感谢 Kaggle 和 Sartorius 举办了这场有趣的比赛。我也要感谢我的队友 @tanakar、@tereka 和 @ren4yu。我从他们身上学到了很多。
我们的实验基于 CBNetV2 代码库。
在下文中,我想对我们的解决方案进行总结。
总体概述
我们的解决方案由三部分组成:分类部分、实例分割部分、后处理部分。每种细胞类型都有不同的实例分割模型和后处理方式,因此分类是必要的。
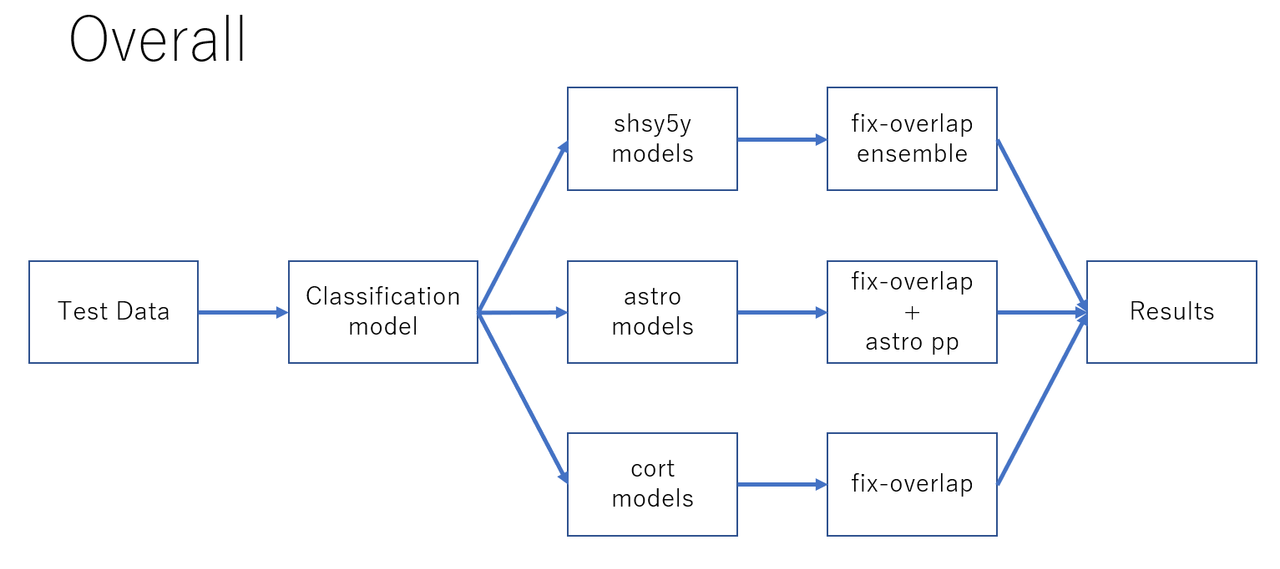
分类
我们使用 3类 CBNet DBS Cascade-RCNN (num_classes=3) 作为分类模型。对于给定的图像,该模型将其分类为检测到的细胞数量最多的细胞类型。
该模型首先使用 LIVE_CELL (num_classes=1) 进行预训练,然后使用比赛的训练数据 (num_classes=3) 进行微调。
我在半监督数据上测试了这个模型,它能够完美地对它们进行分类。
实例分割
我们为 shsy5y、astro 和 cort 各准备了至少一个模型。这些模型在不同的设置和不同的数据下进行了训练。
伪标签
对于所有细胞类型,在半监督数据上进行伪标签处理都提高了 CV 和 LB 分数。
由于训练数据数量较少,当仅使用训练数据时,使用三种类型的细胞效果更好。然而,由于半监督数据数量庞大,我们能够针对每种细胞类型更改所使用的数据。
伪标签详情用于伪标签的模型
数据:live_cell → train (所有细胞类型)
模型:3种类型的 1类 CBNet DBS Cascade-RCNN
我们根据目标细胞类型更改了 MMdet 配置文件。
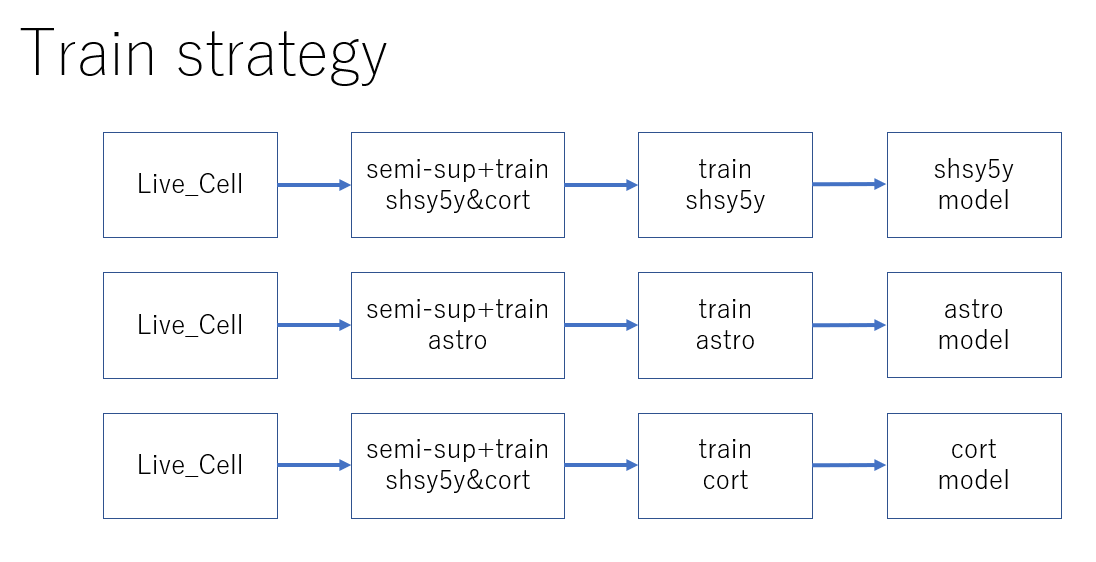
shsy5y 模型
数据1:live_cell → train (所有细胞类型)
模型1:CBNet DBS Cascade-RCNN
数据2:live_cell → semi-sup+train (shsy5y & cort) → train (shsy5y)
模型2:CBNet DBS Cascade-RCNN
shsy5y 和 cort 的细胞数量差异很大,但单个细胞很相似,因此在使用半监督数据时,我们将这两者作为训练数据使用。
astro 模型
数据:live_cell → semi-sup+train (astro) → train (astro)
由于 astro 的形状和大小与其他细胞非常不同,我们通过仅使用 astro 数据作为训练数据来提高分数。
对于 astro,我只使用了一个模型,因为集成效果不佳。
cort 模型
数据:live_cell → semi-sup+train (shsy5y & cort) → train (cort)
模型:2 x HTC resnext64x4d, 2 x CBNet DBS Cascade-RCNN
这四个模型使用下面的方法组合成了一个模型。
集成检测模型
<a href