第9名方案:拉普拉斯分布噪声似然优化
[更新 21/11/8] 我发现了一篇相关论文:Estimating the mean and variance of the target probability distribution(估计目标概率分布的均值和方差)
恭喜获奖者!也感谢主办方组织这次比赛。
我是原田实验室的一名硕士一年级学生。
该方案主要基于 nakama 的 notebook。主要的改动如下:
- 将 L1 Loss 改为似然损失(Likelihood Loss)(20个模型集成在 Public LB 上得分为 0.1095)(10折交叉验证 & 全部使用 10 个随机种子)
- 利用测试数据的伪标签(Public LB 得分为 0.1068)
接下来,我们将讨论第一点,即假设误差服从拉普拉斯分布,最小化 L1 范数。
利用拉普拉斯分布进行优化
首先,通常的 L1 损失等价于假设每个时间步的误差分布服从等变拉普拉斯分布时的似然最大化。
$$ p(x) = \frac{1}{2b}\exp{(-\frac{|x - \mu|}{b})} $$
$$ L_{1} = | x - \mu | $$
$$ L_{laplace} = - \log{p(x)}= \frac{|x - \mu|}{b} - \log{\frac{1}{2b}} $$
那么:
$$ \frac{\partial}{\partial x}L_{1} = const. \frac{\partial}{\partial x}L_{laplace} $$
对于这组数据,正如一些 notebook 中指出的,增加训练数据能提高 CV 分数。这可能暗示了模型容易过拟合。
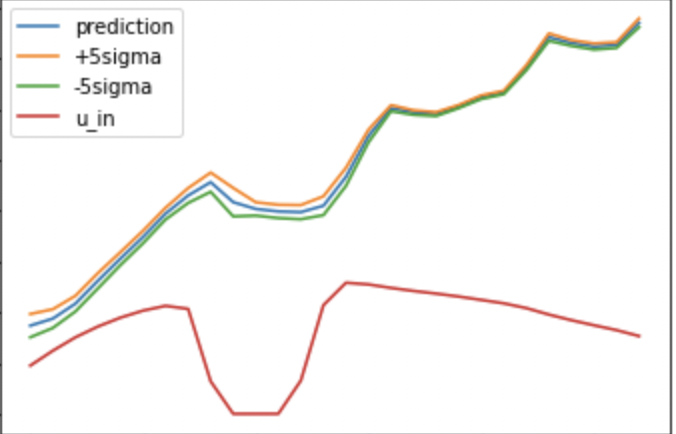
我认为这可能是因为我们假设误差的方差是相等的,也就是说,在某些时刻可能比其他时刻更难准确预测。
所以我假设每个时刻的方差是不同的。因此,我决定让模型不仅输出预测值 x,还输出预测方差 b。最终的损失函数为:
\begin{align} L_{laplace} &= \Sigma_{i=0}^{80} - \log{p_{i}(x)} \\ &= \Sigma_{i=0}^{80} - \log{(\frac{1}{2b_{i}}\exp{(-\frac{|x_{i} - y_{i}|}{b_{i}})})} \end{align}
这个损失函数让分数提高了 0.01 以上。
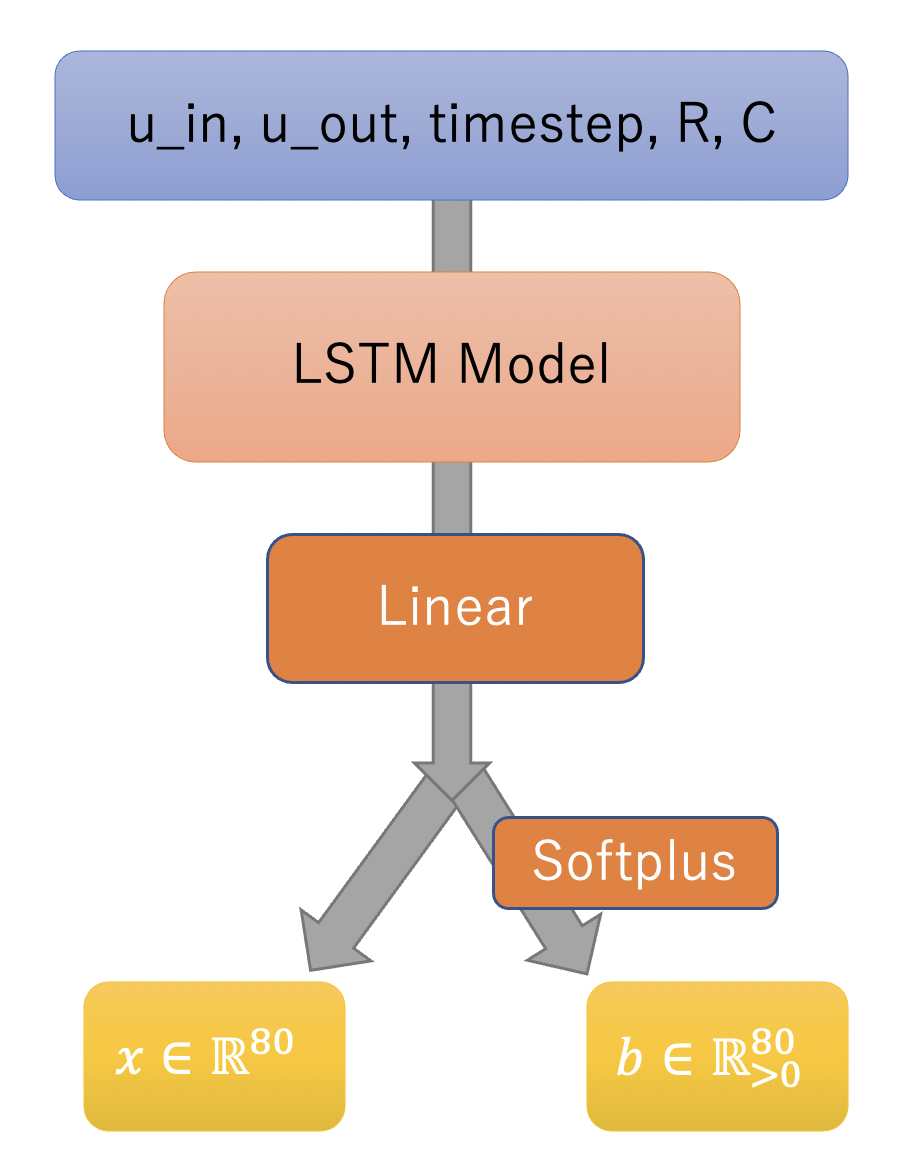
def masked_laplace(self, outputs, labels):
mask = labels['mask']
y = labels['label'][mask]
x = outputs[...,0][mask]
b = outputs[...,1][mask]
p = 1 / (2*b) * (- (x - y).abs() / b).exp()
loss = - torch.log(p + 1e-12)
return loss.mean()
参数设置如下:
Optimizer: AdamW
lr: 5e-3
Scheduler: MultiStep(gamma 0.1)
Iteration: 550,000(steps at 400,000 / 500,000)
batchsize: 256
gradient norm: 50
model(based on nakama's notebook)
hiddensize: 128
num_layers: 3
我在最后两周花时间做数据增强和寻找泄露,但没能提高分数。