第5名解决方案
首先,感谢比赛主办方举办这次比赛,也感谢伟大的队友们 ( @shinomoriaoshi, @horsek, @runningz, @nickycan )。
同样感谢社区在 Notebook 和 Discussion 中分享的许多想法。
注意:这篇文章只是一个简要总结,更详细的信息将由我的队友更新或作为新主题发布。
总结
我们集成了 6 个 Token 分类模型和 1 个 Sequence 分类模型。
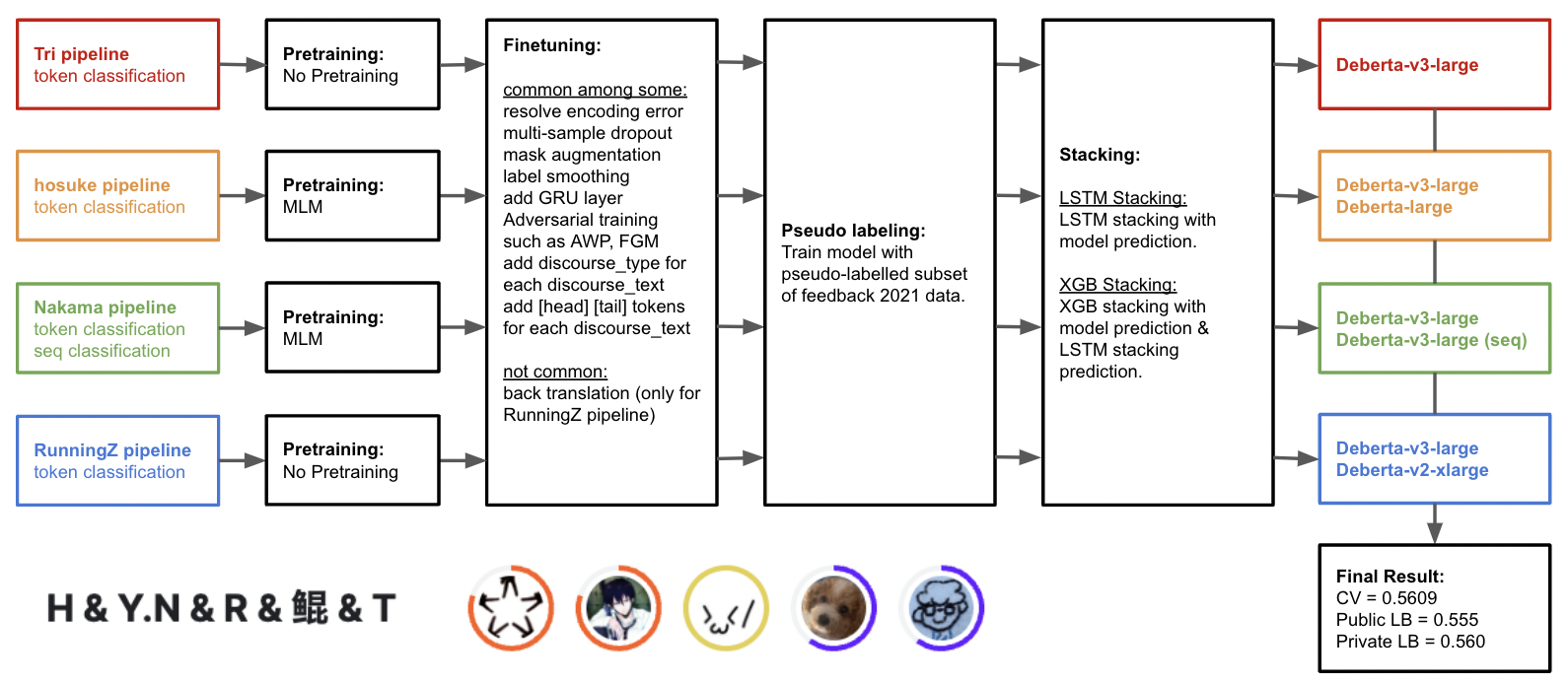
模型
我们训练了以下模型并将其用于最终提交。
- tri( @shinomoriaoshi ) 的流程
- Token 分类 Deberta-v3-large
- housuke( @horsek ) 的流程
- Token 分类 Deberta-v3-large
- Token 分类 Deberta-large
- nakama( @yasufuminakama ) 的流程
- Token 分类 Deberta-v3-large
- Sequence 分类 Deberta-v3-large
- RunningZ ( @runningz ) 的流程
- Token 分类 Deberta-v3-large
- Token 分类 Deberta-v2-xlarge
- 鲲 ( @nickycan ) 的流程
- 主要参与效率赛道
主要有效方法
- MLM 预训练
- 解决编码错误
- 该方法曾在 2021 年 Feedback Prize 比赛中使用过。
- https://www.kaggle.com/competitions/feedback-prize-2021/discussion/313330
- Mask 数据增强
- 该方法曾在 2021 年 Feedback Prize 比赛中使用过。
- https://www.kaggle.com/competitions/feedback-prize-2021/discussion/313424
- 对抗训练 (AWP, FGM)
- 该方法曾在 2021 年 Feedback Prize 比赛中使用过。
- https://www.kaggle.com/competitions/feedback-prize-2021/discussion/313177
- 多样本 Dropout (Multi-sample dropout)
- 该方法曾在 Google QUEST Q&A Labeling 比赛中使用过。