感激。
1. 概述
我的方案采用了EfficientNet和SegFormer模型的集成。根据其他讨论,我认为测试数据是旋转过的,因此在推理过程中对图像进行旋转,这带来了显著提升(公开榜0.58→0.74)。另一个创新点是将红外图像纳入训练数据,使CV分数提升0.01,LB分数提升0.01。下面我将详细说明。
2. 推理过程
2.1 测试数据与推理流程
基于简要的LB探测和比赛页面信息,我对测试数据形成了如下理解:
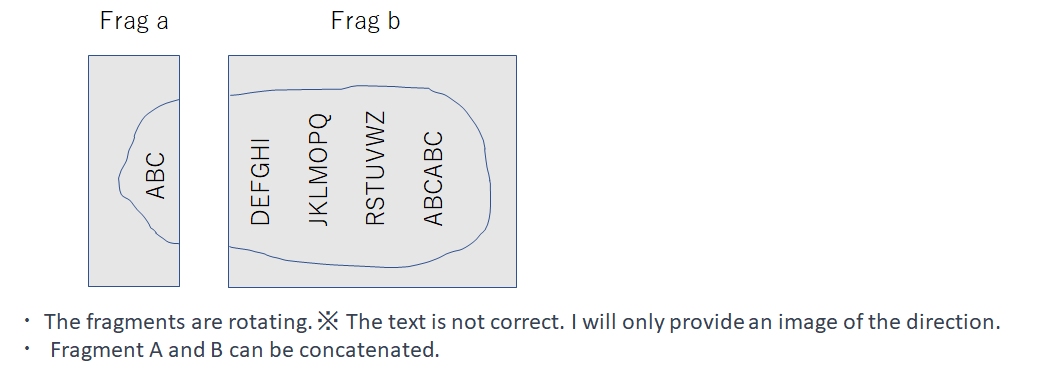
因此,我在Kaggle笔记本中的推理代码结构如下:
- 沿axis=1拼接片段A和B
- 将图像顺时针旋转
- 执行推理(原始+h翻转TTA)
- 将预测结果逆时针旋转回原始位置
- 分别裁剪并编码片段A和B
当然,为减少推理时间,我跳过了掩码值为0的区域推理。此外,通过拼接片段A和B而非分别推理,不仅消除了A与B边界处的0填充,还实现了片段B起始部分的连续推理。这些措施显著提升了LB分数(EfficientNet B4: 0.58→0.74)。
2.2 阈值处理
我认为许多参赛者都遇到了信号值不稳定的问题。因此我使用以下函数对整个图像进行排序并计算百分位数,再应用阈值获得稳定的阈值。这种方法不仅在推理中有效,在集成过程中也很有帮助。第二名方案也采用了相同方法此处:
def get_percentile(array):
org_shape = array.shape
array = array.reshape(-1)
array = np.arange(len(array))[array.argsort().argsort()]
array = array / array.max()
array = array.reshape(org_shape)
return array对于公开榜,最优阈值是0.96。但使用片段3进行模拟时,我观察到部分最优阈值(约10%区域)与剩余90%阈值之间的关联:阈值对10%区域过拟合(可能用于降噪),而降低阈值(追求更清晰的文本提取)对剩余90%更优。实际上,相同模型使用0.95阈值在私有榜上表现略优(但小于0.01)。最终提交中,sub1使用0.96阈值,sub2使用0.95阈值。
3. 训练过程
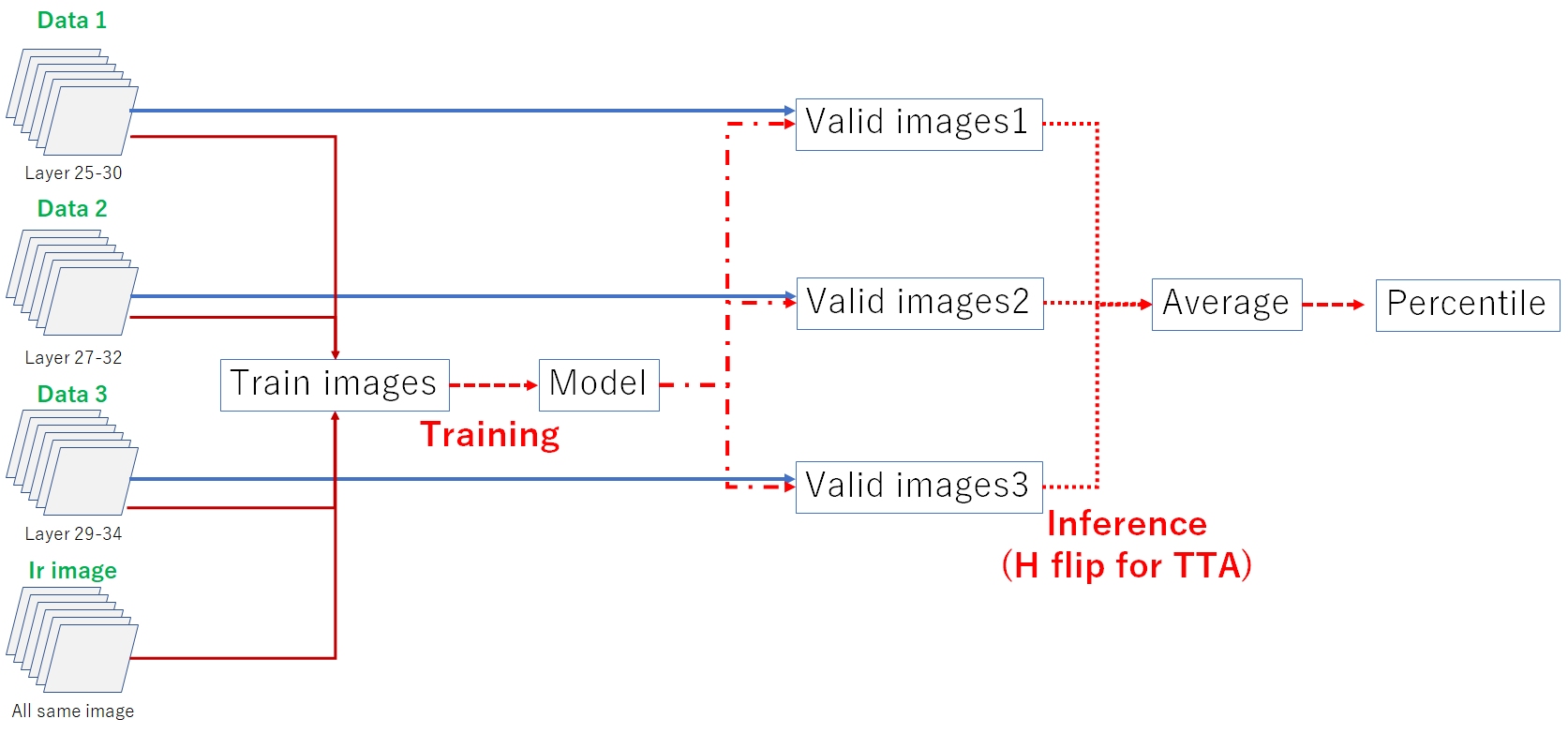
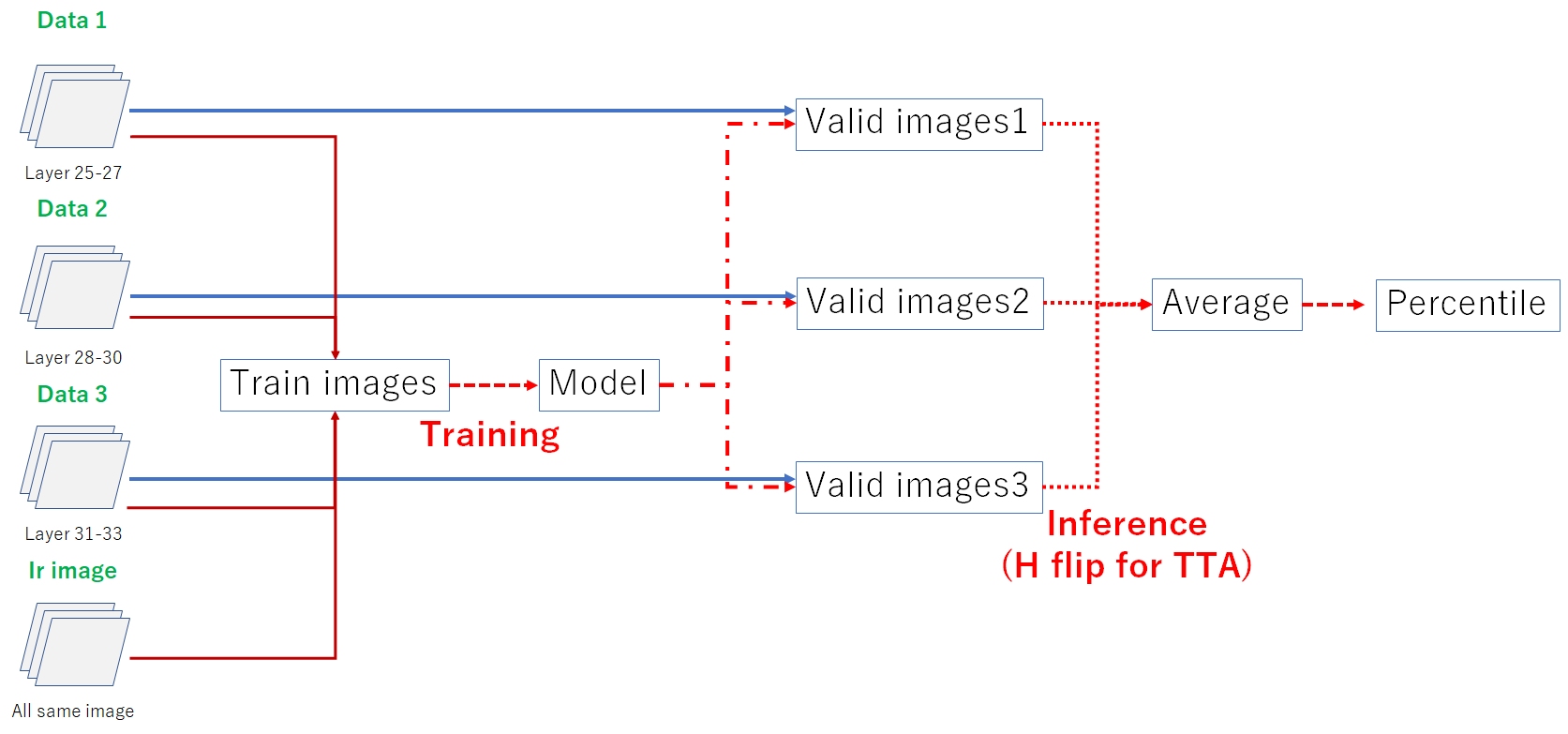
训练过程概述如下。与推理类似,我创建了三组数据并取平均值。需要注意的是,SegFormer与CNN不同,只能使用3个通道。如前所述,加入红外图像提升了CV和LB分数。
3.1 CNN + Unet
3.2 SegFormer
3.3 微调参数
- 步幅:图像大小 // 4
- 优化器:Adam
- 轮次:20
- 早停:4
- 调度器:get_cosine_schedule_with_warmup(来自transformers)
- 预热:0.1
- 梯度范数:10
- 损失函数:SoftBCEWithLogitsLoss(PyTorch分割模型)
- 训练排除掩码值为0的区域
- TTA:水平翻转
3.4 交叉验证
提交1使用7折交叉验证,提交2使用10折交叉验证。增加k折数值提升了CV和LB分数。我记得从5折增加到7折使公开榜提升了约0.1分。
4. 最终结果
集成采用所有预测值的平均值。
sub1:阈值0.96,CV 0.740,公开榜0.811570,私有榜0.661339
| 模型 | 图像尺寸 | kfold | cv | 公开榜 | 私有榜 |
|---|---|---|---|---|---|
| efficientnet_b7_ns | 608 | 7 + 全量训练 | 0.712 | 0.80 | 0.64 |
| efficientnet_b6_ns | 544 | 7 + 全量训练 | 0.702 | 0.79 | 0.64 |
| efficientnetv2_l_in21ft1k | 480 | 7 | 0.707 | 0.79 | 0.65 |
| tf_efficientnet_b8 | 672 | 7 | 0.716 | 0.79 | 0.64 |
| segformer b3 | 1024 | 7 | 0.738 | 0.78 | 0.66 |
sub2:阈值0.95,CV 0.746,公开榜0.799563,私有榜0.654812
| 模型 | 图像尺寸 | kfold | cv | 公开榜 | 私有榜 |
|---|---|---|---|---|---|
| efficientnet_b7_ns | 608 | 10 | 0.722 | 0.80 | 0.65 |
| efficientnet_b6_ns | 544 | 10 | 0.720 | 0.79 | 0.63 |
| efficientnetv2_l_in21ft1k | 480 | 10 | 0.717 | 0.79 | 0.65 |
| segformer b3 | 1024 | 7 | 0.738 | 0.78 | 0.66 |
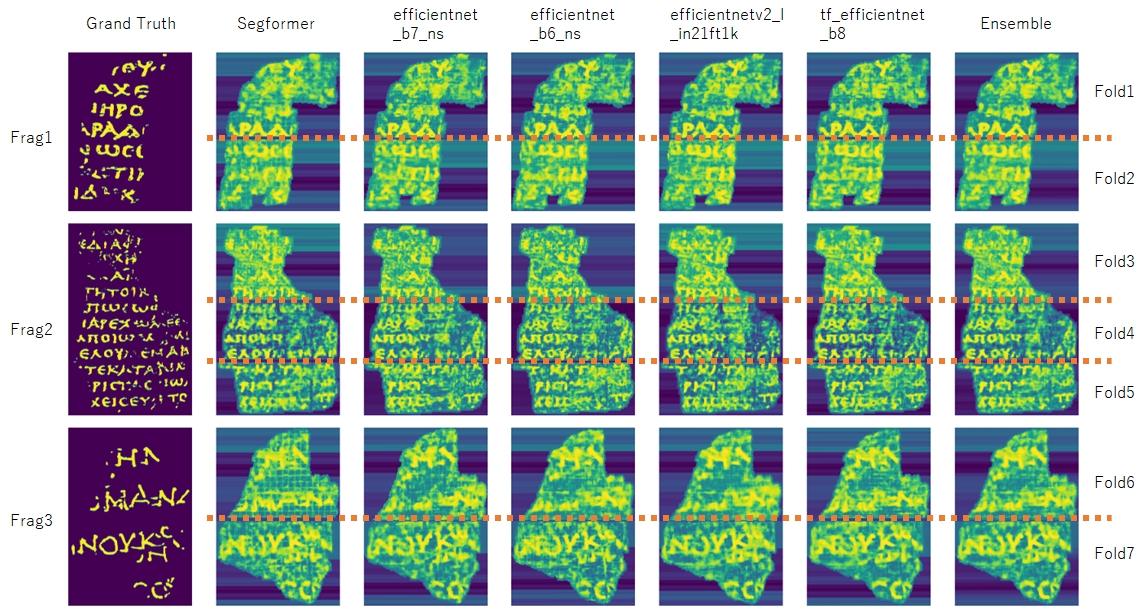
4.1 预测结果可视化
以下是submission1的预测结果可视化图像:
5. 我的理解
5.1 效果不佳的方法
我尝试了ConvNext、Mask2Former、Swin Transformer+PSPNet、BeiT等多个模型,但它们在CV和LB上的效果都不理想。EfficientNet和mobilevit在本届比赛中表现稳定。我还测试了SegFormer的各种版本(b1到b5),虽然CV表现良好,但LB分数差且不稳定。比赛结束前五天,当我再次绘制CV与LB分数关系时,发现大模型容易过拟合:CV分数高但LB分数差。调整所用层后,只有b3表现出高LB分数,尽管我怀疑仍存在过拟合。但在集成使用时,它显著提升了LB分数,因此我决定包含它。这种差异可能源于训练数据有限。我本应尝试dropout、冻结等正则化技术,但时间不足。考虑这些选项可能进一步提升性能。
※ 以上仅为个人推测
5.2 未实现的可能改进
使用红外图像预训练:虽然提升了CV性能,但导致LB分数下降,故未采用。
在训练数据中加入EMNIST(外部数据):同样提升了CV性能但恶化了LB分数,因此未实施。
6. 致谢
没有他人的帮助我无法取得这些成果。我非常感谢过去与我合作的伙伴们,也衷心感谢那些通过以往比赛分享知识和见解的人们。谢谢大家。