太长不看版 (TL;DR)
我的方案主要包含以下几个特点:
- 本地验证策略:
- 训练集:所有131个不计分物种 + 66%的21个计分物种。
- 验证集:33%的21个计分物种。
- 使用
StratifiedGroupKFold(按author分组)。
- 模型集成:PANNs + PaSSTs(使用 GeM pooling (p=3))。
- 阈值策略:按组设定阈值(固定分位数)。
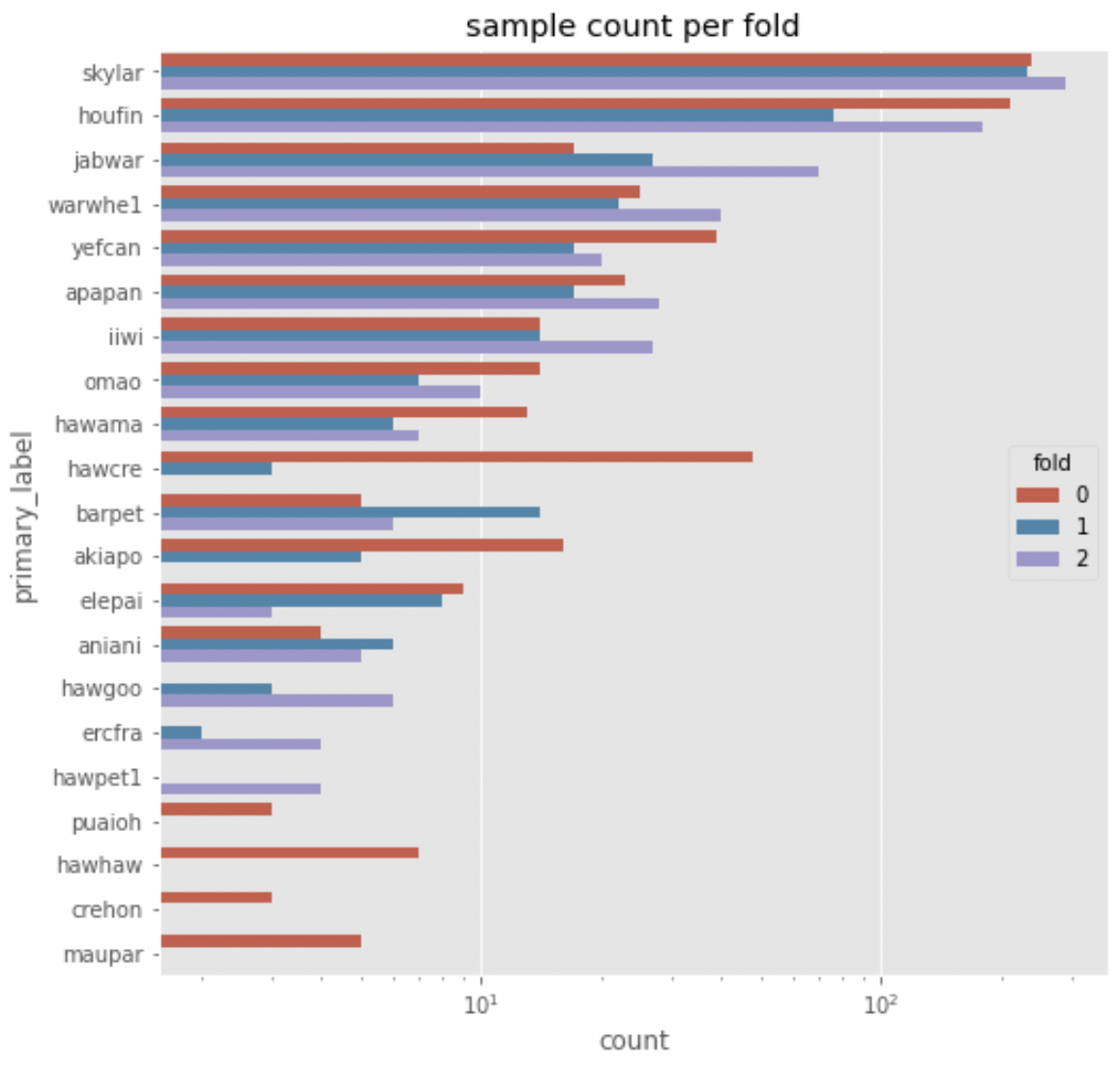
本地验证策略
- 所有131个不计分物种均被用于训练。
- 21个计分物种使用
StratifiedGroupKFold分为3折。
为了观察域偏移(domain shift)的影响,我确保同一作者不会同时出现在训练集和评估集中 [1]。
模型
模型由 PANNs 和 PaSSTs 的集成组成。
PANNs
PANNs 的代码改编自2020年第6名的方案 [2]。主要改动如下:
- 时间窗口设为 20 秒。
- 使用 mixup + cutmix 数据增强(改编自公开笔记 [3])。
- 主干网络:ResNet-34。
- 使用 FocalLoss。
- 使用 AdamW 优化器。
- 训练 40-100 个 epoch。
PaSST
源代码改编自官方实现 [4]。主要改动如下:
- 基于音频的增强,如高斯噪声。
- 使用已训练的 PANNs (ResNet-34) 生成的伪标签进行知识蒸馏。
- 使用 FocalLoss。
- 使用 AdamW 优化器。
- 训练 40 个 epoch。
关于知识蒸馏
损失函数是以伪标签为标签计算的损失与以原始正确标签计算的损失的平均值。
loss(pred, y, y_pseudo_label) = 0.5 * (loss(pred, y) + loss(pred, y_pseudo_label))
集成策略
总共 8 个模型(PANNs x4 + PaSST x4)的预测结果通过 GeM pooling (p=3) 进行聚合。
阈值策略
参考2021年第二名的方案 [5],我固定了预测值的分位数并设定阈值 [6]。
我的不同之处在于,我将计分物种分为以下四组,并为每组分别设定阈值:
- top5: ['skylar', 'houfin', 'jabwar', 'warwhe1', 'yefcan']
- mid_top5: ['apapan', 'iiwi', 'omao', 'hawama', 'hawcre']
- mid_low5: ['barpet', 'akiapo', 'elepai', 'aniani', 'hawgoo']
- low6: ['ercfra', 'hawpet1', 'puaioh', 'hawhaw', 'crehon', 'maupar']
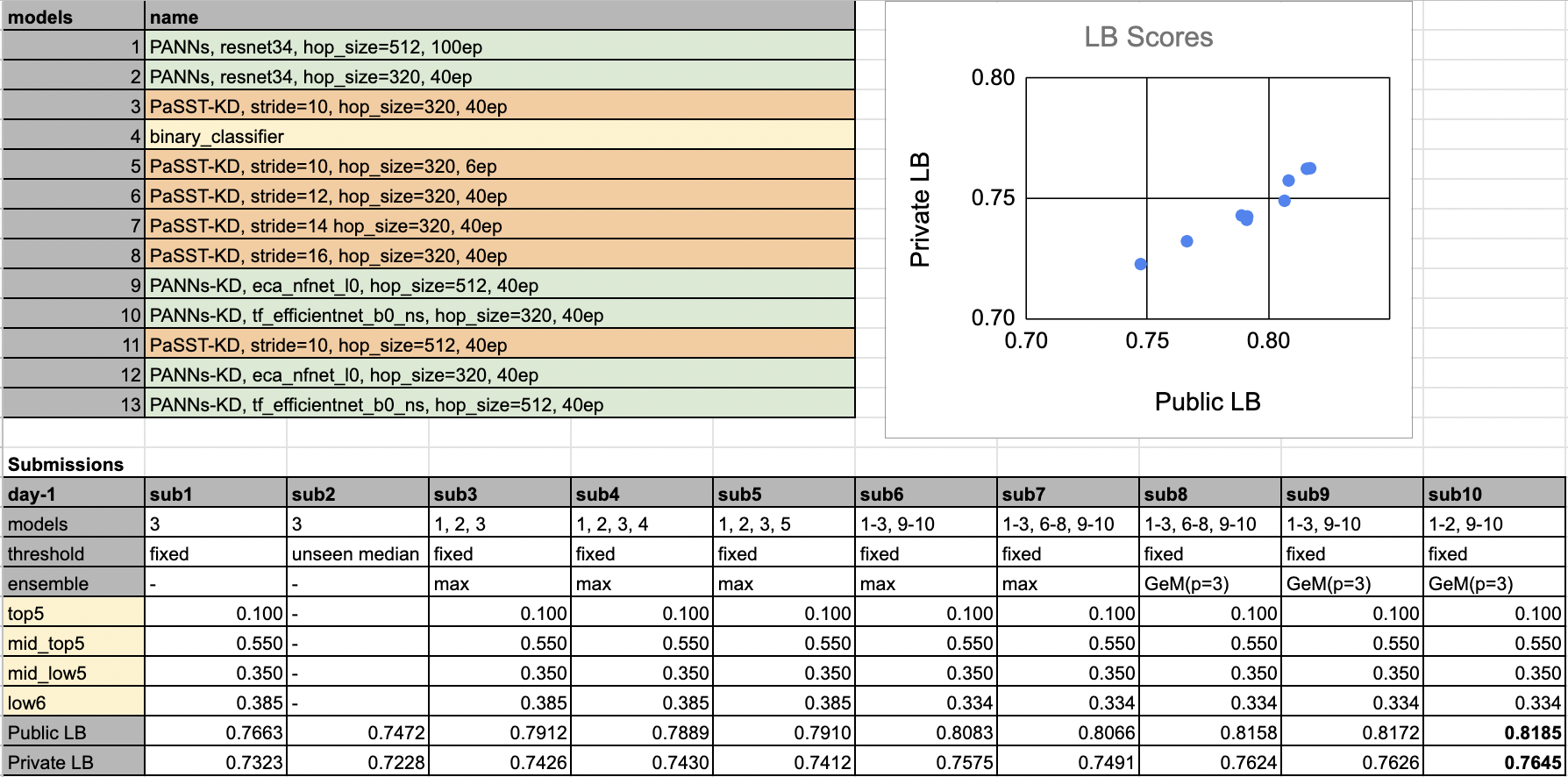
最终提交模型各组的阈值如下。这些是针对 Public LB 优化后的结果。
top5, mid_top5, mid_low5, low6 = [0.100, 0.550, 0.350, 0.334]
评估结果
以下是包括最终提交在内的顶级提交的评估结果。
更新:后期提交(sub10)的结果显示,不包含 PaSST 的集成效果略好于包含 PaSST 的集成(0.7626 -> 0.7645)。因此,在我的实验中,PaSST 并未产生正面效果。
未起作用的方法
- 软平衡准确率损失。
- 二分类器。