Public 16th / Private 10th 解决方案
感谢所有参赛者的辛勤付出。我是这个领域的新手,在前50次提交左右只得到了大约0.7分。然而,通过学习过去类似的比赛和论文,我赢得了金牌!由于对推理时间和内存的严格限制,这次比赛也是我学习工程知识的好机会。
概览
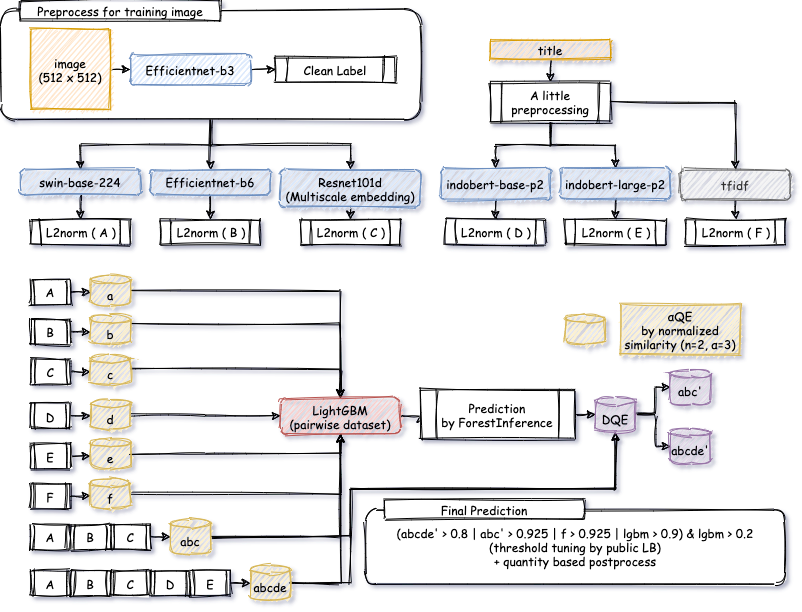
详细内容
图像模型
首先,我清理了标签,因为看起来几乎相同的图像在用于训练图像模型时可能会产生噪声。换句话说,我将高于一定相似度水平的标签重新标记为同一标签。
然后,我使用 ArcFace 训练了每个模型并提取了嵌入向量。
标题模型
在处理转义字符串后,我训练了 indobenchmark/indobert-base-p2、indobenchmark/indobert-large-p2 和 TFIDF。indobenchmark/indobert-base-p2 的效果优于 bert-base-uncased。
查询扩展
这次比赛保证每个产品会有不止一个标签。
因此,使用 n=2 和归一化相似度的 αQE 非常有效。
元模型
在训练了上述模型和 QE 之后,我通过成对数据集中的相似性特征训练了 lightGBM 模型。
然而,试图在内核上正常预测 LightGBM 非常耗时,所以我使用了 cuml 的 ForestInference 进行预测。那速度简直快得疯狂。
最后,我利用 LightGBM 的预测结果重新应用了 αQE(所谓的判别式 QE)。
结果证明,这个 DQE 并不是很有用。
阈值搜索
首先,我仅使用了 abcde' 嵌入向量的相似度,得分相对较低。(但是 abcde' 嵌入向量的 CV 很高)
所以,我探究了这个原因。在下图中,你可以看到 abcde'(cnn_bert_distance)的一些预测不如使用 abc'(cnn_all_distance)时那么确信。
我通过这种方式仔细观察散点图,结合了多个预测结果。
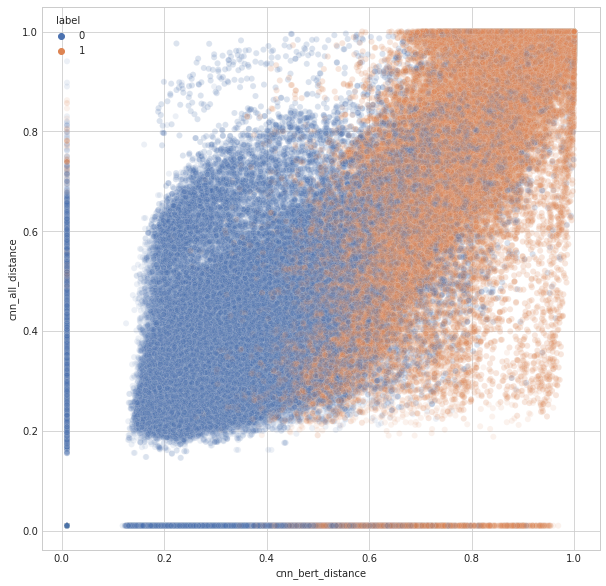
此外,通过本地实验,我确认在 Public 中调整阈值不会影响 Private 的结果,因此我们在 Public 中调整了阈值。
无效尝试
- 一些扩散技术。
- 基于注意力的查询扩展。
- 通过基于嵌入的成对数据集训练的 MLP。
- 无监督模型(如 CLIP)
- 带有三元组损失的 Arcface
延迟提交
我没有尝试,因为在大约一天前我想出使用 LightGBM 的主意后就没有时间了,但我仅使用 LightGBM 预测(lgbm > 0.8)获得了以下分数。所以,我只需要元模型。
