第50名方案
感谢所有参与者和举办这次比赛的主办方。
这是我的解决方案以及我尝试过的方法。
我关注的重点
正如我在这个讨论帖中提到的,我认为这次比赛需要考虑以下三个方面。
-
获得高CV分数
这是理所当然的,但需要使用更好的模型来提高交叉验证分数。
我印象中很多人使用了 @hidehisaarai1213 在2021年鸟类比赛发布的Notebook中改进的PANNS模型。我也使用了这个模型,达到了 CV:0.789 (f1 Score), Public:0.739, 和 Private:0.711。
然后,在比赛中期,我转而使用另一个模型(我将在下面解释),并提升到了 CV:0.805(f1 Score), Public:0.7634, Private:0.7210(单模型最佳成绩)。 -
应对域偏移的措施
有几个模型CV分数很高但LB分数很低。这可能是由于训练数据和测试数据之间存在域偏移。作为一种对策,插入噪声的增强方法是有效的。特别是高斯噪声和粉红噪声效果显著。
使用这些增强训练的模型虽然CV分数相对较低,但Public分数有所提高。 -
选择合适的阈值
在这次比赛中,由于没有测试声景(在与测试数据相同条件下收集的数据),阈值必须手动设置。这个合适的阈值通常与模型验证阶段的最佳值相差甚远,因此调整是一个重要步骤。由于Public分数是选择阈值的唯一可用因素,我们别无选择,只能过拟合Public分数(尽管如此,LB并没有像我们预期的那样波动很大)。
解决方案
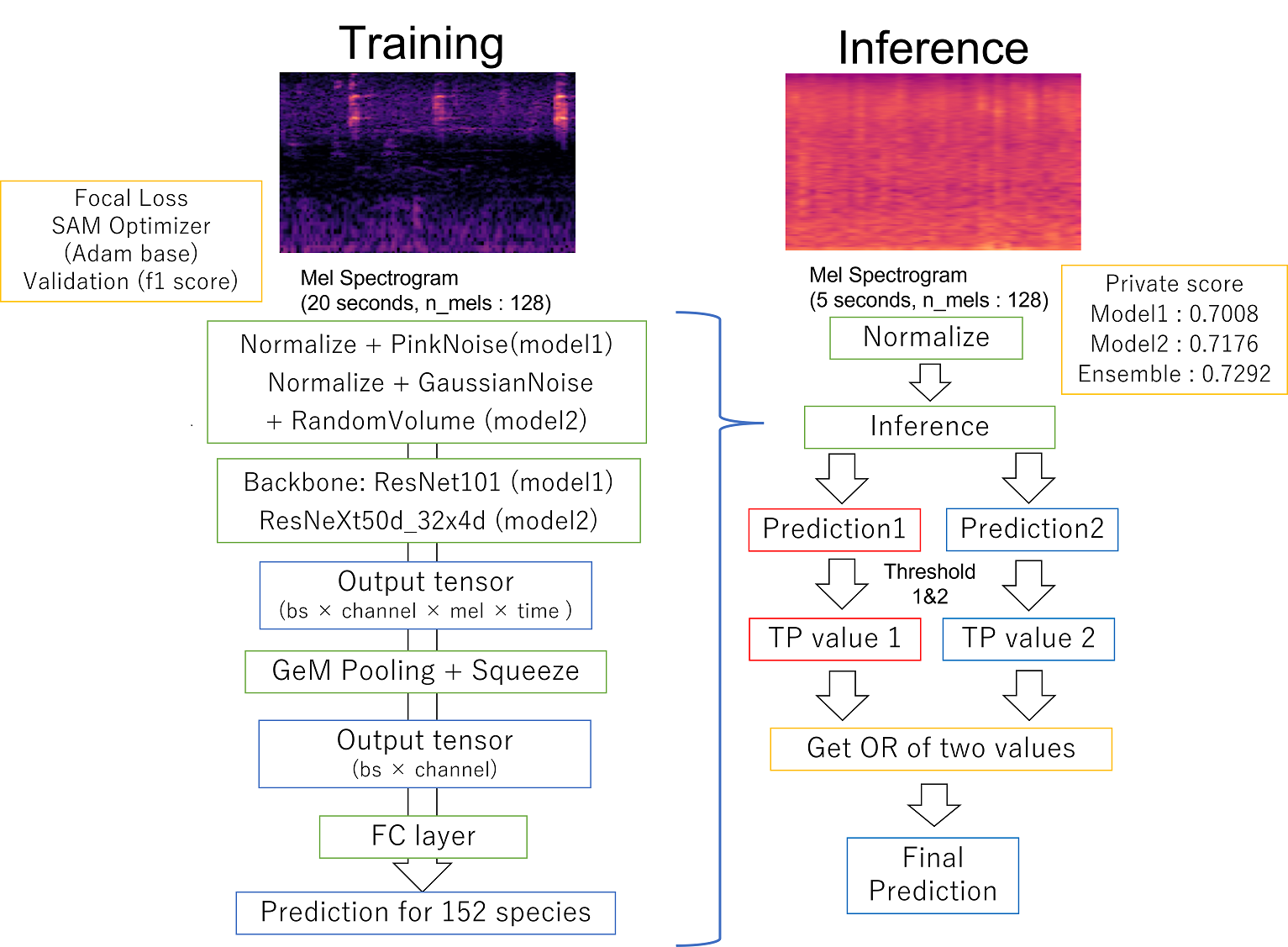
单模型
如图所示,声音数据被转换为20秒分段的mel频谱图,然后添加增强(标准化,粉红噪声)。
对输入添加增强(模型1:标准化&粉红噪声,模型2:标准化&高斯噪声&随机音量),并使用 ResNet101d(模型1)和 ResNeXt50d_32x4d(模型2)提取特征。
输出是 批次大小 × 通道 × 频率 × 时间(四维)。
然后,使用 GeM pooling 在频率和时间方向上压缩特征,结果返回为 批次大小 × 通道 的二维张量。
然后应用全连接层获得152维的输出。
我还以0.25的概率应用了 MixUp 作为增强。我相信这提高了模型的鲁棒性,尽管幅度很小。
作为损失函数,我使用了基于 BCEWithLogitsLoss 的 Focal loss (链接)。
我还使用了基于 Adam 的 SAM 优化器作为优化器 (链接)。
通过将优化器更改为 SAM,在除优化器外所有条件相同的实验中,声音事件检测模型的Public分数提高了约0.02。
集成
我没有将模型输出的预测平均值通过阈值,而是将通过阈值后的真/假值进行逻辑“或”或逻辑“与”运算,作为最终的预测结果提交。通过应用逻辑“或”的集成方法,我从Private分数分别为 0.7176 和 0.7008 的预测中,获得了 Private分数为 0.7292 的输出结果(我相信它们是有效的)。
无效的尝试
- 使用复杂模型作为骨干网络(例如 Swin Transformer)
- PaSST (链接)
- 强行对获得的特征应用多头注意力机制
- 使用伪标签