第20名方案:模型与多任务学习
大家好!
首先,我要感谢我的队友 @fissium 和主办方!同时,祝贺所有获胜者,也感谢所有参赛者的辛勤付出!
我们的解决方案主要集中在两个部分:
- 深度学习架构
多任务学习,这使我们能够更稳定地训练模型
数据预处理
我们在开发预处理方面没有投入太多精力。公开可用的预处理方法对我们来说已经足够好了!
所以,让我们进入下一章 : )
模型
架构
我们总共开发了3种类型的架构:
- WaveNet风格模块 + bi-LSTM/GRU
- WaveNet风格模块 + Transformer Encoder + bi-LSTM/GRU
- WaveNet风格模块 + Transformer Encoder + Densely-Connected bi-LSTM
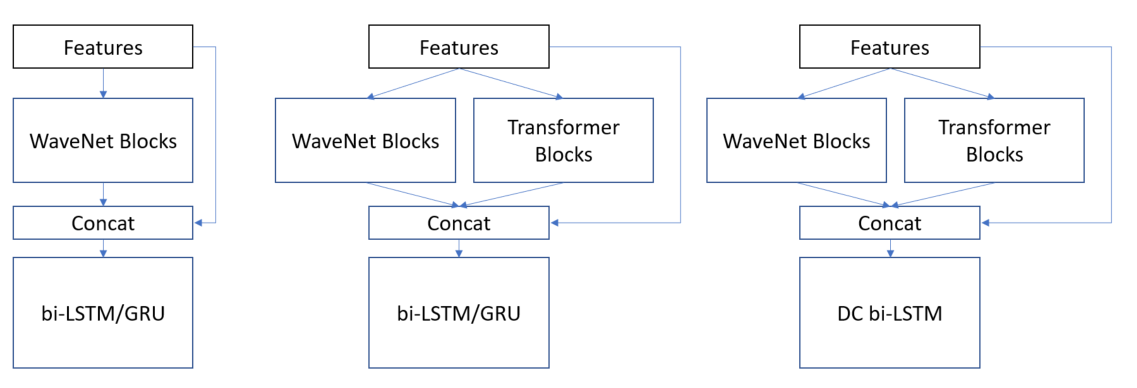
我们使用 CNN 和 Transformer 模块对特征进行编码,然后将其输入 bi-LSTM 层。
第二个模型(WaveNet风格模块 + Transformer Encoder + bi-LSTM/GRU)在我们的模型中获得了最好的 CV 分数。
实际上,我们无法将这些模型作为单模型提交,因为开发和训练是在比赛结束前的最后几天完成的。但是,根据 CV 分数推测(在我们的案例中,CV 和 LB 分数之间通常有 0.02 的差距),分数如下。
这是 CV/LB 表格。实际上,我们无法将这些模型作为单模型提交,因为开发和训练是在比赛结束前的最后几天完成的。但是,根据 CV 分数推测(在我们的案例中,CV 和 LB 分数之间通常有 0.02 的差距),也许我们可以猜测 LB 分数 : )
- 无伪标签,15折(分层),无后处理,相同种子。
| 模型 | CV | LB |
|---|---|---|
| WaveNet风格模块 + bi-LSTM/GRU | 0.13914 | 0.1186 |
| WaveNet风格模块 + Transformer Encoder + bi-LSTM/GRU | 0.136130 | 0.1160 (推测) |
| WaveNet风格模块 + Transformer Encoder + Densely-Connected bi-LSTM | 0.137117 | 0.1170 (推测) |
- 有伪标签,15折(分层),无后处理,相同种子。
| 模型 | cv | lb |
|---|---|---|
| WaveNet + bi-LSTM/GRU | 0.110575 | 0.1147 |
| WaveNet + TRFM + bi-LSTM/GRU | 0.107606 | ? |
| WaveNet + TRFM + DC bi-LSTM | 0.110126 | ? |
% 基于 WaveNet + bi-LSTM/GRU 有 3 种模型变体。发布的是基线版本。
% 无伪标签和有伪标签实验之间存在验证集不匹配的情况。
多任务学习
在比赛初期,我发现使用 delta pressure(压力差)作为辅助损失可以提高 CV/LB 分数(提升约 +0.01 ~ 0.015)。
同样,使用 delta of delta pressure(双重压力差)作为辅助损失也能使 CV/LB 分数提升约 +0.002 ~ 3。
df['delta_pressure'] = (df['pressure'] - df.groupby('breath_id')['pressure