第一名解决方案
感谢 H&M 和 Kaggle 团队为我们提供了如此精彩的比赛。感谢我的队友 @h4211819,我们最终获得了第一名。这场比赛没有数据泄露,CV(交叉验证)与 LB(排行榜)相关性稳定,并且有无限的改进空间,我们非常享受探索无限可能性的准确性边界。
概述
这次比赛最有趣的部分是我们需要自己生成训练集和测试集,候选生成策略是突破准确性限制的关键,好的特征工程或建模可以接近这个限制。我们的解决方案使用了多种检索策略 + 特征工程 + GBDT(梯度提升决策树),看起来简单但非常强大。
我们主要生成最近的流行商品,因为时尚变化很快且具有季节性,我们尝试添加冷启动商品,但由于缺乏交互信息,它们永远不会被排在前12名。用户和商品的交互信息始终是推荐问题中最重要的,我们创建的特征几乎都是交互特征,图像和文本特征没有起到作用,但应该对冷启动问题有用。
几乎50%的用户在最近3个月内没有交易,因此我们为他们创建了许多累积特征,并为活跃用户创建了上周、上月、上季度的特征。
我们使用6周的数据作为训练集,最后一周作为验证集,为每个用户检索100个候选者,它具有稳定的 CV-LB 相关性。我们专注于将单个 LightGBM 模型改进到最后一周,CV 为 0.0430,LB 为 0.0362。在最后一周,我不得不租用 GCP 的大内存服务器和 vast.ai 的 GPU 服务器来运行更大的模型以获得更高的准确性。
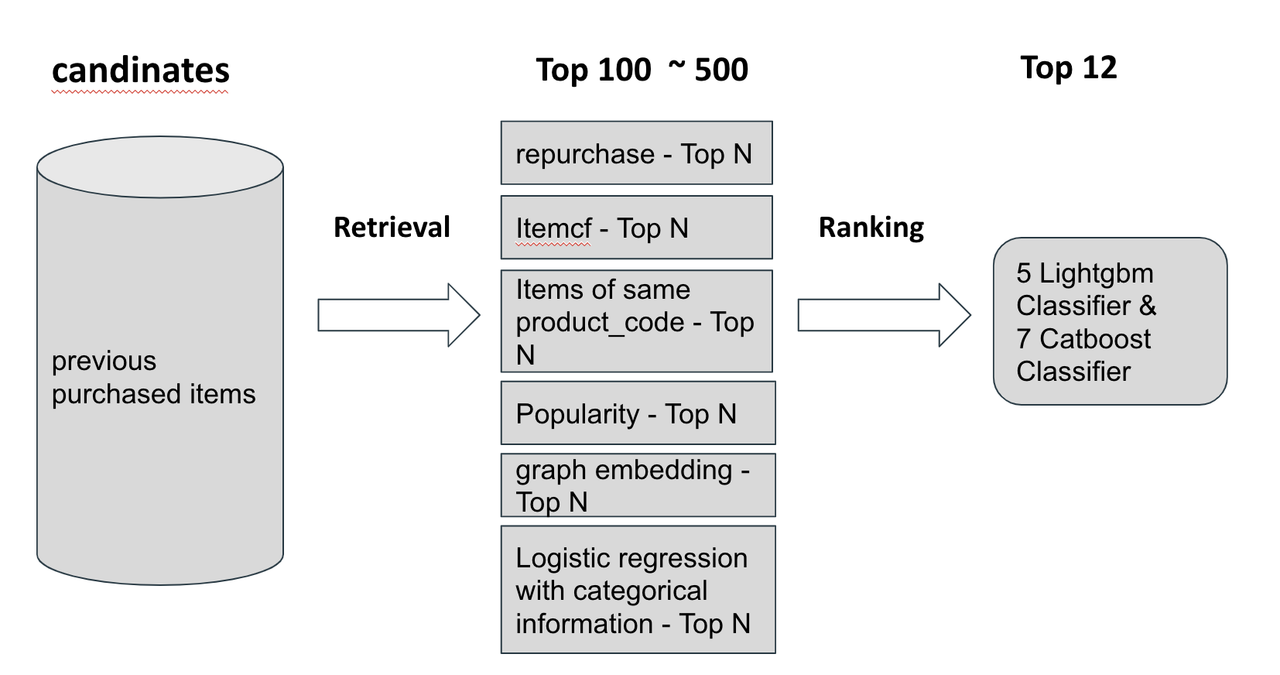
检索(又名:候选生成 | 召回)
在早期阶段,我们专注于增加检索出的100个候选者的命中数量,尝试各种策略以覆盖更多的正样本。
| 周编号 | 命中数@100 |
|---|---|
| 2020-09-16 | 39142 |
| 2020-09-09 | 38427 |
| 2020-09-02 | 41019 |
排序
-
特征工程
基本上,特征是基于检索策略创建的,为复购创建用户-商品交互,为 ItemCF 创建协同过滤分数,为嵌入检索创建相似度,为流行度创建商品计数……类型 描述 计数 上周/月/季/去年同期/所有的用户-商品、用户-类别,时间加权计数…… 时间 交易的第一天、最后一天…… 均值/最大/最小 年龄、价格、销售渠道ID的聚合…… 差值/比率 年龄与购买该商品的平均年龄之差,某用户购买的商品数量与该商品总数量的比率 相似度 Item2Item 的协同过滤分数,Item2Item 的余弦相似度,User2Item 的余弦相似度 -
下采样
如果我们为每个用户检索 100~500 个候选者,负样本的数量会非常大,因此必须进行负下采样,我们发现每周 100 万 ~ 200 万个负样本具有更好的性能。neg_samples = 1000000;