我在九月表格竞赛中获得第9名的解决方案
各位 Kaggle 的朋友们好,
继“30天机器学习”竞赛之后,这是我第一次参加分类问题的竞赛。我想快速总结一下我在这次比赛中所做的工作,包括那些有效的方法和无效的尝试。
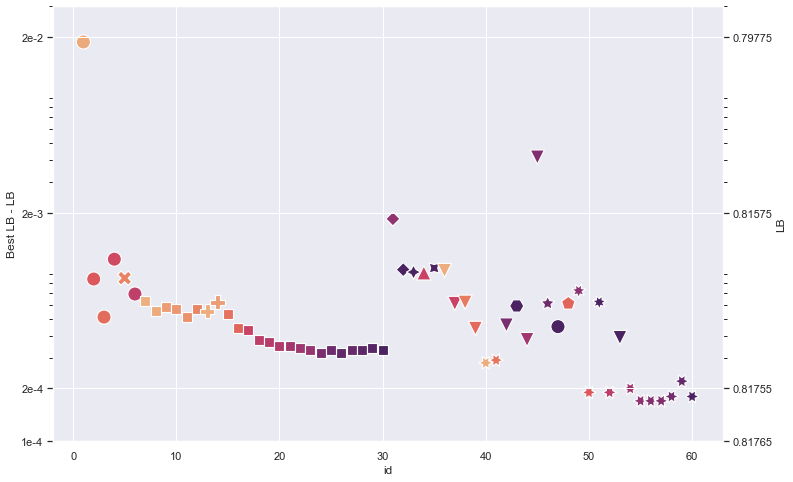
我的分数演变与比赛最佳分数的对比
作为直观辅助,这里展示了我得分在 Private LB(私有排行榜)上的演变。确切地说,我绘制了比赛最佳分数(来自 @pourchot)与我分数之间的差异,全部采用对数刻度,以便更好地展示模型改进的缓慢历程(符号对应不同的 notebook 即不同的方法,颜色对应 notebook 的版本):
初始模型
比赛开始后不久,@prikshitsingla 发现一行中的 NaN(缺失值)数量是预测目标的一个好特征,事实上,这已被证明与目标值相关(帖子)。这使我的 AUC 分数成功突破了 0.8。令人惊叹。对数据的良好理解确实对建立模型至关重要。我在这次比赛中没做太多的 EDA(探索性数据分析),希望以后能在这方面有所改进。
接着像往常一样,我开始尝试 XGBoost 和 LightGBM 分类器,并使用 Optuna 调整超参数。由于数据文件很大,我使用随机抽样处理了全部数据的 20%。这让我能够快速运行 Optuna,进行 5 折交叉验证,并迅速锁定了一组效果不错的超参数组合。不幸的是,进一步的 Optuna 搜索一无所获,没有提高 Public LB 分数。总而言之,我在发掘优秀模型方面并不太成功……所以我开始参考他人的工作并使用堆叠。
堆叠
然后开始了堆叠部分。@abhishek22211 在他的帖子中很好地解释了其原理。基本上,需要在许多所谓的 Level-0 模型上使用交叉验证,然后使用它们的袋外预测来训练 Level-1 元模型进行最终预测。
感谢 @vishwas21(notebook)、@manabendrarout(notebook)和 @mlanhenke(notebook),我得以在我的 L0 层总共收集了 34 个模型。
在堆叠方面,非常有效的方法是:
- 使用 LinearRegression 而不是逻辑回归作为 L1 元模型。
- 重用 L1 模型和 L0 模型的结果作为 L2 元模型的输入,L2 元模型同样是 LinearRegression。
我还基于一行中的 NaN 数量做了一些目标编码,并使用不同的种子复制了一些模型,这似乎很有效。还要感谢 @edrickkesuma 关于 power blending 的精彩帖子,我学到了一些新东西!
对堆叠分数没有帮助的尝试:
- 使用 XGBoost 或 LightGBM 分类器作为元模型,并在 L1 层使用 Optuna 调整它们。
- 仅仅为了多样性,盲目地在 L0 层添加分数平庸的模型(如 RF、LogisticRegression 等)。
- 伪标签(帖子)。
在此之后,我大约完成了一半的攀升之路,在 Public LB 上大约处于第 30 位。
“单模型投票”与“全量拟合”
然后感谢 @martynovandrey 的帖子,我开始复制来自 @hiro5299834(notebook)、@ivankontic(<a href="https://www.kaggle.com/ivankontic/004