第4名方案
召回模型
(推理耗时 2小时+,使用 2 T4 显卡耗时 1小时)
- 成对式,双塔结构,骨干网络使用 sentence-transformers/all-mpnet-base-v2。
- 在训练数据上继续进行 MLM(掩码语言模型)预训练。
- 预测每个 markdown 后面是否紧接着某个代码单元(同时添加了一个内容为 'the end of notebook' 的伪造末尾代码单元)。
- 在同一个 notebook 内选择 9 个负样本(相比使用 4 个负样本,离线和在线效果都更好)。
- 对于代码单元,编码其自身以及前后各 2 个代码单元。
- 交叉熵损失,以余弦相似度 / 学习到的温度参数(最终约为 0.002)作为输入 logits。
- 离线 tau 分数 897(对每个代码位置的平均召回分数)。
- 延迟提交分数为 8936。
- 召回模型是关键模型,因为排序模型和上下文排序模型都使用了它的输出。
- 这里的主要缺点是如果使用 9 个负样本,召回模型会非常消耗 GPU 资源。我使用了 8*V100,在所有训练数据上训练 1 个模型大约需要 30 小时。
成对排序模型
(推理耗时 2小时+)
- 成对式,拼接输入,骨干网络使用 deberta-v3-small。
- 仅对召回模型最大概率 < 0.8 的 markdown 进行推理,因此只对约 50% 的 markdown 进行推理(重排序)。
- 离线 tau 分数 905。
上下文排序模型
(推理耗时 2.5小时+)
修改自 Stronger Baseline with Code Cells。
- 骨干网络使用 deberta-v3-small。
- 将 3 个 markdown 作为一个组(对每个实例一次性推理)。
这些组是利用召回模型选择的,选择具有相似代码分数的 markdown 组成一个组。 - 通过召回模型选择 40 个代码(训练时使用召回模型的 OOF)。
这也是一个关键点,训练时使用召回模型提供的采样概率进行负采样,推理时只需选择召回概率最高的代码。比赛结束后我了解到大多数顶尖队伍使用了更多的代码,更多的上下文/代码是获胜的关键。
训练时仅使用带有一定失真(随机性)的间隔选择代码,然后推理时使用召回模型选择的 top 代码可以提高 0.1+。我在上线前测试了一个上下文模型,从 8806(无召回模型)提升到了 8892(使用召回模型)。
如果训练时使用召回模型选择,或者带有采样概率,效果会再好 0.05+。 - 将召回模型的 OOF 分数作为输入添加到 BERT 中,提升了 0.004。
不确定是否过拟合,所以我选择了一个包含它的提交(9147)和一个不包含它的提交(9143)。我犯了一些错误,没有时间重新训练,只对带有 OOF 分数的模型微调了 3 个 epoch,所以这个 OOF 方法本应该提升更多,我认为应该是 2k+,你可以从第一个 epoch 看到下面巨大的提升。
最终我们看到从 9162 提升到了 9170。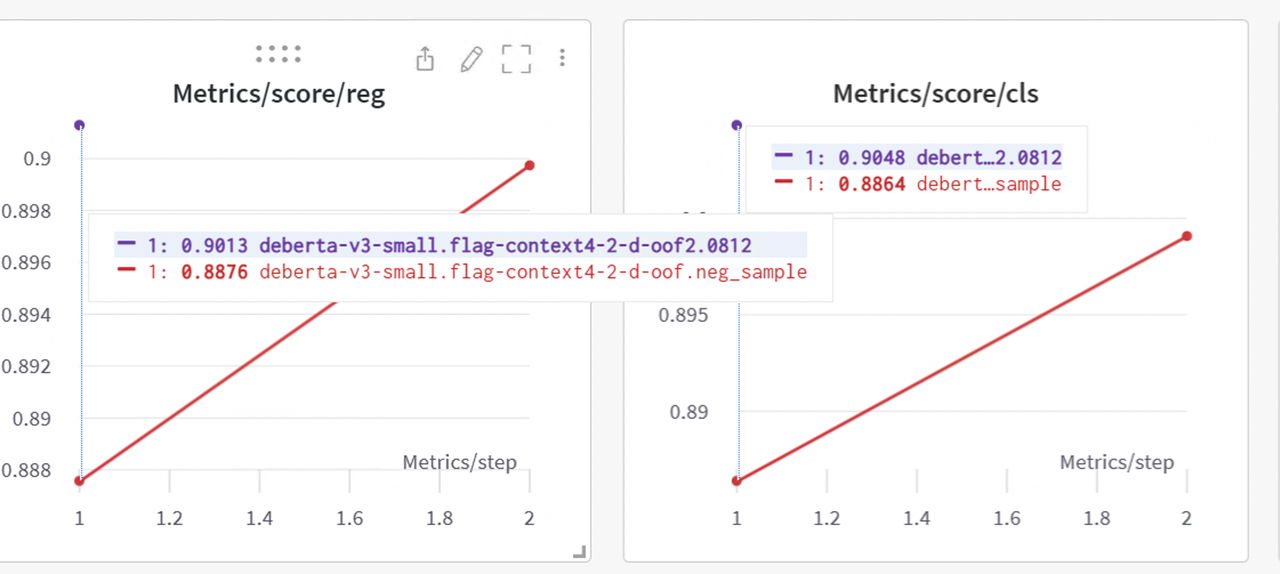
- 多损失函数(num_classes 为 100 的分类任务 + 用于预测每个 markdown 相对排名的 MAE 回归任务)。
- 离线 tau 分数 916(有趣的是,这是分类输出)和 tau 分数 914(回归输出)。
GBDT 模型融合
(推理耗时 5分钟)
- 使用了 CatBoost 和 LightGBM,在线上帮助提升了约 6k。
- 离线 tau 分数 922,在线分数 9147。
最重要的特征如下所示:
xpc 代表成对拼接排序模型
xc 代表上下文排序模型
xp 代表成对双塔模型(召回模型)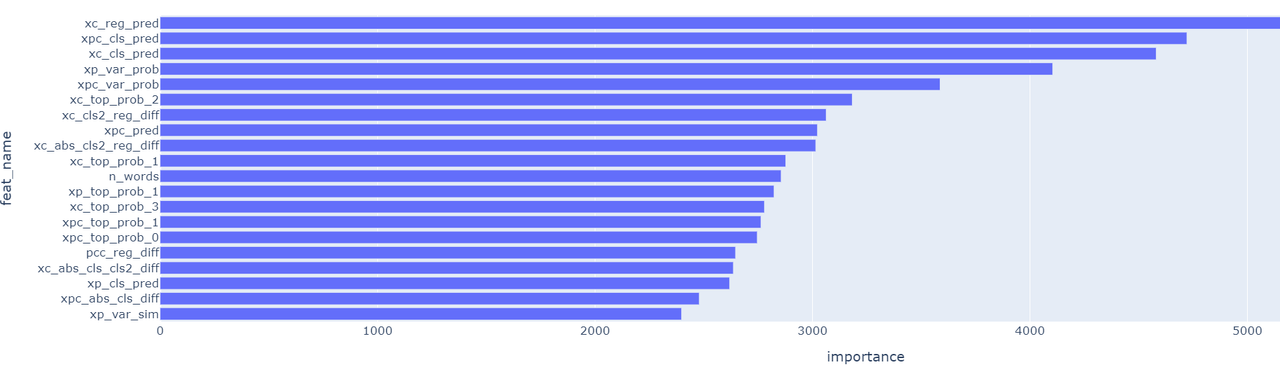
总结与感想
刚刚了解到 deberta-v3-large 配合大输入会更好,更多的上下文(