第24名 - 3D fMRI 特征工程部分解决方案
在我看来,这是我迄今为止参加过的最好的比赛。我非常享受在这个主题上的工作,甚至可能想从事神经影像学相关的工作。我有一点失望,因为大多数团队甚至没有费心去查看 fMRI_train 和 fMRI_test。那些团队因为跳过数据集的这一部分而丢失了大量信息。我们的解决方案严重依赖 3D fMRI 数据,我正在更新我的数据分析 Kernel,其中包含此处描述的所有特征工程代码。这个 Kernel 中有更详细的解释。(创建这些特征需要 8 小时,所以 Kernel 仍在提交中)
3D 特征工程
特征基于不同目标组之间 fMRI 的差异。这些 fMRI 最大的差异在于活跃/非活跃区域的扩散和强度。我并排绘制了最年轻和最年长受试者的 53 个成分的 fMRI,并试图提取一些特征。其中一些特征有效,大多数则无效。
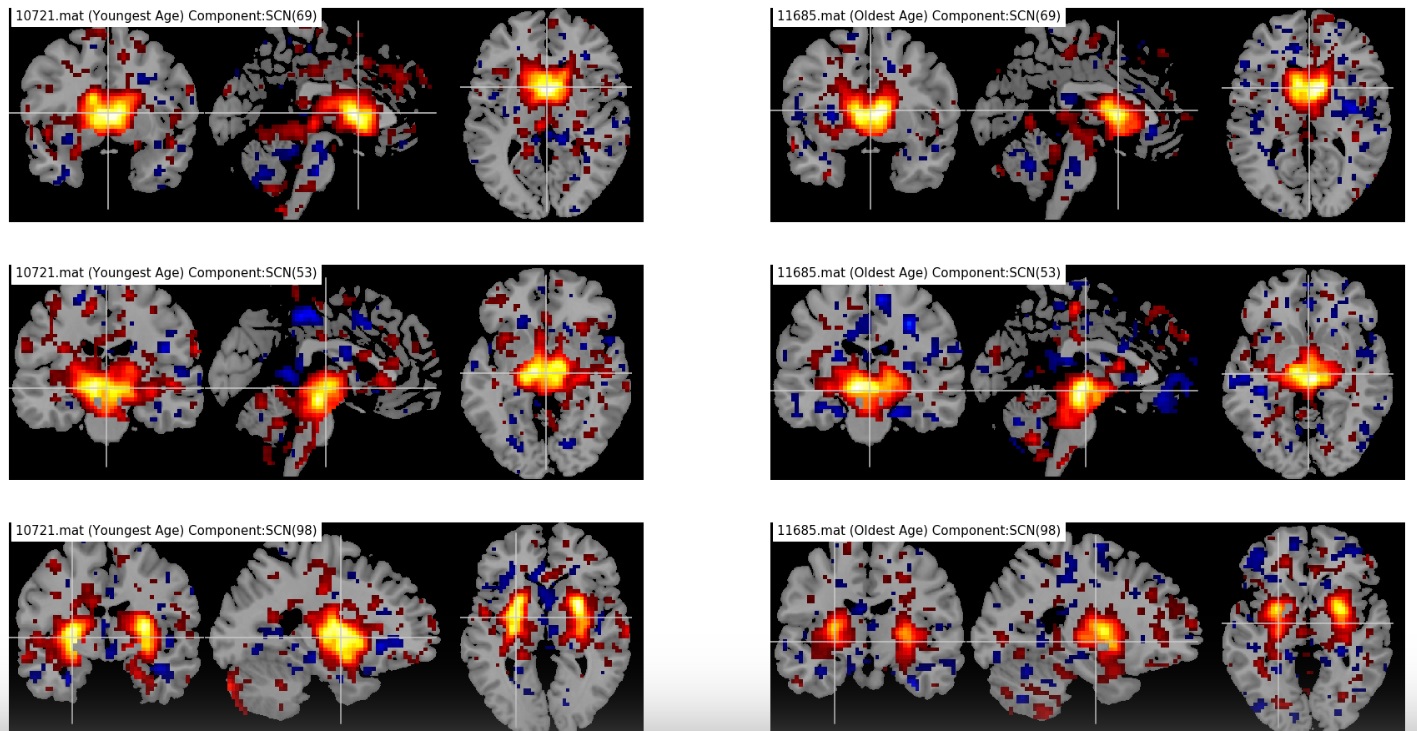
fMRI_train 和 fMRI_test 中的数据以 4 维空间表示:3 个空间维度和 1 个成分维度。在大多数情况下,第 4 维是时间,但在此数据集中它是 53 个不同的成分。将 3D 大脑掩码应用于 4D 样本,以便将它们转换为重构的 2D 表示。

fmri_mask = nl.image.load_img('../input/trends-assessment-prediction/fMRI_mask.nii')
sample = h5py.File(f'../input/trends-assessment-prediction/fMRI_train/10001.mat', 'r')['SM_feature'][()]
sample = np.moveaxis(sample, [0, 1, 2, 3], [0, 3, 2, 1])
masked_sample = sample[:, fmri_mask.get_data() == 1].astype(np.float32)这段代码加载 fMRI 掩码 (53, 63, 52) 和一个随机样本 (53, 52, 63, 53)。重新调整样本的轴 (53, 53, 63, 52) 并对其应用掩码。样本的最终形状是 (53, 58869),即 (n_components, n_voxels)。我们所有的特征都是在这个空间中提取的。同样的 fMRI 在被掩码处理后看起来是这样的。
在这个空间中创建的特征包括:
- 所有 53 个成分的偏度和峰度
np.diff(component)的偏度- 使用下面的代码行为 53 个成分创建活跃和非活跃区域,并提取它们的偏度和形状
active = component[component > component_mean + component_std]inactive = component[component < component_mean - component_std]
- 为 53 个成分创建活跃均值 / 非活跃均值和活跃标准差 / 非活跃标准差
- 为 53 个成分创建成分偏度 - 活跃偏度和成分偏度 - 非活跃偏度
- 使用下面的代码行为 53 个成分创建更多的活跃和非活跃区域,并提取它们的形状
more_active = component[component > component_mean + (2 * component_std)]more_inactive = component[component < component_mean - (2 * component_std)]
- 最终特征是将每个成分(信号)分为 15 个相等的部分,这对应于 3D 空间中的边界框。使用下面的代码行提取每个框的活跃区域形状和均值。我打算用这些特征捕捉固定位置的活跃区域扩散和强度。
box_count = 15
for b, box in enumerate(np.array_split(component, box_count)):
features[f'{icn_order[i]}_box{b}_mean'] = box.mean()
box_active = box[box > component_mean + component