第14名方案 - 图像文本决策边界
感谢 Kaggle 和 Shopee 举办了这场精彩的比赛。这是我最喜欢的比赛之一。这场比赛挑战我们构建图像模型、文本模型,并以前所未有的方式将所有内容结合起来。
RAPIDS TfidfVectorizer
我的解决方案始于 RAPIDS TfidfVectorizer 和 EfficientNetB0 384x384 图像模型,正如我在公开笔记本中所展示的那样。接下来,我使用了具有多语言预训练的 XLM-RoBERTa 进行集成,并集成了 EfficientNetB3 512x512 图像模型。
最佳公开笔记本 LB 0.730
我的公开笔记本得分为 LB 0.700。随后 @ragnar123 在此基础上增加了 ArcFace 和余弦距离阈值,将分数提升到了 LB 0.730。公开笔记本的决策逻辑如下:如果两个产品的图像余弦距离小于 0.3 或文本余弦距离小于 0.17,则判定为匹配:
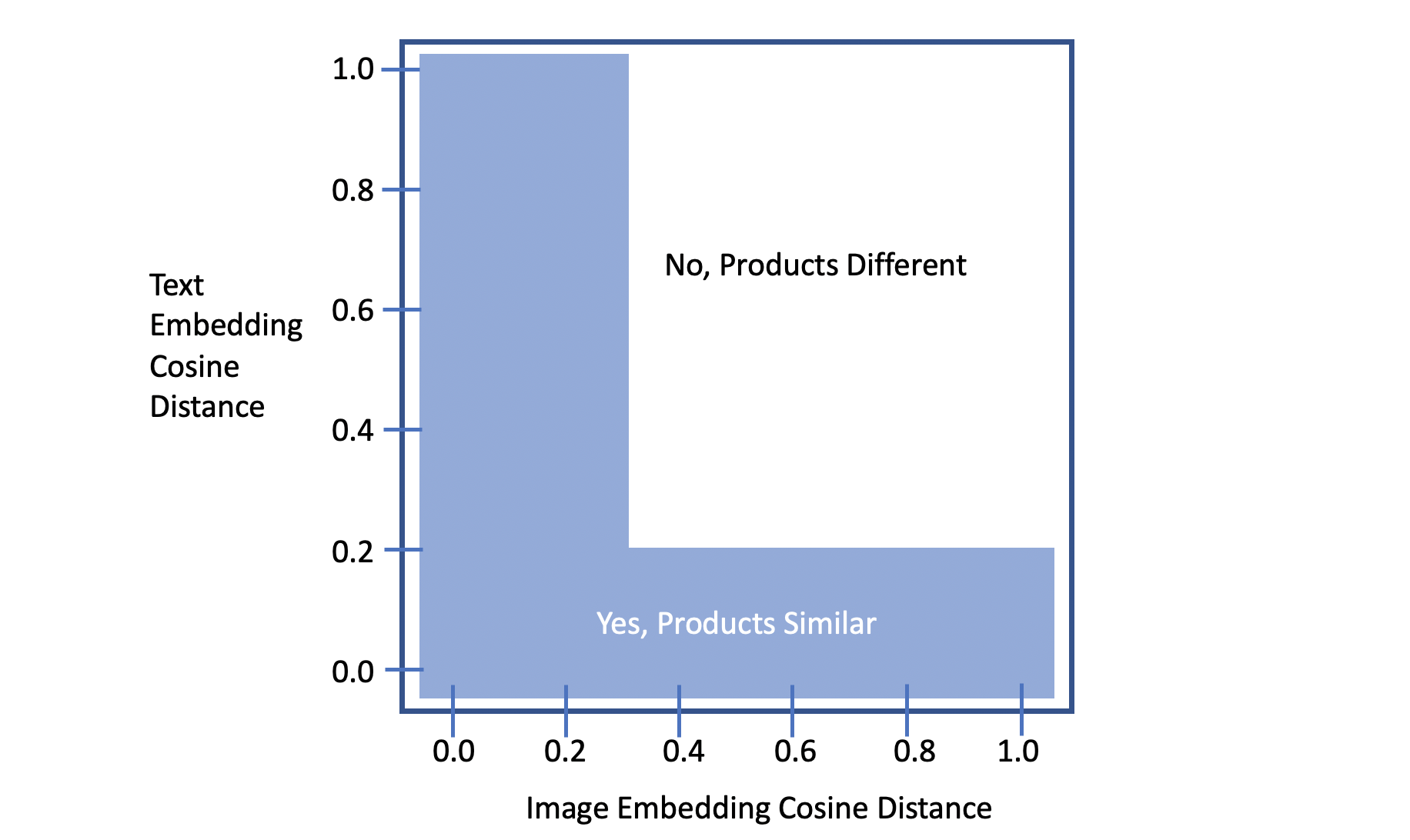
更好的决策边界 LB 0.750
请注意,上面的图表显示了一个简单的决策边界(由常数函数构成)。通过利用交叉验证(CV),我们可以根据图像余弦距离和文本余弦距离计算两个产品匹配的概率,并使用分段线性函数构建决策边界:
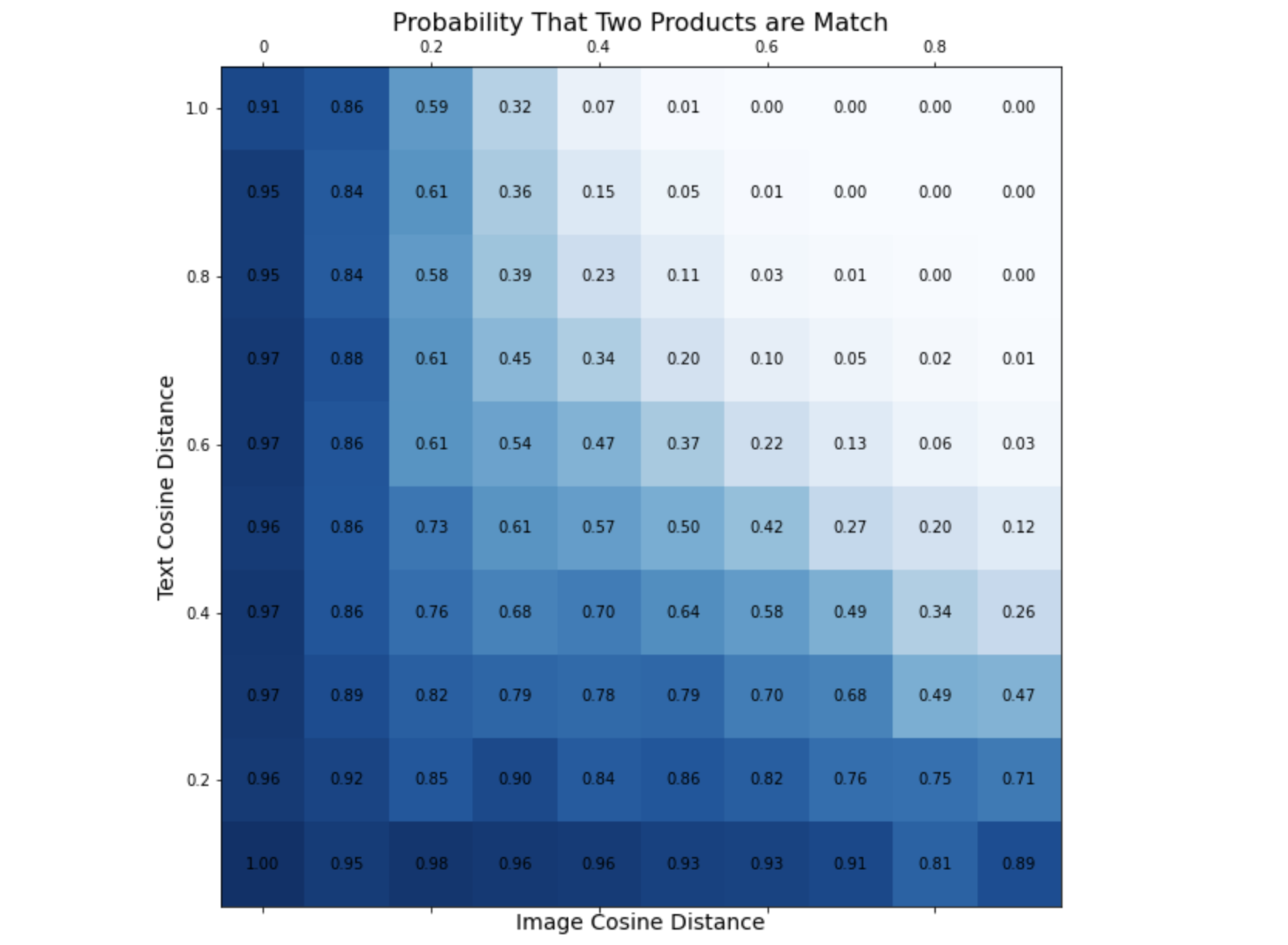
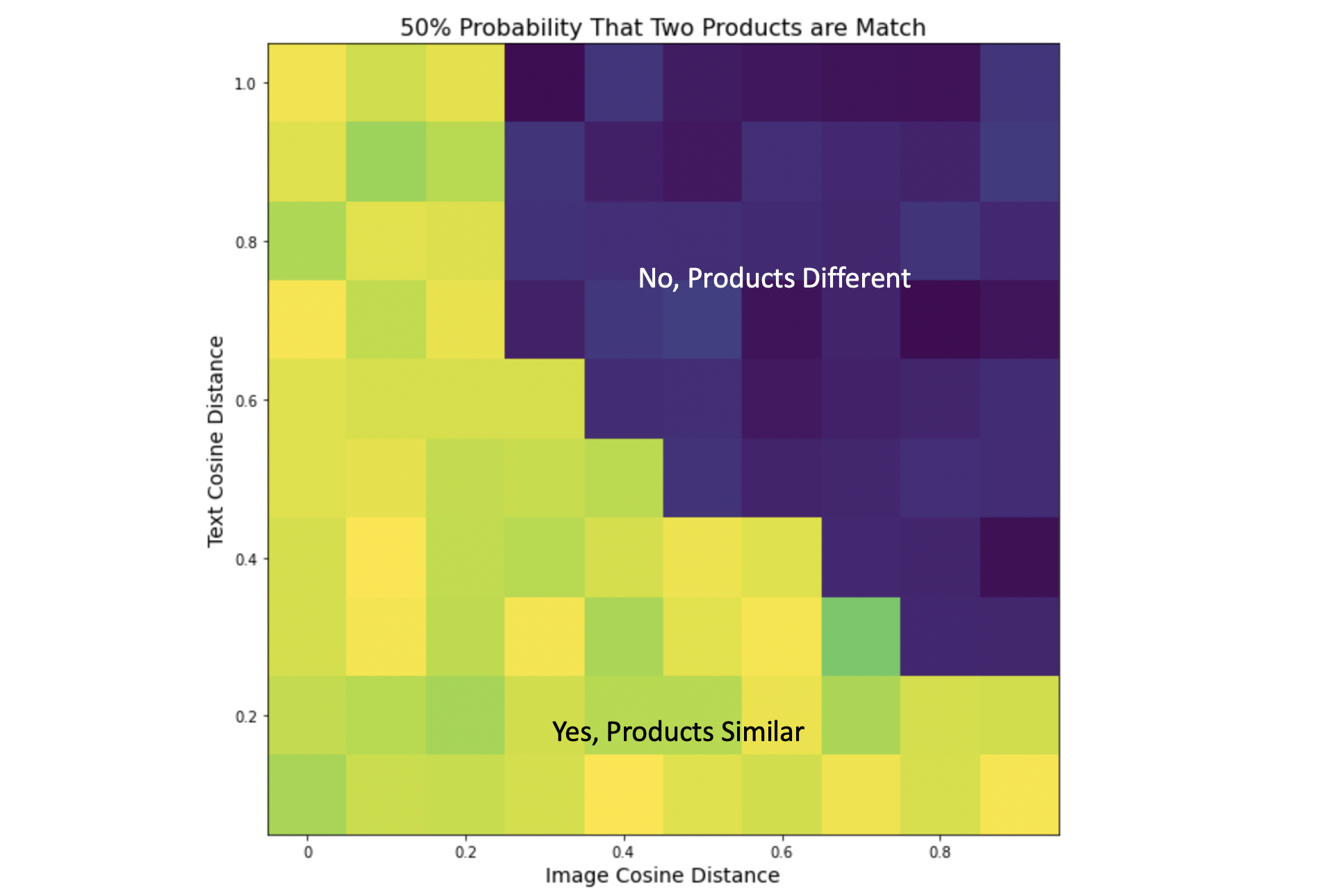
增加具有中等图像和文本相似度的匹配
从上面的图表中,我们可以看出应该比公开笔记本增加更多的匹配项。例如,如果两个产品的 图像余弦相似度 = 0.4 且 文本余弦相似度 = 0.4,我们应该认为它们是匹配。而在简单规则“图像 < 0.3 或 文本 < 0.17”下,这两个产品不会被判定为匹配。
示例代码
为了找到这些匹配,我们必须同时计算图像和文本的余弦距离。
# 归一化图像嵌入
s = np.sqrt(np.sum(np.multiply(image_embeddings,image_embeddings),axis=1))
image_embeddings = image_embeddings / np.expand_dims(s,axis=-1)
# 归一化文本嵌入
s = np.sqrt(np.sum(np.multiply(text_embeddings,text_embeddings),axis=1))
text_embeddings = text_embeddings / np.expand_dims(s,axis=-1)
pids = []
all_id = df.posting_id.values
# 分批计算距离
CT = int(np.ceil(len(df)/BATCH))
for k in range(CT):
a = k*BATCH
b = (k+1)*BATCH
b = min(len(df),b)
for j in range(b-a):
# 计算距离块
img = 1-image_embeddings.dot(image_embeddings[a:b,].T).T
txt = 1-text_embeddings.dot(text_embeddings[a:b,].T).T
# 决策边界
idx1 = np.where(img[j,] <0.3)[0]
idx2 = np.where(txt[j,]<0.17)[0]
idx3 = np.where( 0.62*img[j,] +txt[j,] <0.73)[0]
idx = np.concatenate([idx1,idx2,idx3])
idx = np.unique(idx)
pids.append( all_id[idx] )
# 预测
df['matches'] = pids
消除假阴性和假阳性 LB 0.770
上述决策边界将我们的 CV LB 提高到了 0.750。为了将 LB 提升到 0.770,我们需要采用五种额外的技术来消除假阴性和假阳性(这可以提高 F1 分数)。我将在解决方案的第二部分详细解释这些内容。
- 如果一个产品有 0 个匹配项,则缓慢扩大边界以找到 1 个匹配。(消除假阴性)。
- 如果一个产品与具有相同图像和/或相同文本的产品匹配,分析所有这些产品的匹配项,然后从当前产品中移除那些在“邻居的邻居”中出现频率不高的匹配项。(通过图分析消除假阳性)。
- 如果一个产品有一个匹配项,且该匹配项属于具有相同图像和/或相同文本的组,则决定包含整个聚类或移除整个聚类