第43名:基于正例-未标记学习的解决方案
恭喜获奖者,也感谢所有的参赛者和伟大的主办方!🎉
我们是东京大学原田实验室的成员。
这场比赛非常有趣,因为必须在弱监督标签下进行分类。
我认为即使是分数不高的解决方案也值得公开。
“挖掘之后说‘这里什么都没有’也是很重要的。”
我将分享我们基于正例-未标记学习的解决方案。
概述
- 将图像切割成细胞,将标签视为负例-未标记,然后优化AUC。
- 使用Sigmoid优化AUC很难,分数提升不够。
- 将图像视为独立同分布样本可能导致损失函数不够紧凑。
我们是同一个实验室的成员。我们参加这次比赛是为了寻找硕士课程的研究主题。m0ka负责图像级分类器解决方案,我研究了图像级分类器解决方案。考虑到公共排行榜的分数,我们决定使用图像级分类器作为我们的最终模型。
流程
- 10个ResNet34模型的集成。
- 在负例-未标记标签设置下的AUC优化。
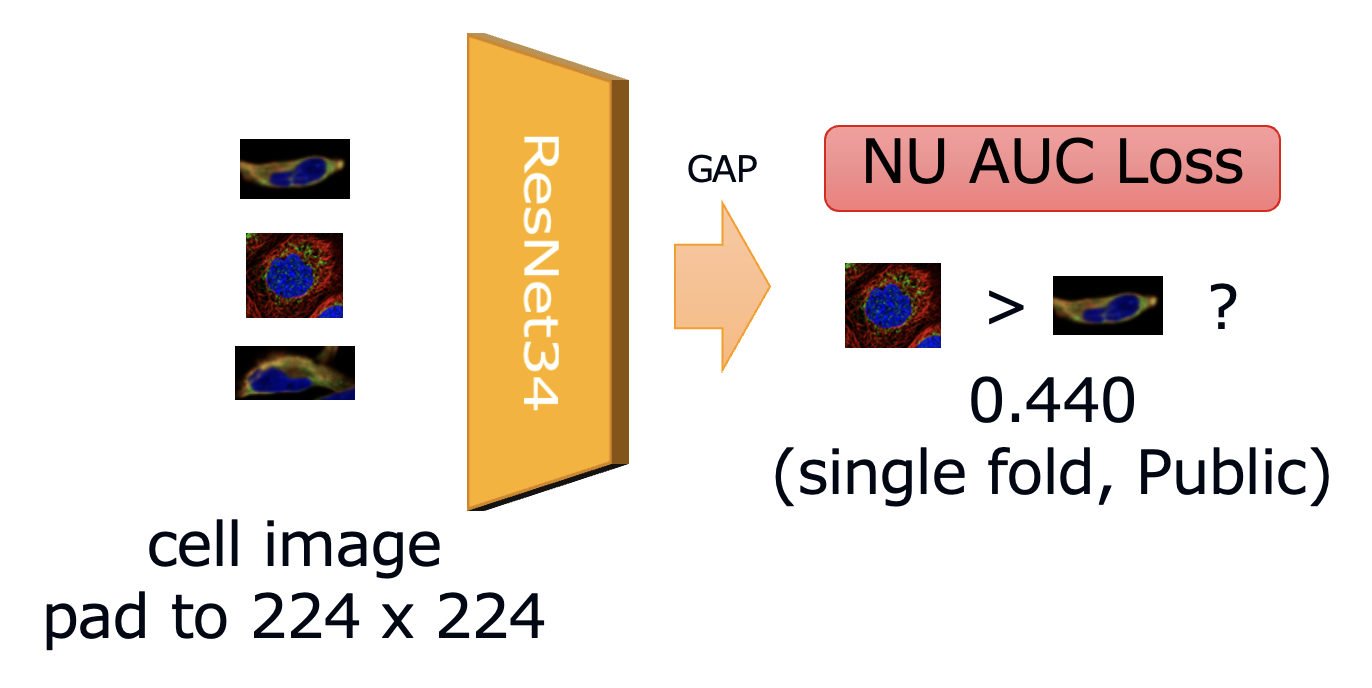
目的
- 在没有标签噪声的情况下训练模型。
- 优化以最小化PR-AUC。
- 可以在标签噪声下验证模型。
我们有图像级的标签,但没有细胞级的标签。如果在这种情况下对细胞图像进行分类,我们将受到错误添加标签的困扰。而且即使在训练之后,我们也无法用这些有噪声的标签验证我们的模型。
即使在这种情况下,如果我们使用统计机器学习技术,我们也可以在没有这种偏差的情况下训练我们的模型。下面我将解释我们的解决方案。
假设与设置
- 将标签视为负例-未标记。
让我们考虑带有0-17类标签的细胞图像。
因为这些标签是添加到原始整体图像上的,所以有许多假阳性添加的标签。那么我们可以假设:
- 添加的标签实际上可能是阴性的。
- 未添加的标签总是阴性的。
从这个角度来看,我们可以将本次比赛的设置视为负例-未标记设置。负例标签总是负例,正例标签总是正例。
[编辑] 比赛结束后,我发现了一篇论文 [Peng and Zhang, 2019] 也处理了这种设置😅。然而,该方法需要类先验 P(y_{k}) 进行无偏估计,而我们无法获知。为了解决这个问题并优化AUC而不是贝叶斯风险,我们引入了基于AUC的解决方案。
AUC的优化
- 优化AUC以提高PR-AUC。
- 我们不需要知道类先验。
在正常设置中,mAP通过优化BCE Loss等损失来增强。然而,由于标签是有噪声的,这种损失可能很难优化。
相反,我决定优化类似于ROC-AUC的AUC。
将样本x的类别i得分输出记为fx。P是正样本的概率,N是负样本的概率。类别i的AUC计算如下:
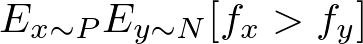
我在这里不写精确的理论,但在PU学习设置中,已知:
- 使用满足 l(x) + l(-x) = const. 的对称损失可以减少由假阳性标签引起的偏差。
结合AUC优化和对称损失导出了目标函数,我们不需要使用类先验。我们可以将其记为:
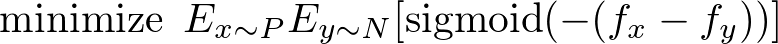
优点与缺点
- 优点
- 我们可以使用全部图像!
- 只有1个标签的图像数量有限。
- LB(
- 我们可以使用全部图像!