第16名方案
感谢 Kaggle 和主办方提供了这个带有注释的非常有趣的比赛。这是一个很棒的团队合作,也请给 @syxuming、@fanwenping、@chanyanyuese 点赞。祝贺获胜者。
有趣的是,我们的 CV 分数比第一名还要高,但 LB 分数却更低 😂😂
太长不看版 (TLDR)
我们采用了一个简单的方法。这是基本的流程图:
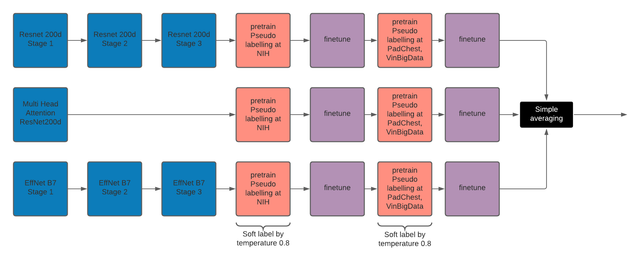
首先,我要感谢 @ammarali32 和 @ttahara 提供的起点和 Notebooks。@ttahara 的模型 CV 得分为 0.9767,LB 得分为 0.972(这是我们最好的单模),以及 @hengck23 提出的分阶段训练和 @yasufuminakama 提供的内核,随后在多个数据集上进行了微调。
CV 策略:我们大家都有几乎不同的 CV 划分,但算法相同。正如 @underwearfitting 所提议的那样。
模型
我们在提交中主要使用了 3 个主干网络和 4 个头部(但只实验了其中的 2 个):
- 主干网络
- Resnet200d
- EfficientNetB7
- Resnet50d
- 头部
- 多头注意力机制
- GeM
- 简单全局池化
- 自适应拼接池化
我们的策略
我们以 @hengck23 和 @ttahara 提出的想法作为开始。
我们像 @hengck23 那样将模型训练分为 3 个阶段。当我们用带有软标签(由第 3 阶段模型创建)的 GeM 训练 Resnet200d 时,是在我们自己的比赛数据集上进行的(我们认为这等同于知识蒸馏),并预训练了模型。这个模型显示 CV:0.97,LB:未测试。我们发现这种软标签帮助很大。我们继续在 NIH、PadChest、VinBigData 外部数据集上这样做。
这样做后的结果是:3 阶段模型 CV: 0.971/ PublicLB: 0.970/ PrivateLB: 0.971
多头注意力模型 CV: 0.9767/PublicLB: 0.970/ PrivateLB: 0.972
我们首先只对 NIH 进行软标签处理,预训练然后微调,接着对 PadChest 预训练并微调。我们将每个阶段模型训练为 5 折,而多阶段模型只训练 1 折。我们还使用了 @ammarali32 的公开高分权重,进行预训练和微调后加入集成。
集成
我们使用了简单的平均法。