第5名:同步跨度分割与分类 + WBF
首先,非常感谢 Kaggle 团队和 Feedback Prize 团队举办这次比赛,并祝贺所有获奖者!也要感谢我的队友,即 @amedprof 和 @crodoc,感谢他们在过去这艰辛的三个月里的辛勤工作和付出。
在开始时
我们在这次比赛中经历了很多挣扎。我们花了近两个月的时间远离铜牌区,因为我们的策略是探索性的。事实上,Abishek 在比赛初期发布了一个很好的 Kernel,人们可以直接坚持使用它并不断调整超参数以获得不错的分数(银牌区)。但是,我们没有走那条路,我们一直在探索许多想法。
解决方案方法
这里的主流方法似乎是 NER(命名实体识别)。我们没有重新发明轮子,我们也走了这条路,因为它看起来很直接并且能很好地解决问题。事实上,我们测试了一些 QA(问答)方法,但它们不仅太慢(训练和更多的推理),而且分数比我们的 NER 方法略低。
设置 1: 兄弟 NER 与跨度分割
我们使用多任务方法来输出分割分数(对 3 个不同值进行多类分类:0 代表背景,1 代表任何实体内部,2 代表开始)和实体分数(15 个类别)。我们在 NER 中仍然使用 15 个类别,但在计算类别之前,我们将 B-eginning(开始)标记转换为 I-nside(内部)。
骨干网络: 5 折 Deberta-v1 Large + 5 折 Deberta-v1 xLarge(maxlen = 1024,推理期间使用 stride,positinon_biased_inputs=False),训练 5 个 epoch
调度器: 无预热的余弦退火
优化器: AdamW
损失函数: 具有动态余弦类别权重的交叉熵。事实上,我们通过从高值开始并在最后几个 epoch 收敛到 1 来加重稀有类别(反驳和反诉)的权重。
设置 2: 基于 15 个类别的纯 NER,或者通过移除非重叠类别的 B 目标来基于 10 个类别。
骨干网络: 5 折 Deberta Large + 5 折 Deberta xLarge(maxlen = 1024,推理期间使用 stride,positinon_biased_inputs=False),训练 5 个 epoch
调度器: 具有 10% 预热的多项式衰减
优化器: AdamW
损失函数: 交叉熵(类别无权重)
验证策略
我们使用了与 Abishek 分享的相同的验证策略,我们还使用了由 cdeotte 制作的集群的增强版本来制作我们的 MultilabelStratifiedKFold。这些折非常稳定,CV 到 LB 的相关性很好。
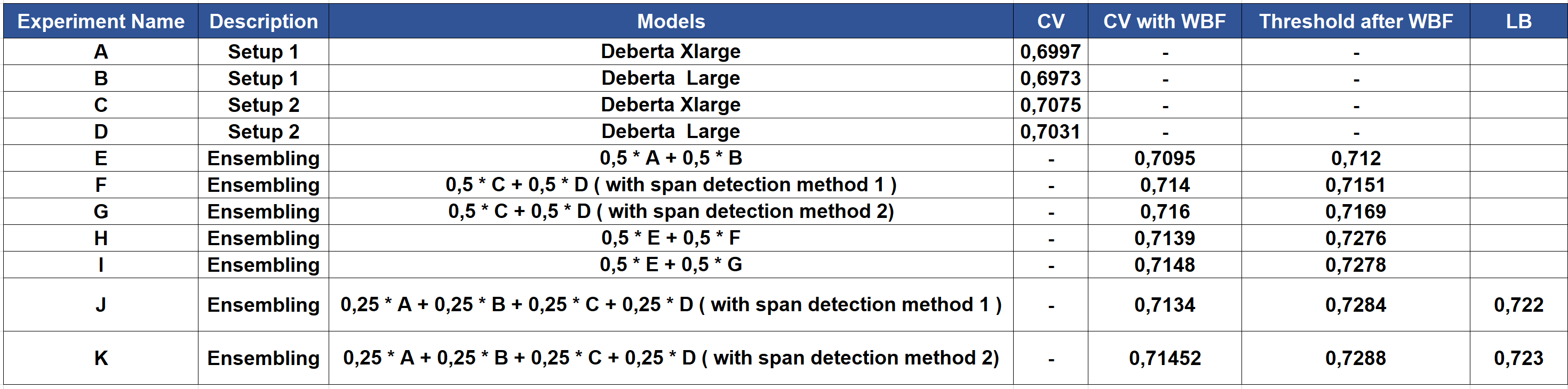
后处理与模型及框的集成
像 cdeotte 的团队一样,我们在最终解决方案中使用了 WBF(加权框融合)。WBF 非常有效,是我们在比赛最后几天排名大幅跃升的主要原因。请查看此标签以了解有关 CV / LB 的更多详细信息。
有效的方法
- 基于 num_tokens 和 score 进行过滤
- 智能框集成 (WBF)
- 随机掩码
- 随机开始(如果训练时没有 stride)
- 小批量大小
- 小学习率
无效的方法
- 在更长的序列上训练
- 训练长文本感知模型:对我们来说,LongFormer、Funnel 和 BigBird 并不比 deberta-v1 好。
- 更多 epoch,更大的批量大小
- 在清洗后的数据上训练
- 使用比 python split 更好的分词器
- QA 代替 NER
- 通过平均单词级别分数来简单打包模型
最后的想法
-
在 10 个标签上训练
我们在这个 Kernel的马尔可夫转移矩阵中看到