第20名方案
非常感谢大家参与这次比赛,特别感谢我的队友 @cdeotte、@horsek 和 @shinomoriaoshi 带来的精彩体验 :)
伪标签
我们的解决方案(像大多数获胜方案一样)非常依赖伪标签技术。
下面的流程图总结了这一过程,我们报告了单个 deberta-(v3)-large 模型在 CV 和 LB 上的改进情况。
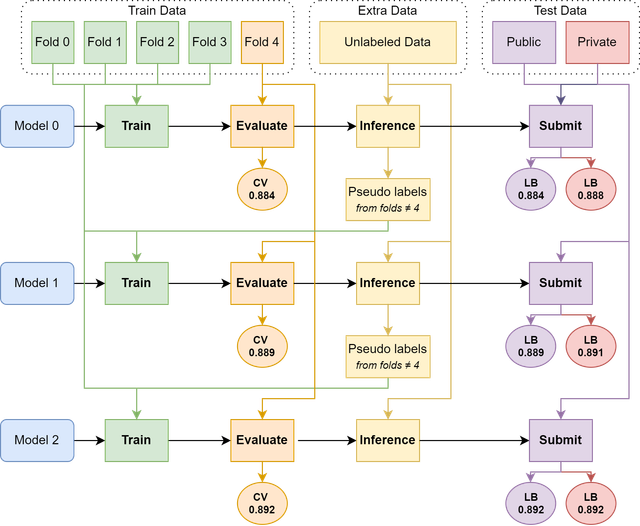
- 额外细节:
- 伪标签是基于模型的融合结果生成的(通常是2或3个模型)
- 我们的一些模型使用了3轮伪标签迭代,有些用了2轮,有些用了1轮
- 模型训练时使用了不同比例的伪标签数据,范围从20%到100%不等
- 我们有不同的流程,并使用了不同的伪标签集以保持多样性。
- 部分模型使用了软伪标签
为了从我们的流程中挖掘更多潜力,部分模型使用了5折平均后的伪标签进行训练。这虽然导致 CV 失去了参考价值,但生成了更强的伪标签,使我们的单模型在公共 LB 上获得了一致的 +0.001 提升。
模型多样性
- 骨干网络:
- deberta-v3-large, deberta-large, deberta-xlarge, electra-large, roberta-large
- 头部网络:
- LSTM 头,作用于最后或最后8层的2层 CNN 头,作用于最后或最后8层的1层全连接头
- 部分模型进行了 MLM 预训练
- 部分模型使用了数据增强(见评论)
后处理
Nakama 的基线在起始字符方面存在问题,只需修复这个问题就能获得不错的(0.001-0.002)提升(见评论)。最后,我们只是使用了 Theo 的 Roberta notebook 将 token 概率转换为字符跨度。我们找不到更可靠的后处理方法了。
模型融合
集成模型的 CV 分数与 LB 相关性不佳,可能是因为标签噪声,所以我们决定直接融合所有最强的模型。以下分数为公共/私有 LB 分数。
Tri (权重=0.2)
- deberta-large : LB 0.890/0.890
- electra-Large : LB 0.891/0.889
Theo (权重=0.6)
- deberta-v3-large : LB 0.892/0.892
- deberta-large : LB 0.892/0.892
- deberta-xlarge (2 折) : LB 0.891/0.892
- roberta-large : 未提交,但大约 ~0.891/0.891
- deberta-xlarge (2 折) : 未提交,但大约 ~891/0.892
Chris (权重=0.1)
- deberta-xlarge (2 折) : LB 0.891/0.892
Hiro (权重=0.1)
- deberta-v3-large 未提交
我们有30个提交分数比我们最终选择的要高,其中包括达到金牌区的单模型。但是中等范围的 0.892 提交和 0.893 提交之间的差异实际上非常小,所以我们对此也无能为力。