第三名方案
恭喜所有的获奖者,感谢医学影像信息学学会 (SIIM)、美国放射学会 (ACR)、@RadiologyACR、胸部放射学会 (STR)、@thoracicrad 和 Kaggle 举办了这样一场有助于早期识别气胸并挽救生命的比赛。
挑战
- 图像尺寸相对较大。
- 外部数据集的质量不是很好,但充分利用它们可能会有所帮助。
解决方案
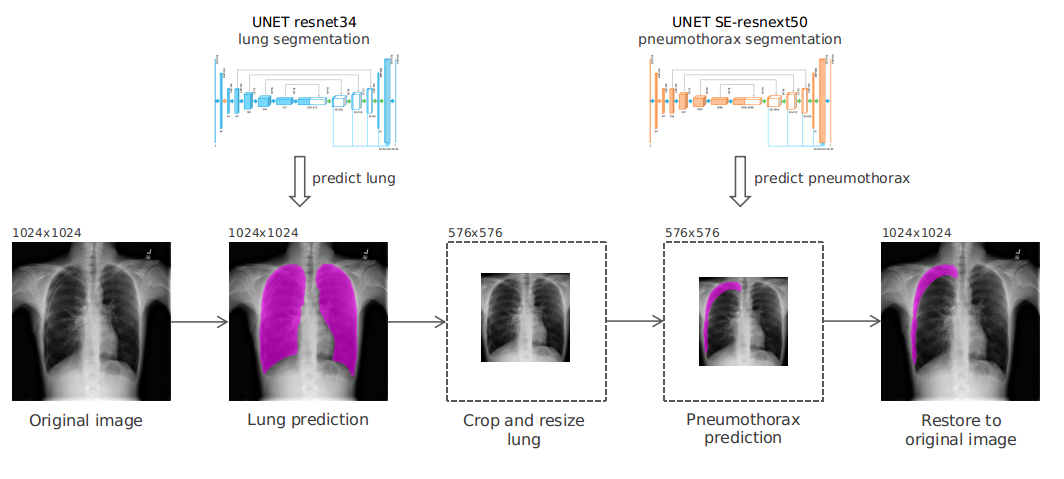
数据
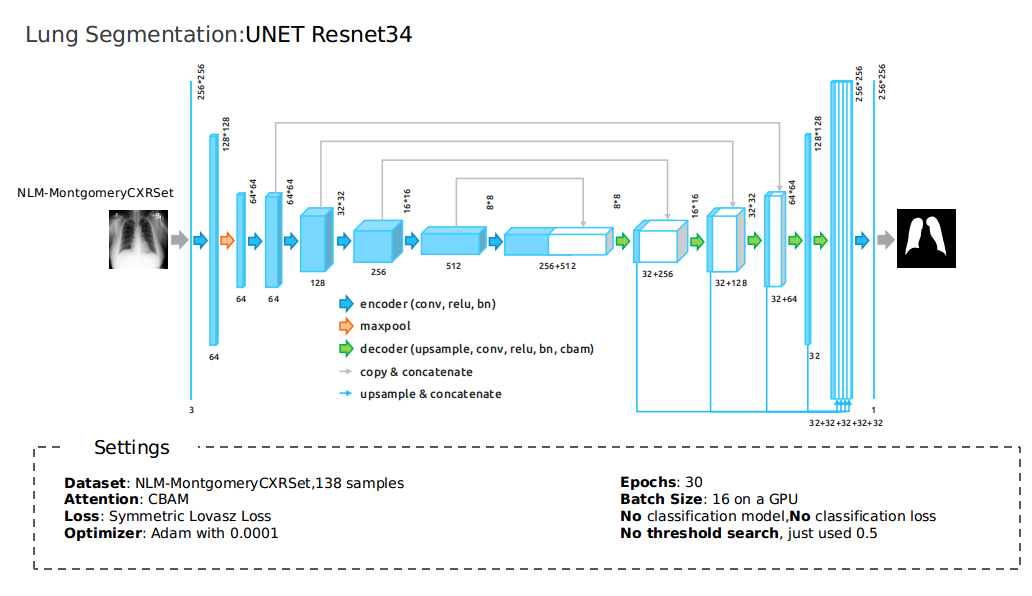
由于图像尺寸有点大,为了节省内存和计算资源,我首先训练了一个 UNET 模型从 1024x1024 的图像中预测肺部区域。我所有的模型都是基于裁剪后的肺部图像,576x576 的裁剪图像对于我的模型来说已经足够好了。
在深度学习任务中,更多的数据通常很重要,所以我尝试充分利用 CheXpert 和 NIH 数据集。在阅读了相关论文后,我发现我们不能直接使用它们,因为它们的标签不够准确。我想我可以使用伪标签,所以我使用了一个在比赛数据上训练的 resnet34 UNET 模型(公共 LB 分数 0.858)来预测 CheXpert 的阳性样本。在训练伪标签模型时,我选择了那些被我的模型预测为阳性的阳性样本。由于 DOGs-GAN 比赛推迟后时间有限,我没有预测 CheXpert 的阴性样本,只是将它们视为阴性。至于 NIH 数据集,我没有使用它们提供的标签,只相信我模型的预测。
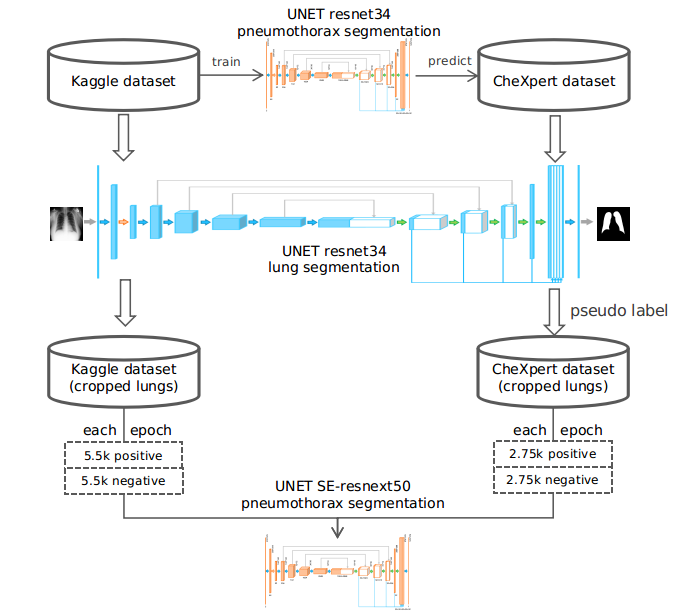
我保持了阳性和阴性样本的比例相等。在训练伪标签模型时,我将伪样本的比例保持在正常样本的 0.5。
模型
实验主要在基于 resnet34 和 SE-resnext50 主干的 UNET 上进行。我选择它们是因为 resnet34 足够轻量用于实验,而 SE-resnext50 对于这次比赛来说足够深。我没有足够的时间和资源来训练更大、更深的模型。
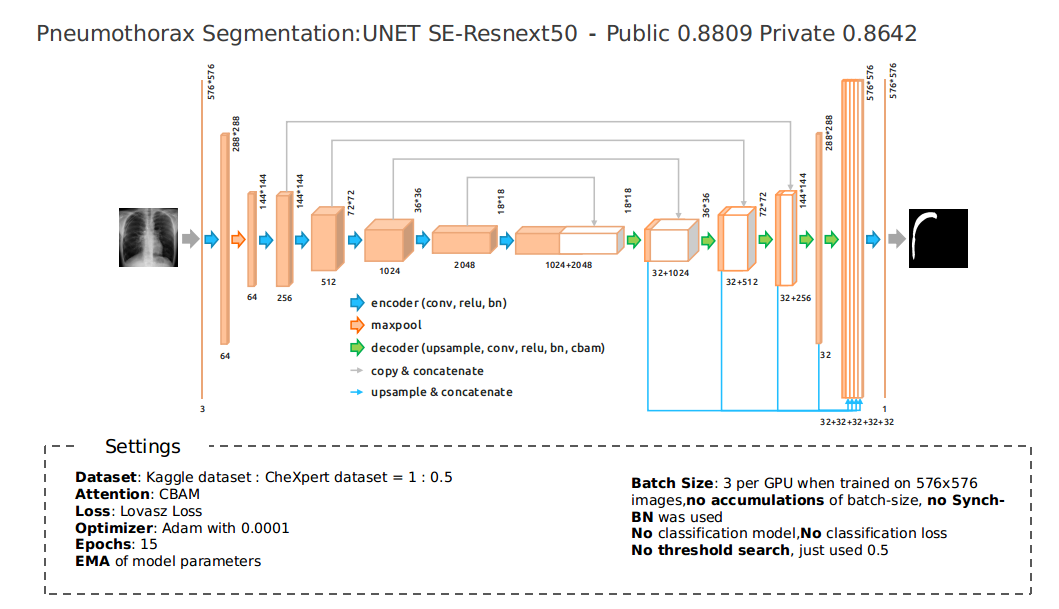
我的最终模型是 3 个 SE-Resnext50 模型:
- m1:704x704 图像,无伪标签
- m2:576x576 图像,带 CheXpert 伪标签
- m3:576x576 图像,带 CheXpert 和 NIH 伪标签
虽然我的最终提交是这三个模型的集成,但 m2 的 10 折交叉验证中的 3 折在公共 LB 上达到了 0.8809,在私人 LB 上达到了 0.8642。在这次比赛中,集成并没有带来太多的改进。
训练细节
- 注意力机制:CBAM
- 损失函数:Lovasz Loss,我也尝试了 Active Contour Loss,但没有带来本地 CV 分数的提升。
- 无分类模型,无分类损失:我认为像素级标签已经足够了,如果我们引入分类模型,很难在私有数据集上选择阈值。
- 无阈值搜索:仅使用了 0.5。
- 优化器:Adam,学习率 0.0001,训练期间不改变学习率。
- 轮次:15
- EMA:在第 6 轮后对模型参数进行指数移动平均。
- 批大小:在 576x576 图像上训练时,每个 GPU 3 张,因此使用 3 个 1080Ti 时批大小为 9。没有累积批大小,没有使用 Synch-BN。在 704x704 图像上每个 GPU 2 张。