第1名方案 - 最近邻方法
2022-01-11 更新了标题。
首先,我要非常感谢 Optiver 和 Kaggle 组织了这场非常有趣的比赛。我以前从未分析过金融数据,但多亏了非常有帮助的教程笔记本,我能够完全沉浸在比赛中。
我不知道我在最终排行榜上的排名,但我公开的亚军(第2名)方案的要点如下:
- 通过逆向工程还原 time-id 顺序的时间序列交叉验证
- 最近邻聚合特征(分数从 0.21 提升到 0.19)
- LightGBM、MLP 和 MoA 的 1D-CNN 的融合
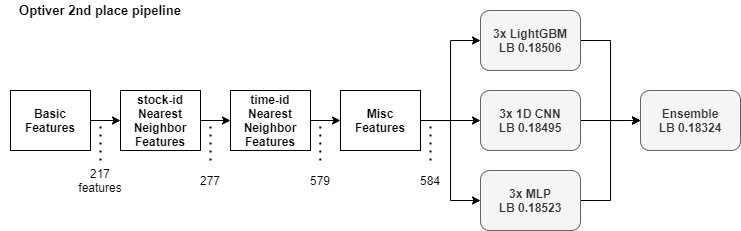
你也可以在这里查看我的笔记本:
https://www.kaggle.com/nyanpn/public-2nd-place-solution
现在,我想介绍一下详细的解决方案。
time-id 顺序的逆向工程
比赛数据中的价格是经过归一化的,但正如讨论中有人指出的那样,你可以使用“tick size”来恢复归一化之前的真实价格。
此外,通过使用 t-SNE 将 time-id x stock-id 的价格矩阵压缩到一维,我能够以足够的精度恢复 time-id 的顺序。
import glob
import numpy as np
import pandas as pd
from joblib import Parallel, delayed
from sklearn.manifold import TSNE
from sklearn.preprocessing import minmax_scale
def calc_price_from_tick(df):
tick = sorted(np.diff(sorted(np.unique(df.values.flatten()))))[0]
return 0.01 / tick
def calc_prices(r):
df = pd.read_parquet(r.book_path,
columns=[
'time_id',
'ask_price1',
'ask_price2',
'bid_price1',
'bid_price2'
])
df = df.groupby('time_id') \
.apply(calc_price_from_tick).to_frame('price').reset_index()
df['stock_id'] = r.stock_id
return df
def reconstruct_time_id_order():
paths = glob.glob('/kaggle/input/optiver-realized-volatility-prediction/book_train.parquet/**/*.parquet')
df_files = pd.DataFrame(
{'book_path': paths}) \
.eval('stock_id = book_path.str.extract("stock_id=(\d+)").astype("int")',
engine='python')
# 使用 tick-size 构建价格矩阵
df_prices = pd.concat(
Parallel(n_jobs=4)(
delayed(calc_prices)(r) for _, r in df_files.iterrows()
)
)
df_prices = df_prices.pivot('time_id', 'stock_id', 'price')
# 使用 t-SNE 恢复 time-id 顺序
clf = TSNE(
n_components=1,
perplexity=400,
random_state=0,
n_iter=2000
)
compressed = clf.fit_transform(
pd.DataFrame(minmax_scale(df_prices.fillna(df_prices.mean())))
)
order = np.argsort(compressed[:, 0])
ordered = df_prices.reindex(order).reset_index(drop=True)
# 使用已知股票 (id61 = AMZN) 纠正 time-id 顺序的方向
if ordered[61].iloc[0] > ordered[61].iloc[-1]:
ordered = ordered.reindex(ordered.index[::-1])\
.reset_index(drop=True)
return ordered[['time_id']]
通过与真实市场数据进行比较,可以很容易地验证训练数据的 time-id 顺序恢复的正确性。通过这样做,我们知道训练数据的时间段是 2020/1/1~2021/3/31。
左图:通过 t-SNE 恢复的股价 右图:通过 yfinance 检索的实际股价 (2020-01-01~2021-03-31)
另一方面,对于测试数据,我没有在特征和模型中直接使用 time-id 信息,因为无法保证 t-SNE 能正确排序 time-id。然而,即使不能直接用于特征,time-id 的顺序也可以有多种用途。
- 时间序列交叉验证。既然我们知道了时间戳的正确顺序,我们就可以像处理正常的时间序列数据一样构建