第13名解决方案
首先,我要感谢 Kaggle 团队和主办方举办这次比赛,也要感谢许多其他参与者分享代码、想法和数据集。
我非常高兴能获得单人金牌。
概述
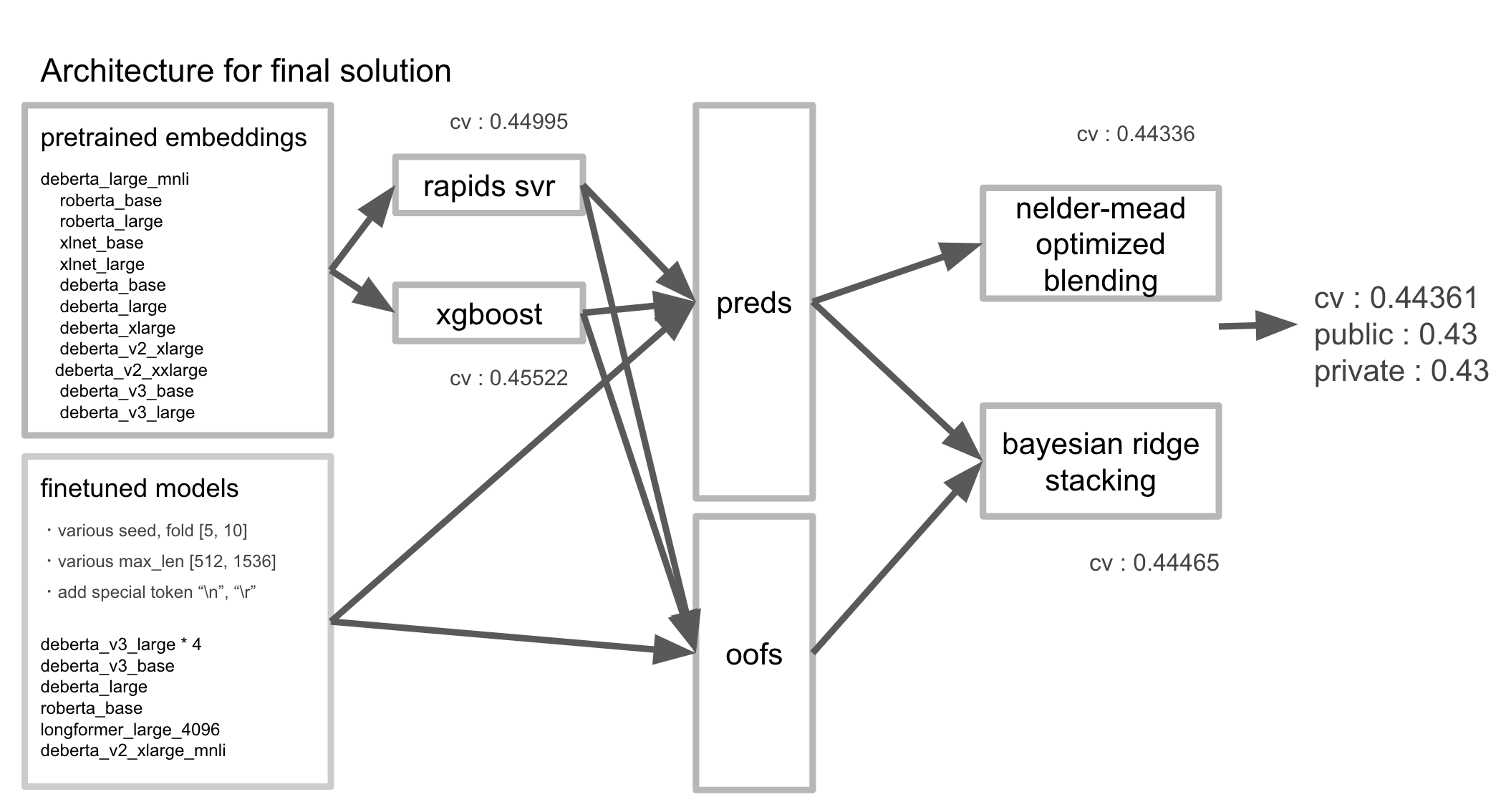
我的最终提交模型是加权平均模型,由 0.5 * 11个模型的 Nelder-Mead 融合结果 + 11个模型的贝叶斯岭回归堆叠结果 组成。
每个模型都使用了不同的超参数进行训练,例如 seed(随机种子)、num_fold(折数)、max_length(最大长度)等。
我的最终代码在这里:
- FB3 Private 14th Solution Code
- 很抱歉我的很多 Notebook 都是公开的,因为每个人都可以运行这段代码。
我的训练仓库在这里:
有效的方法
[高影响] 想法
- 信任 CV (Trust CV)
- 只要 OOF CV 分数有所提高,我就将新模型加入到集成中。
- Rapids SVR
- Nelder-Mead 优化加权融合
- 我第一次听说这个方法是在之前的 NLP 比赛解决方案中。
- 更长的最大长度 (1536) 并使用头尾 tokens
- 许多公开的 Notebook 使用了 512 的 max_length。
- 然而训练集 full_text 中的最大 token 长度约为 1430。
- 我决定在训练中使用更长的 token 长度。
- 冻结嵌入层和前两层
-
def freeze(module): for parameter in module.parameters(): parameter.requires_grad = False if self.cfg.freezing: freeze(self.model.embeddings) freeze(self.model.encoder.layer[:2])
-
- 每个 epoch 评估两次
[中等影响] 想法
- 我用 XGBoost 替换了 SVR 并添加了最终模型。这有助于增加模型的多样性。
- 添加特殊 token
- 我注意到 full_text 中有许多 "\n\n"。
-
def setup_tokenizer(CFG): CFG.tokenizer.add_tokens([f"\n"], special_tokens=True) CFG.tokenizer.add_tokens([f"\r"], special_tokens=True)
无效的方法
- 想法
- 在尝试 Rapids SVR 方法时使用我微调过的 embeddings。
- 使用 Universal Sentence Encoder Embedding。
- 在微调 Hugging Face 模型和第二阶段堆叠模型时,使用文本特征作为元特征。
补充背景
- CV 策略
- 我使用了 <a href="https://www.kaggle.com/code/abhishek/m