第6名解决方案
首先,感谢主办方举办了一场充满挑战且有趣的比赛。其次,祝贺所有的获奖者!我的排名比我预期的要好,但不幸的是,我仍然刚好排在获奖区之外。幸运的是,前10名的团队仍有1000美元的奖金。
以下是我的解决方案详情:
相对位置到绝对位置的预测

(我在LaTeX中输入了这个公式并截图。抱歉质量不佳。更好的版本请查看我代码仓库中的 write_up_6th_solution.pdf)
网络架构
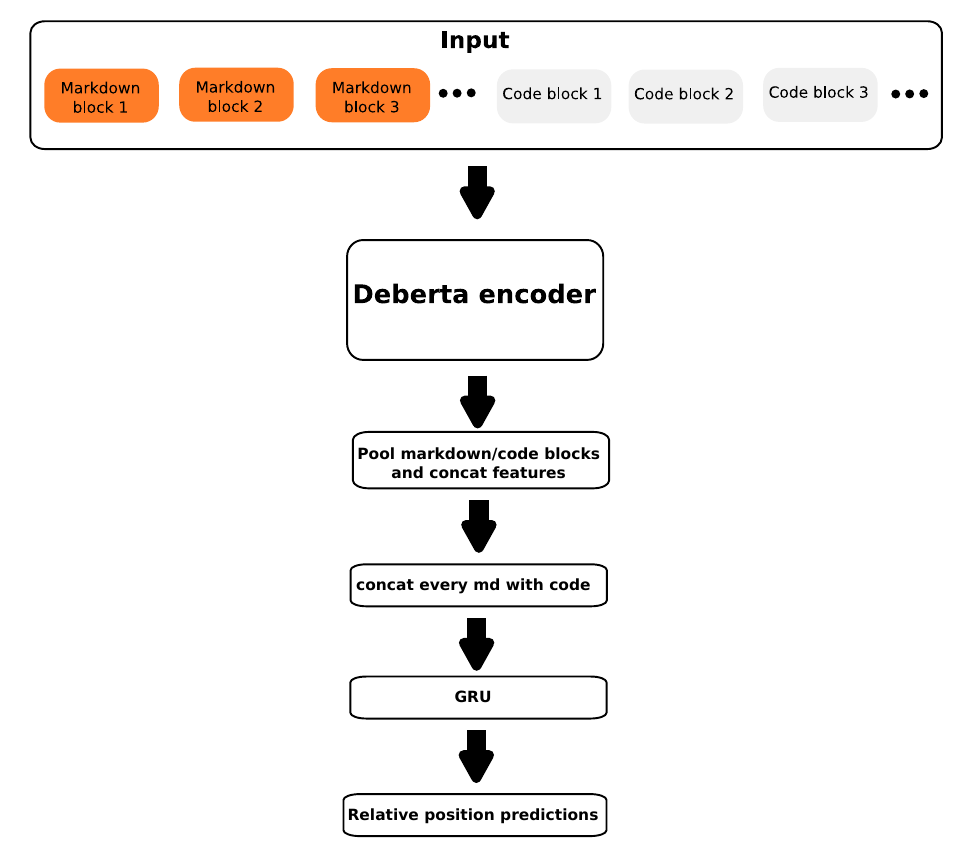
我的网络架构主要由一个DeBERTa编码器和一个GRU层组成;概览如下图所示。首先,Markdown块和代码块被分词并连接。在训练过程中,首先使用10个Markdown块和20个代码块,最大长度为1100;然后使用10个Markdown块和40个代码块,最大长度为1600再训练5个epoch;之后权重被再次重新训练,使用20个Markdown块和80个代码块,最大长度为3160。
在Markdown和代码块连接之后,使用DeBERTa large编码器对文本进行编码,然后对每个Markdown和代码块进行池化。接下来,将特征连接到池化的特征向量(在后面的章节中讨论)。每个Markdown块特征向量然后被连接到代码块特征向量序列,接着使用一个GRU网络来预测该Markdown块相对于每个代码块的相对位置。最后,根据公式1计算Markdown单元的绝对位置。训练时使用MAE损失。
特征
使用了以下特征:
- 给定Notebook中的Markdown单元数量(除以128进行归一化)
- 给定Notebook中的代码单元数量(除以128进行归一化)
- Markdown单元与总单元数的比率
这些特征与Markdown单元的池化特征向量连接。池化的代码单元特征向量也与它们的绝对位置连接。
MLM (掩码语言模型)
使用了掩码语言模型预训练,输入文本的排列方式与微调时相同。MLM概率设置为0.15,模型训练了10个epoch。使用的最大序列长度为768,最多包含5个Markdown单元和10个代码单元。
推理与TTA (测试时增强)
在推理过程中,我试图预测尽可能多的Markdown单元的位置。我能够使用最大长度4250,包含100个代码块和30个Markdown块。代码块最多26个token,Markdown块最多64个。Notebook根据Markdown/代码块的数量进行排序,以减少推理时间。
因为对于超过30个Markdown块的长序列,我无法同时预测所有块的位置,需要多次前向传播来预测所有Markdown块。因此,模型从未同时看到所有的Markdown块。为了抵消这一点,我在每次开始新的推理周期时随机打乱Markdown单元来进行测试时增强(TTA),这样模型将在长序列中看到不同的Markdown单元组合。对于较短的序列,这只是在推理过程中改变了Markdown单元的顺序。
对于我最好的推理Notebook,总共使用了3个推理周期(3xTTA)。3xTTA将分数从0.9067提高到了0.9100。
无效尝试
- 尝试翻译非英语的Markdown单元并没有给我带来任何改进。我尝试了Facebook的m2m100 418M模型。
- 将代码和Markdown单元分开,并对连接的代码和Markdown单元分别通过DeBERTa进行两次前向传播。
- CuBERT没有成功,因为我无法修复分词器的问题。
- 使用最大池化代替平均池化。
参考资料
我使用了Khoi Nguyen的解决方案作为基线:https://www.kaggle.com/competitions