第4名解决方案
感谢 H&M 和 Kaggle 团队组织了这么棒的一场推荐系统竞赛。
感谢 @paweljankiewicz、@titericz、@cdeotte 以及许多 Kaggle 参与者的精彩讨论和 Notebooks。
我希望这次能获得一枚单人金牌,所以我从一开始就决定独自参加这次比赛。
概述
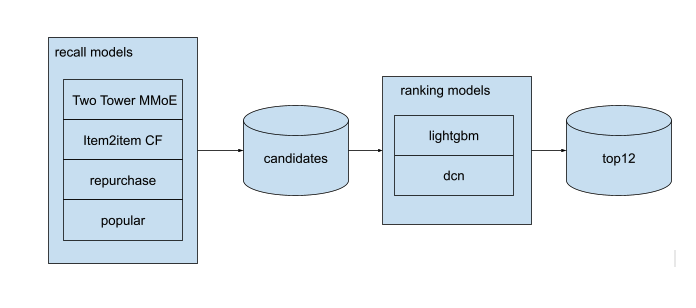
我遵循了 @paweljankiewicz 在 Addressing common questions and what the competition is really about 中建议的相同流程。首先,针对每位客户使用不同的召回模型生成候选集。其次,构建一个排序模型,对客户内的候选集进行排序。
交叉验证(CV)设置
我主要参考了 How To Setup Local CV,创建了 5 折交叉验证,并使用其中的 3 折作为训练数据。我也尝试过使用更多的训练数据,但这并没有提高本地 CV 分数和 LB(Leaderboard)分数。
召回模型
我总共开发了 4 种召回模型。
- Item2item CF(协同过滤):物品对之间的关系(购买了 Y 的用户也购买了 Z)。
- 复购:每位客户最近购买的 20 件商品。
- 热门商品:上周的热门排名。
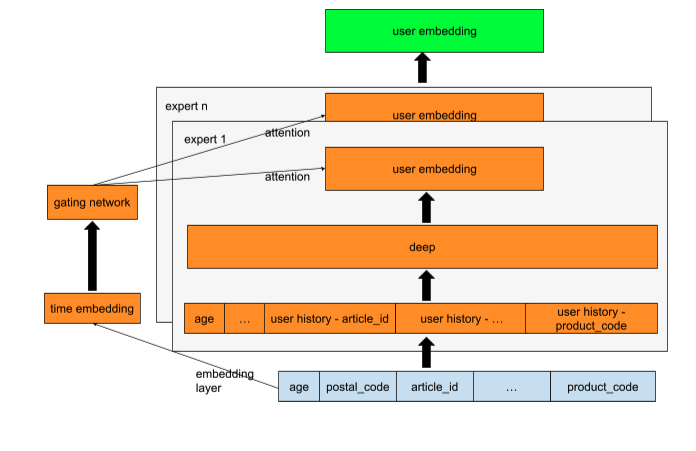
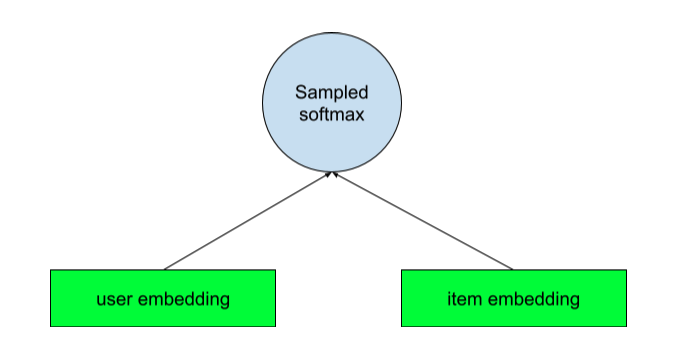
- 双塔 MMoE:我主要专注于提高该模型的性能。因为它可以为所有用户生成任意长度的候选集,而且用户/物品嵌入(相似度)也可以作为排序模型的重要特征。
我使用了一个门控网络,通过为近期活跃客户和非活跃客户使用不同的专家,来确保用户塔能够很好地学习。
排序模型
我主要使用了带有 lambda-rank 目标函数的 LightGBM。我也实现了 https://arxiv.org/abs/2008.13535 中描述的 DCN 模型。但我没有足够的时间去调整它。LightGBM 的分数要好得多。
冷启动用户
双塔 MMoE 模型也可以利用用户人口统计特征为没有购买记录的客户生成候选集。
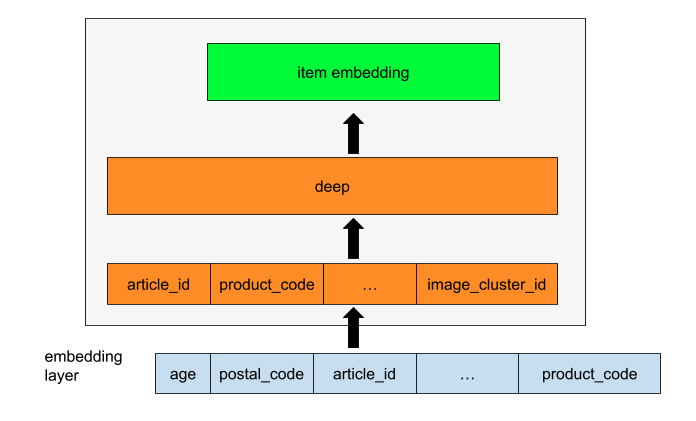
冷启动商品
除了商品元特征外,我还从文本和图像中提取了以下特征。
- 文本:从商品描述中提取 TF-IDF 特征,使用 SVD + K-means 对商品进行聚类。然后使用聚类 ID 作为特征。
- 图像:使用预训练的 tf_efficientnet_b3_ns 骨干网络提取图像向量,使用 PCA + K-means 对商品进行聚类。然后使用聚类 ID 作为特征。
提交结果
最佳本地 CV 分数为 0.039,LB 分数为 0.0349。
我的最终提交通过以下方式结合了我之前的提交:
h-m-ensembling-how-to