第二名解决方案(senkin部分及代码)
感谢所有组织者和Kaggle团队举办了如此具有挑战性的比赛。感谢我的队友 @baosenguo,我对生物信息学一无所知,从他那里学到了很多东西。我原以为我的团队能赢得这场比赛,因为我们从头到尾都排在LB(排行榜)的第一名,但时间域的偏移是不可预测的,我们接受这个结果,并祝贺 @shujisuzuki65,巨大的shakeup(排名变动)!
概览
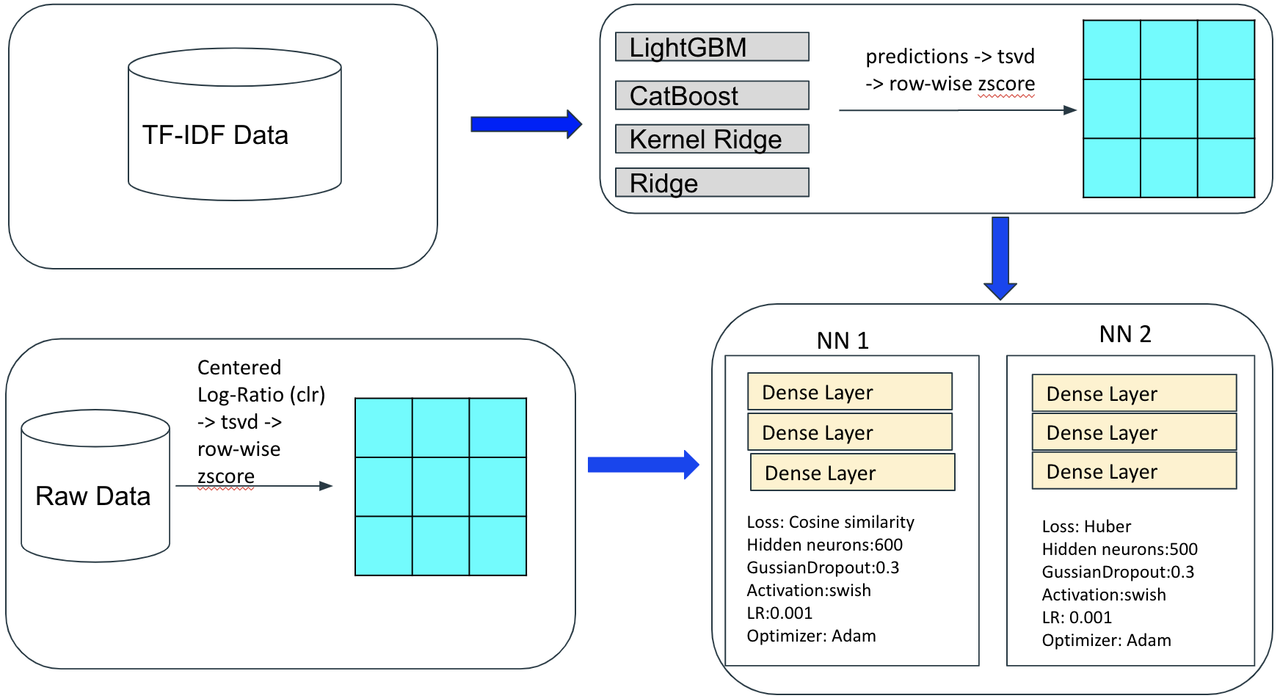
Cite
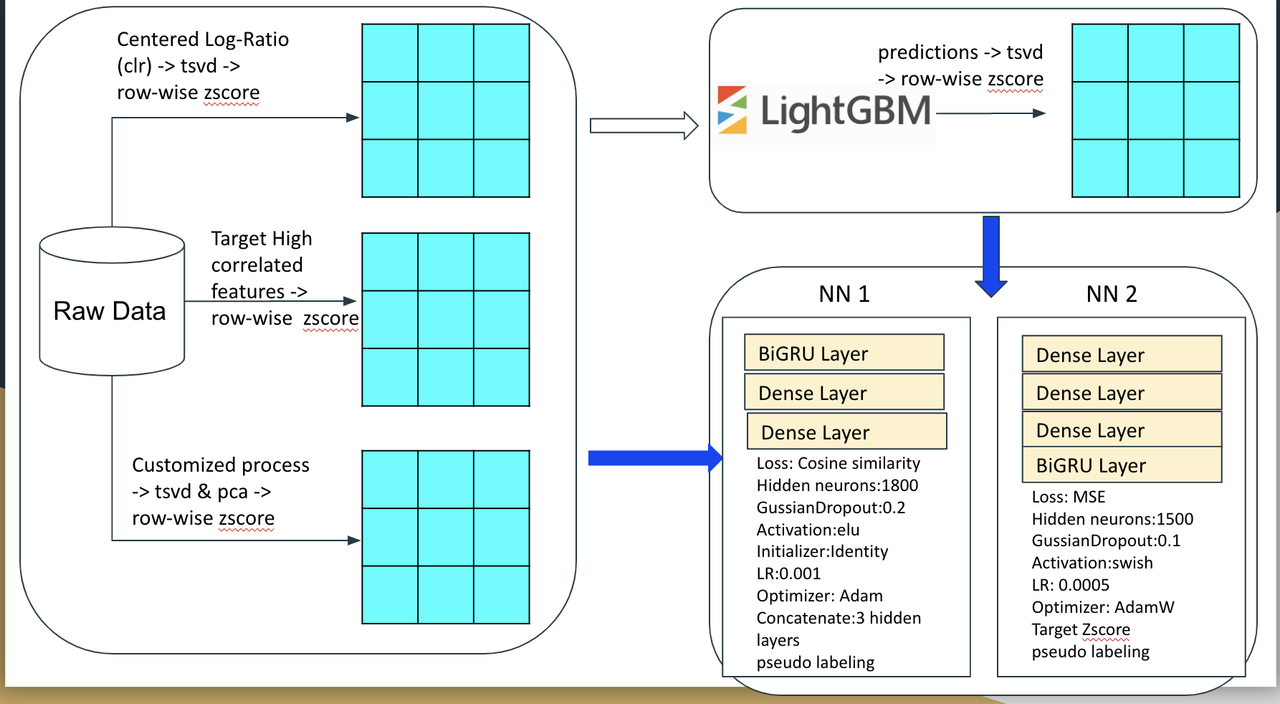
Multi
预处理
1) 中心化对数比率变换(CLR) 是cite和multi任务中最好的归一化方法,我是从《Nature》的文章中发现的这个方法。https://www.nature.com/articles/s41467-022-29356-8
2) 与目标具有高相关性的原始特征。
3) @baosenguo 设计的微调过程:
- 使用原始计数:
- 归一化:按特征的均值进行样本归一化
- 变换:平方根变换
- 标准化:特征z-score
- 批次效应校正:将“day”作为批次,对于每个批次,我们计算列方向的中位数以获得代表该批次的“中位数样本”,然后从该批次的每个样本中减去该样本。这种方法可能不会带来太多改进,但它足够简单以规避风险。
4) 输入神经网络前进行逐行z-score变换。
验证
这次比赛最大的挑战是如何为公共测试集中未见过的供体以及私有测试集中未见过的日期和供体构建一个稳健的模型。在早期阶段,我使用了随机K折交叉验证,CV分数和LB分数匹配得很好,所以我们不需要担心供体域偏移。但是时间域偏移是不可预测的,在团队合并后,我们通过“跨日验证”(按日期GroupKFold)逐一检查我们的特征,以确保所有特征都能改善每一天的表现。
模型
Lightgbm
训练了4个具有不同输入特征的lightgbm模型,然后将oof(袋外)预测转换为tsvd,作为nn模型的元特征:
-- 库大小归一化和log1p变换后的计数 -> tsvd
-- 原始计数 -> clr -> tsvd
-- 原始计数
-- 带有原始目标的原始计数
一个技巧是将原始计数的稀疏矩阵直接输入lightgbm,并设置较小的 "feature_fraction": 0.1,这给nn模型带来了很大的改进。NN (神经网络)
基本上3层MLP效果很好,一个技巧是用GRU替换第一个全连接层,或者在最后一个全连接层之后添加GRU。
Cite的目标被转换为具有负值的dsb,与ReLU相比,ELU处理负目标值要好得多,Swish在cite和multi任务上也表现良好。
在早期阶段,我发现余弦相似度是我模型的最佳损失函数,团队合并后,我向队友学习使用MSE和Huber来构建更多不同的模型。
代码笔记本
[简单cite版本]
https://www.kaggle.com/code/senkin13/2nd-place-gru-cite