第7名解决方案
首先,我要感谢主办方组织了如此激动人心的比赛。我从以前从未处理过的具有挑战性的任务中学到了很多,主办方在讨论区中的许多善意贡献也对我帮助很大。
方案概述
我们的团队很早就放弃了通过 HPA-Cell-Segmentation 改进分割掩码,而是集中精力提高每个细胞的多标签分类精度。
我们主要尝试了以下两种方法:
- 利用图像级分类器的类激活图(CAM)预测每个细胞,这通常用于弱监督语义分割。
- 裁剪每个细胞的图像并逐一预测。
在方法1中,图像级标签更干净(与将其用作细胞级标签相比),因此更容易训练分类器。另一方面,它对于具有高 SCV(单细胞变体)的图像有缺点,因为单个细胞的预测很容易受到邻近细胞的影响。在方法2中,简单地使用图像级标签很难取得好成绩。但由于预测是针对每个细胞单独进行的,因此受 SVC 的影响较小。为了利用这两种互补方法的优势,我们创建了包含这两种方法的模型并将它们作为集成模型使用。
训练流程如下图所示。
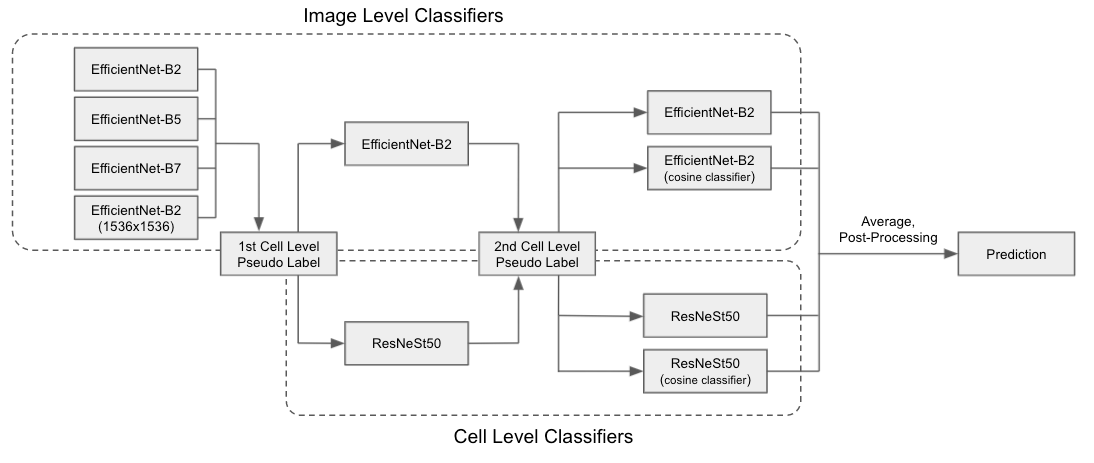
我们将离线伪学习过程重复了两次,使用来自多个模型集成的伪标签和 TTA 训练新模型。所有伪标签都是应用 sigmoid 函数后的软标签。所有集成均通过简单平均完成,TTA 使用了所有 D4 增强。图像级分类器使用 768 x 768 的图像进行训练(1536 的除外),细胞级分类器使用 192 x 192 的图像进行训练。余弦分类器使用特征图与线性层之间的余弦相似度,而不是特征图的线性变换(我们遵循 https://arxiv.org/abs/2103.16370 的公式 3)。
数据
我们使用了本次比赛的所有训练数据和公开的 HPA 数据。
验证策略
为了划分数据,我们使用了来自 iterative-stratification 的 MultilabelStratifiedKFold,分为5折。我们主要监控了图像级 mAP、Focal loss 和二元交叉熵,但我们找不到任何与 Public LB 相关的指标,因此我们依赖 Public LB 的反馈。
图像级分类器
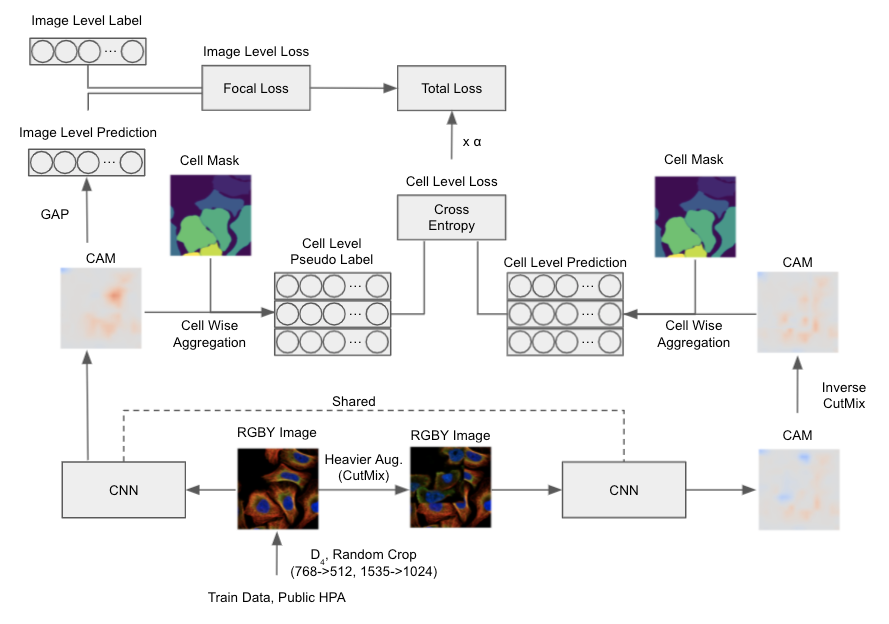
对于图像级分类器,除了图像级 Focal loss 外,我们还使用了一致性损失,使得弱增强下的细胞级预测与强增强下的细胞级预测相匹配。对于细胞级预测,我们使用了每个细胞所占区域中 CAM 的平均值(由于 CAM 的通道数很少,即使使用 scatter_add 这样的操作也相当快)。一致性损失的想法基于 PseudoSeg 和 PuzzleCAM(我认为 PuzzleCAM 中的重建损失可以被视为使用 Cutout 变体的一致性损失)。
我们主要使用 EfficientNet-B2 作为图像级分类器。这是因为使用其他架构(我们尝试了 ResNet 和 ResNeSt)或更大的 EfficientNet 会提高本地图像级 mAP,但不会提高 Public LB。(这种选择可能导致 Public LB 过拟合)。
当使用来自其他模型集成的伪标签时,图中的“细胞级伪标签”被集成的伪标签替换。
细胞级分类器
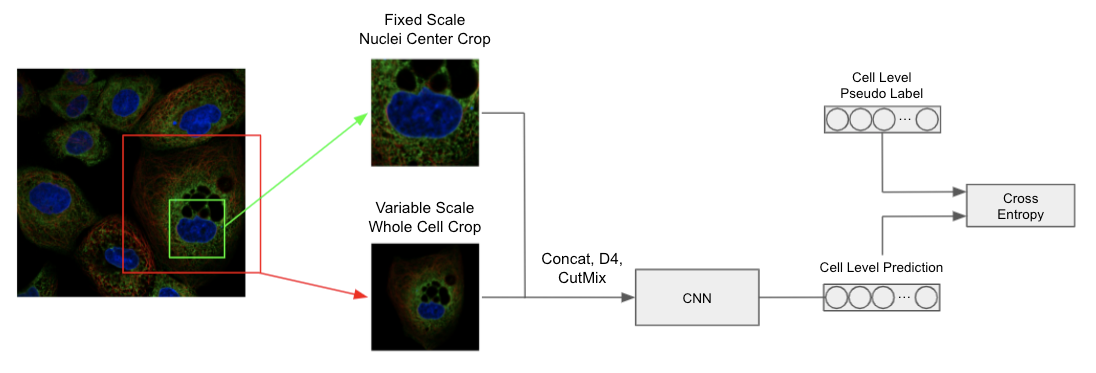
对于细胞级分类器,为了在分辨率较低的情况下将整个细胞的形状和细胞的大小输入 CNN,我们将固定比例的、以细胞核为中心的裁剪图像和可变比例的、全细胞裁剪图像连接起来输入 CNN。我们没有使用仅用图像级标签训练的模型,因为效果不好。
后处理
来自 <a href="https://www.kaggle