第11名方案
首先,我要感谢所有在这次比赛中分享知识和建议的人。我很高兴赢得了我的第一枚金牌。
我的解决方案详情如下。
训练
我微调了一个图像模型和两个BERT模型。
1. 图像模型
- 骨干模型:swin_base_patch4_window12_384 (来自 timm)
- 输入尺寸:384
- 损失函数:ArcFace (scale=34, margin=0.5)
- 全连接层(嵌入)维度:768
- 批次大小 = 12 x 2 累积(我在 Google Colab 上使用 AMP 进行训练)
- 训练轮数:11
- 优化器:Ranger
- 学习率调度器:骨干网络预热2个epoch从 7.5e-6 到 1e-4,余弦衰减至 1.5e-5,全连接层 x 2
- 数据增强:RandAugment(见下文)
from timm.data import create_transform
def get_train_transforms(input_size=384):
return create_transform(
input_size=input_size,
scale=(0.6, 1.0), # 默认值: (0.08, 1.0)
ratio=(1.0, 1.0), # 默认值: (3. / 4., 4. / 3.)
hflip=0.5,
vflip=0.5,
is_training=True,
color_jitter=0.1,
auto_augment='rand-m3-n1-mstd0.5-inc1',
re_prob=0.1, # RandomErasing 概率
re_mode='pixel', # ['const', 'rand', 'pixel']
re_count=1, # 每张图像擦除块的数量
)
2. BERT 模型
- 骨干模型1:sentence-transformers/paraphrase-xlm-r-multilingual-v1 (来自 Huggingface)
- 骨干模型2:cahya/distilbert-base-indonesian (来自 Huggingface)
- 损失函数:ArcFace (scale=30, margin=0.5)
- 全连接层(嵌入)维度:768
- 批次大小 = 16
- 训练轮数:xlm-r 为 7 轮,indonesian 为 8 轮
- 优化器:SAM with AdamW
- 学习率调度器:(与图像模型相同,除了 lr_min)
推理
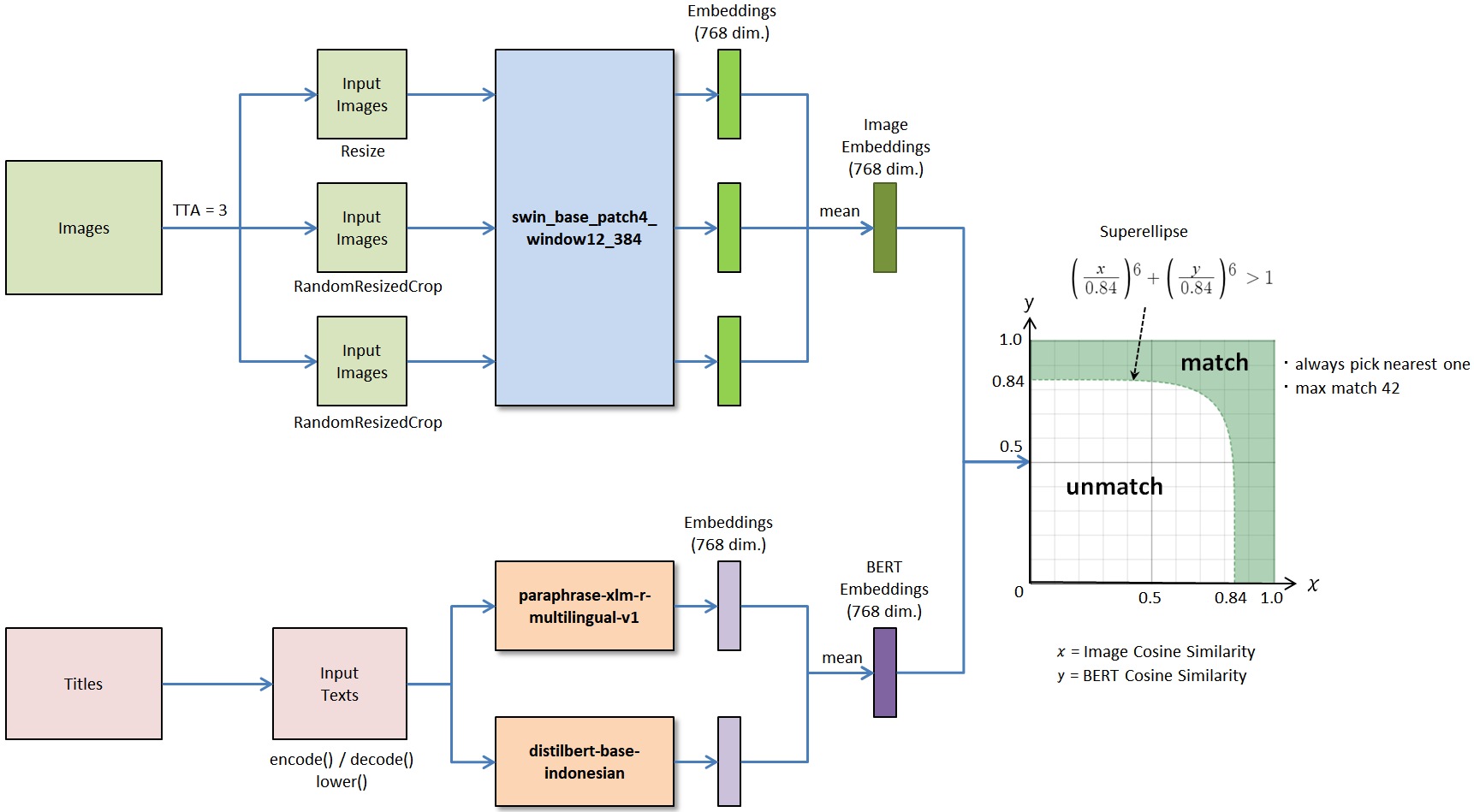
预测代码
def get_predictions(df, img_embeddings, bert_embeddings, img_threshold=0.84, bert_threshold=0.84, chunk=32, nearest_one=True, max_preds=42):
CTS = len(df) // chunk
if (len(df) % chunk) != 0:
CTS += 1
preds = []
for j in tqdm(range(CTS)):
a = j * chunk
b = min((j+1) * chunk, len(df))
img_cts = torch.matmul(img_embeddings, img_embeddings[a:b].T).T
bert_cts = torch.matmul(bert_embeddings, bert_embeddings[a:b].T).T
for k in range(b-a):
similarity = (img_cts[k,] / img_threshold) ** 6 + (bert_cts[k,] / bert_threshold) ** 6
sim_desc = torch.sort(similarity, descending=True)
IDX = sim_desc[1][sim_desc[0] > 1][:max_preds].cpu().detach().numpy()
o = df.iloc[IDX].posting_id.values
if (len(IDX) == 1) and nearest_one:
IDX = sim_desc[1][:2].cpu().detach().numpy()