第4名解决方案 - 🎖️ 我的第一枚金牌 🎖️ (+源代码已公开!)
大家好!祝贺获奖者以及所有享受这次比赛的人!我看到很多人都很疲惫,我也是……但我获得了我的第一枚单人金牌 🎖️,现在真的很高兴能成为 Kaggle Master!
老实说,我大约在 3 周前才参加这次比赛。感谢社区,我可以加速我的实验并快速提高分数。如果我有更多的时间,也许我能获得更多的机会……🤔🤔
我认为一些技巧和技术在这次比赛中很重要。LightGBM 后处理真的很酷,我从未想过那个主意。我专注于一些技术处理,并设法获得了高分。
解决编码错误
如你所见,文档中有一些异常字符。让我们看看 0D1493FDAAD3:
...
Another reason to talk to multiple people when making a purchase is to learn from their successes. ÃÅf you saw a group of people successfully do what you are trying now, learn what they did to overcome the obstacle.
...有无法识别的字符 ÃÅ,你可能会在其他文档中经常看到这种情况。经过一些尝试,我发现这是关于 cp1252 和 utf8 编码的问题,下面的代码可以清理文档。
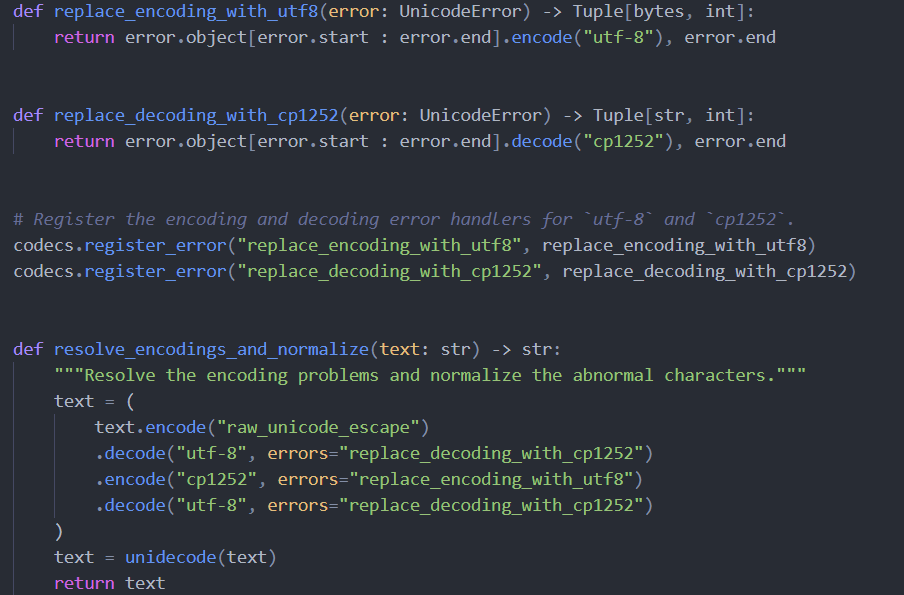
结果如下:
...
Another reason to talk to multiple people when making a purchase is to learn from their successes. If you saw a group of people successfully do what you are trying now, learn what they did to overcome the obstacle.
...实际上,这似乎并没有显著提高最终分数,但我只是应用它以确保万无一失。
因为它减少了文档中的字符,我们必须调整 discourse_start 和 discourse_end 偏移量。为了纠正偏移量,我使用 difflib.SequenceMatcher 来比较字符的差异。详情在我的代码中。
word_ids vs offset_mapping?
因为许多 NER 示例使用带有 is_split_into_words=True 参数的 word_ids,我也尝试用它来标记 BIO 命名的子词标签。然而,我在单折 bigbird base 模型上只得到了 0.595 的公共 LB 分数。所以我尝试了社区的另一种方法,使用带有 return_offsets_mapping=True 参数的 offset_mapping 来制作子词 NER 标签,我得到了 0.630 的公共 LB 分数。
| 模型名称 | 公共 LB 分数 | 私有 LB 分数 |
|---|---|---|
bigbird-roberta-base (单折, word_ids) |
0.595 | 0.609 |
| bigbird-roberta-base (单折) | 0.630 | 0.644 |
| bigbird-roberta-base (5 折) | 0.659 | 0.677 |
为什么会发生这种情况?word_ids 和 offset_mapping 方法有什么区别?经过一些经验尝试,我发现 word_ids 需要使用 .split() 将文本拆分为单词,这会修剪换行信息 \n。由于此任务是识别文档的结构,使用换行符可能是必要的。请记住这一点,因为我将在后面的章节中提到这一