第二名解决方案(已更新代码/Notebooks)
首先,感谢所有的组织者和Kaggle工作人员,祝贺所有的获奖者,并感谢我出色的队友 @kneroma 和 @tikutiku!凭借这枚金牌,@tikutiku 和我终于成为了竞赛 Grandmaster。我们已经发布了我们的代码/Notebooks:
以下是我们解决方案的总结。我们最好的 Private 分数是 0.553,我们最终选择的最佳 Private 分数是 0.554。如果有任何问题,请随时提问。
Transformer 建模
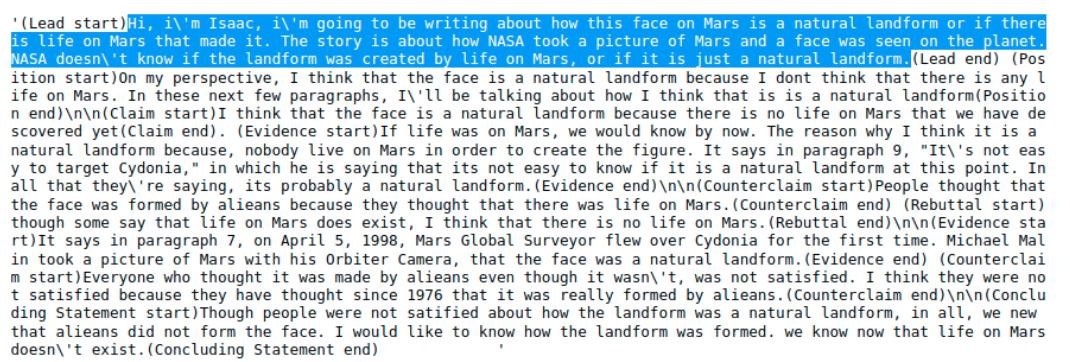
我们团队的每位成员都有自己训练 Transformer 模型的流程。从宏观层面来看,我们的 Transformer 模型会查看每篇文章的整体,并通过池化语篇标记或在每段语篇前添加分类标记来输出每段语篇的有效性预测。重要的是,直接输入文章会导致模型不确定需要在哪里进行预测,为了解决这个问题,我们要么使用提示(例如,将 f'({discourse_type} start)' 和 f'({discourse_type} end)' 拼接到每段语篇的开头和结尾,以标记需要预测的位置),要么简单地拼接添加到分词器中的特殊标记(例如 f'<{discourse_type}>' 和 f'<{discourse_type}\>')。您可以在下面找到一个带有高亮片段的示例。
编码器
Deberta 效果最好,因为(在我看来)它支持无限的输入长度,并使用带有相对位置嵌入的解缠注意力机制;事实上,我们的集成模型完全由 Deberta 变体组成。对我来说,在池化后的语篇表示上添加 GRU/LSTM 也是有帮助的。Tom 使用了我在上一次 Feedback 竞赛中使用的 SlidingWindowTransformerModel(链接),这稳定了他的训练。
预训练
Kkiller 使用了他在上一次竞赛解决方案中的预训练权重(链接),而 Tom 和我发现预训练的 tascj0 模型是很好的起点。我们使用了 tascj0 在上一次 Feedback 竞赛后发布的一些权重,Tom 还自己预训练了一些新模型。如果您想了解更多,请查看 tascj0 的解决方案帖子(链接)。此外,Tom 对他的一些模型使用了 MLM(掩码语言建模)。此外,我们