[第24名方案]:预训练任务是关键!
首先,感谢 Kaggle 和竞赛主办方在“Feedback Prize - Evaluating Student Writing”结束后提供了这场充满挑战的 NLP 比赛。这篇文章总结了我们团队的努力,与队友合作是一次非常棒的经历!这是我们要写的团队集体成果总结。在专注于 Happywhale 比赛之后,我们没有太多时间参加 NBME 挑战(大约 3 周)。
在阅读了顶尖团队的解决方案后,我们意识到团队缺失的是伪标签(实际上之前就注意到了,只是我们没有像其他团队那样让它发挥作用)。
建模
预训练任务
- 使用 MLM(掩码语言建模)进行任务适应(使用标准的掩码语言建模进行预训练,Token 掩码概率为 0.15):Deberta-V2-xlarge、Deberta-V2-xxlarge 和 Deberta-V3-large。
- 使用 WWM(全词掩码)预训练进行任务适应:Deberta-V2-xlarge 和 Deberta-V3-large。
模型经验
我们尝试了很多模型和自定义头部:
- Deberta-V3-large
- Deberta-V2-xlarge
- Deberta-V2-xxlarge
- Roberta-large
- 带有 LSTM/GRU 头部的 Deberta-V3-large
- 带有自定义头部 (CNN-1D) 的 Deberta-V3-large
- 连接最后 4/12 层的 Deberta-V3-large
部分结果详情见下图:
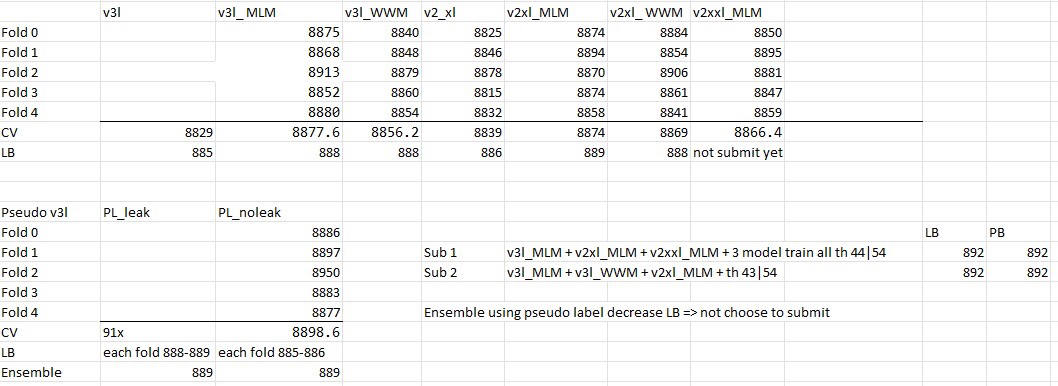
模型融合
我们使用简单的平均值作为最终的集成方案,也许加权平均效果会更好,但我们没有尝试。我也想尝试堆叠,但没有时间。
后处理
我们的后处理方法包含两部分:
- 一部分与第 11 名方案的“Misaligning annotations”(对齐修正)几乎相同。
- 另一部分与第 4 名方案的阈值处理相同,我们的团队针对每个 case num 和 feature num 使用阈值,CV 从 0.895 增加到 0.896,但 LB 略有下降,所以我们停止并在 0.45-0.55 范围内调整(此范围阈值)。我们基于 CV 进行调整以减少对公共 LB 的过拟合,我们使用 CV 和 LB 上的分数增量。后处理在 LB(公共和私有)上的结果增加了约 0.001。我们在公共和私有 LB 上的排名没有太大变化 :D
有效但没时间尝试的方法
- 元伪标签
- 知识蒸馏 (KD)
- Mixup,随机掩码
对我们团队无效的方法
- 多样本 Dropout (Multisample Dropout)
- 伪标签
- LSTM/GRU 头部